並行性と分散システム
概要
競合・一貫性・再試行の世界を理解する
単一マシンでは簡単だったことが、複数スレッドや複数マシンになると急に難しくなります。このテキストでは、その難しさの正体を整理します。
この章で重視すること
- 並行性と分散を「速くなる技術」だけでなく「難しくなる技術」として見る
- 冪等性、再試行、順序づけを中心概念として押さえる
- 単一マシン感覚がどこで壊れるかを理解する
目次
並行性とは
複数の処理が重なって進むことです。
- 速くしたい
- 待ち時間を減らしたい
という理由で使います。
並列と並行は同じではない
ここは最初に整理しておくと楽です。
-
並行性(Concurrency): 複数の仕事が重なり合って進む考え方。時間軸上で重なるが、必ずしも同時実行ではない。タイムスライシングで 1 つの CPU でも実現。
-
並列性(Parallelism): 複数の仕事が物理的に同時に実行されること。複数コア、複数 CPU、SIMD、SMT(Simultaneous Multithreading)で実現。
具体例:
- シングルコア CPU で複数スレッド実行 → 並行性あり、並列性なし
- マルチコア CPU で複数スレッド実行 → 両方あり
- ベクトル演算(SIMD) → 並列性あり、従来の並行性の考え方とは異なる
1 コアでも並行性はありますし、複数コアなら並列性も使えます。重要なのは、処理が 1 本の直線ではなくなると、順序の不確定さ が入ってくることです。
なぜ難しくなるのか
単一スレッドでは「前の行が終わってから次の行」と考えやすいですが、並行処理では誰が先に進むかが毎回同じとは限りません。だからバグも「たまにだけ起こる」形になりやすいです。
スレッドモデルの概要
並行処理を実装する方式には複数ある:
カーネルスレッド(1:1 モデル)
- OS が管理するスレッド、各スレッドが独立したカーネル実行コンテキストを持つ
- 利点:真の並列性、ブロッキング I/O が容易
- 欠点:コンテキストスイッチのオーバーヘッド、メモリ使用量が多い(スレッドあたり数 MB)
- 例:Java Thread、Pthread、Windows Thread
ユーザースレッド(M:N モデル)
- アプリケーション層で管理、少数のカーネルスレッド上で多数のユーザースレッドを実行
- 利点:軽量、コンテキストスイッチが高速
- 欠点:1 つのカーネルスレッドがブロックすると、その上のすべてのユーザースレッドが停止(言語実装に依存)
- 例:Go goroutine(実装により 1:1 に近い)、Erlang process
グリーンスレッド(N:1 モデル)
- 言語実行時が完全に管理
- 利点:最も軽量、大量生成可能
- 欠点:マルチコア並列を使いにくい、I/O ブロッキング時の問題
- 例:初期 Java Thread、Python thread(GIL のため)
メモリ階層と可視性
並行処理では、複数実行主体のメモリ操作がどう見えるか(可視性)が重要:
CPU キャッシュの一貫性保証(Cache Coherency)なしに、複数スレッドは安全に動作しません。これが後述の メモリオーダリング の話へつながります。
タイムスライシングの現実
単一コア上の並行処理は、OS のタイマー割り込みにより時分割で実現:
各スレッドは自分が継続実行していると感じるが、実際には細切れ。どこで割り込まれるかは不確定。
競合状態とロック
同じデータを複数の実行主体が同時に触ると、順序によって結果が変わることがあります。これが競合状態です。
ロックはその対策ですが、
- 待ち
- 性能低下
- デッドロック
も持ち込みます。
レースコンディションの具体例
初期状態: counter = 0
Thread A Thread B
load r1, counter (r1 = 0)
load r2, counter (r2 = 0)
add r1, 1 (r1 = 1)
add r2, 1 (r2 = 1)
store counter, r1 (counter = 1)
store counter, r2 (counter = 1)
期待値: counter = 2
実際: counter = 1
複数スレッドが同時に読み込み→演算→書き込みを行うと、中間結果が上書きされる。これが Read-Modify-Write(RMW)競合。
同期プリミティブの階層
Mutex(相互排除ロック)
最も基本的な同期メカニズム。クリティカルセクションを排他的に実行:
// C/Pthreads の例
pthread_mutex_t lock;
pthread_mutex_lock(&lock);
counter++; // クリティカルセクション
pthread_mutex_unlock(&lock);
特性:
- 原子性保証:lock-unlock 間のコードは割り込まれない(論理的に)
- 可視性保証:unlock で変更がメモリに書き込まれ、次の lock で可視化
- 順序保証:前の unlock-lock 経由で順序が一貫
問題:
- デッドロック:互いにロック待ち
- 優先度逆転:低優先度タスクがロック保持で高優先度タスクをブロック
- ライブロック:再試行ループで進まない
- スターベーション:一部スレッドがロック取得機会を失う
Semaphore(セマフォ)
カウンタベースの同期。複数スレッドのリソースアクセスを制御:
// バイナリセマフォ(Mutex と同等)
sem_t sem;
sem_init(&sem, 0, 1); // 初期値 1
sem_wait(&sem); // カウント 1 → 0
// クリティカルセクション
sem_post(&sem); // カウント 0 → 1
カウンティングセマフォ:複数リソースへのアクセス制御
sem_init(&sem, 0, N); // N 個のリソース
sem_wait(&sem); // 1 つ確保(カウント N → N-1)
// リソース利用
sem_post(&sem); // 1 つ解放(カウント N-1 → N)
Condition Variable(条件変数)
ロック + 条件待機。効率的なウェイトベース同期:
pthread_mutex_t lock;
pthread_cond_t cond;
// Producer
pthread_mutex_lock(&lock);
// 共有状態更新
state = ready;
pthread_cond_broadcast(&cond); // 待機中のスレッド起動
pthread_mutex_unlock(&lock);
// Consumer
pthread_mutex_lock(&lock);
while (state != ready) { // spurious wakeup 対策
pthread_cond_wait(&cond, &lock); // lock 解放して待機
}
// 状態確認・処理
pthread_mutex_unlock(&lock);
Read-Write Lock(RW ロック)
読み取りは並列実行、書き込みは排他:
pthread_rwlock_t rwlock;
// Reader
pthread_rwlock_rdlock(&rwlock);
// 読取処理(複数スレッドで並行)
pthread_rwlock_unlock(&rwlock);
// Writer
pthread_rwlock_wrlock(&rwlock);
// 書込処理(排他)
pthread_rwlock_unlock(&rwlock);
特性:読み取り主体のワークロードで高性能。但し書き込みが多いと効果薄。
Barrier(バリア)
複数スレッドの同期点。全スレッドが到達するまで待機:
pthread_barrier_t barrier;
pthread_barrier_init(&barrier, NULL, 3); // 3 スレッド同期
pthread_barrier_wait(&barrier); // すべてが到達まで待機
Read-Copy-Update(RCU)
読み取りと更新を分離、読み取り側のロック排除:
// Reader: ロックなし
element = rcu_dereference(ptr);
read_value(element);
// Writer: 更新前に copy
new_element = copy_element(element);
modify(new_element);
rcu_assign_pointer(ptr, new_element);
synchronize_rcu(); // 既読者の完了待ち
free_old_element(element);
利点:読み取り性能が極度に高い(ロック0)。メモリリードが多いシステムに最適。
欠点:実装複雑、メモリオーバーヘッド、更新遅延。
原子操作(Atomic Operations)
ロックなしに原子性を保証する操作。ハードウェア命令で実現:
Compare-And-Swap(CAS)
メモリの条件付き更新。楽観ロックの基盤:
// 疑似コード
bool cas(volatile int *addr, int expected, int new_value) {
if (*addr == expected) {
*addr = new_value;
return true;
}
return false;
}
実例:ロックフリーなカウンタ
typedef struct {
volatile int count;
} atomic_counter;
void increment(atomic_counter *c) {
int old, new;
do {
old = c->count;
new = old + 1;
} while (!cas(&c->count, old, new)); // 成功まで再試行
}
ABA 問題
CAS の落とし穴:
Thread A: read(addr) = A
...(遅延)...
CAS(addr, A, B) // 成功と思うが...
Thread B: cas(addr, A, C) // A を C に変更
Thread C: cas(addr, C, A) // C を A に戻す
Thread A の CAS は形式上成功するが、実はメモリ内容が変わっている
対策:
- タグ(version)の付加
- Epoch based reclamation
- Hazard pointers
メモリオーダリング(Memory Ordering)
マルチコア環境で、複数スレッドのメモリ操作が見える順序は必ずしも論理的な順序と一致しない。
Sequential Consistency(SC)
最も強い保証:すべてのメモリ操作が全スレッドから同じ順序で見える。
Thread A Thread B
write(x, 1)
write(y, 2) read(y) // 2 が見える
read(x) // 1 が見える(保証)
Total Store Order(TSO)
x86-64 のデフォルト。ストア(書き込み)がメモリへ到達するまで遅延可能だが、ロード(読み込み)は待ちきる:
Thread A Thread B
write(x, 1)
write(y, 2)
read(y) // 2 が見える可能性あり
read(x) // 0 が見える可能性(TSO では許容)
対策:メモリバリア命令(mfence, lfence, sfence)
Acquire-Release
ロック的な順序保証。acquire は後続操作を前置できず、release は前置操作を後置できない:
// C++11 atomic の例
std::atomic<int> x;
x.store(1, std::memory_order_release); // release
int val = x.load(std::memory_order_acquire); // acquire
Weak Memory Models(ARM, PowerPC)
メモリ操作の順序保証が弱い。明示的なバリアが必須:
// ARM: バリア命令必要
dmb // Data Memory Barrier
ロックは万能ではない
ロックを入れると安心に見えますが、
- 粒度が粗いと遅くなる
- 粒度が細かいと複雑になる
- ロック順序を誤ると詰まる
という難しさがあります。
粒度の考え方:
- 粗粒度ロック:大きなロック 1 つで大量のデータを保護 → 競合多、性能低
- 細粒度ロック:データ要素ごとにロック → 実装複雑、デッドロックリスク高
- 最適粒度:競合と実装複雑さのバランス
原子性と可視性
並行性では「途中で割り込まれない」だけでなく、「他の実行主体にどう見えるか」も大事です。これがメモリモデルやアトミック操作の話につながります。
Visibility(可視性):スレッド A の書き込みが、スレッド B にいつ見えるか Atomicity(原子性):操作が途中で割り込まれず完了するか
デッドロック
互いに相手の資源待ちになって止まる状態です。
デッドロック成立の 4 条件(Coffman Conditions, 1971)
すべての条件がそろったときだけデッドロック発生:
-
相互排他(Mutual Exclusion): リソースは 1 度に 1 スレッドにしか割り当てられない
-
保持と待機(Hold and Wait): リソース保持中に他のリソース待機
-
非奪取(No Preemption): 他のスレッドが持つリソースを強制奪取不可
-
循環待ち(Circular Wait): リソース取得順序が循環(A → B → C → A)
具体例:古典的デッドロック
// Thread A
lock(L1);
// ... 処理 ...
lock(L2); // 待機(Thread B が保持)
unlock(L2);
unlock(L1);
// Thread B
lock(L2);
// ... 処理 ...
lock(L1); // 待機(Thread A が保持)
unlock(L1);
unlock(L2);
// 実行順序で詰まる可能性
// Time 1: A が L1 取得
// Time 2: B が L2 取得
// Time 3: A が L2 待ち(B 保持)
// Time 4: B が L1 待ち(A 保持)
// → デッドロック
循環待ちの可視化
リソース割当グラフ(Resource Allocation Graph)でデッドロック検出:
サイクルが存在 → デッドロック可能性あり。
デッドロック検出と回復
銀行家アルゴリズム(Banker’s Algorithm, Dijkstra 1965)
リソース割り当て前に、割り当て後も安全状態(セーフステート)に留まるか判定:
状態情報:
- Available: 利用可能リソース数
- Max: 各スレッドの最大必要数
- Allocated: 現在割り当て済み
- Need = Max - Allocated
Safety Check:
1. Work = Available (作業用コピー)
2. Finish = false for all threads
3. Need ≤ Work なスレッドを見つける
4. 見つかれば: Work += Allocated, Finish = true, 3へ
5. すべて Finish = true なら Safe, さもなくば Unsafe
// 疑似実装
bool is_safe(int available, int need[], int allocated[]) {
int work = available;
for (int iter = 0; iter < NUM_THREADS; iter++) {
bool found = false;
for (int i = 0; i < NUM_THREADS; i++) {
if (!finished[i] && need[i] <= work) {
work += allocated[i];
finished[i] = true;
found = true;
break;
}
}
if (!found) break;
}
return all_finished;
}
特性:最悪ケース O(n³) の計算。大規模システムでは実用困難。
タイムアウトベース検出
デッドロック検出を諦めて、タイムアウトで対処:
struct timespec deadline;
clock_gettime(CLOCK_REALTIME, &deadline);
deadline.tv_sec += 5; // 5秒タイムアウト
if (pthread_mutex_timedlock(&lock, &deadline) == ETIMEDOUT) {
fprintf(stderr, "Potential deadlock: lock timeout\n");
// 再試行、ロールバック、エラー報告など
}
利点:実装簡単。
欠点:本当の遅延とデッドロックを区別不可。
デッドロック回避戦略
1. ロック順序の統一(Ordering)
すべてのスレッドが同じ順序でロック取得:
// 悪い例(デッドロック可能)
Thread A: lock(L1) -> lock(L2)
Thread B: lock(L2) -> lock(L1)
// 良い例(デッドロック不可)
Thread A: lock(L1) -> lock(L2)
Thread B: lock(L1) -> lock(L2) // 順序統一
実装方法:
- ロック ID を定義し、常に小さい方から取得
- グラフのトポロジカルソート
#define LOCK_A 0
#define LOCK_B 1
void lock_multiple(int *locks, int count) {
// ソート
qsort(locks, count, sizeof(int), compare);
// 小さい順に取得
for (int i = 0; i < count; i++) {
pthread_mutex_lock(&mutexes[locks[i]]);
}
}
2. ロック保持時間の最小化
ロック範囲を必要最小限に:
// 悪い例:ロック保持時間が長い
pthread_mutex_lock(&lock);
read_from_disk(); // I/O(遅い)
write_to_db(); // I/O(遅い)
pthread_mutex_unlock(&lock);
// 良い例:ロック範囲を縮小
read_from_disk();
write_to_db();
pthread_mutex_lock(&lock);
update_counter();
pthread_mutex_unlock(&lock);
3. ロック取得の Atomicity
複数ロックが必要な場合、同時取得を保証:
// 良い例:専用関数で同時取得
void acquire_all(pthread_mutex_t *locks[], int count) {
qsort_locks(locks, count);
for (int i = 0; i < count; i++) {
pthread_mutex_lock(&locks[i]);
}
}
4. 共有状態の削減(共有の最小化)
スレッドローカルストレージ、イミュータブル構造、メッセージパッシング等:
// スレッドローカル
__thread int local_counter = 0; // 各スレッドが独立
// 集計は最後に
int total = 0;
for (each thread) {
total += thread_local_counter;
}
5. Try-Lock と バックオフ
非ブロッキングロック取得で循環待ちを回避:
void acquire_with_backoff(pthread_mutex_t *l1, pthread_mutex_t *l2) {
int retries = 0;
while (retries < MAX_RETRIES) {
if (pthread_mutex_trylock(l1) == 0) {
if (pthread_mutex_trylock(l2) == 0) {
return; // 成功
}
pthread_mutex_unlock(l1); // 失敗したら unlock
}
exponential_backoff(retries++);
}
// 最後の手段:ブロッキング取得
pthread_mutex_lock(l1);
pthread_mutex_lock(l2);
}
ライブロック(Livelock)と スターベーション
デッドロック並の問題:
ライブロック:スレッドは実行中だが、進まない
// 例:無限リトライ
while (!cas(ptr, old, new)) {
// 他スレッドと競合し続けて永遠にリトライ
}
スターベーション:一部スレッドが資源アクセス機会を永遠に失う
// 例:読み取り優先が強すぎると、書き込みが飢える
// RW ロックの実装で読者が絶えないと、書者は永遠待機
対策:
- バックオフ時間をランダム化
- フェアネス保証のあるロック(FIFO ロック)
- 優先度付けスケジューリング
優先度逆転(Priority Inversion)
低優先度タスクがロック保持により、高優先度タスクをブロック:
時刻 | 高優先度 | 中優先度 | 低優先度
-----|-----------|-----------|----------
1 | 準備完了 | 実行 | ロック取得
2 | ロック待 | 実行 | 実行
3 | ロック待 | CPU奪取 | 実行
4 | ロック待 | 実行 | ロック解放
5 | 実行 | 中止 | 終了
結果:高優先度が中優先度に割り込まれた
事例:NASA Mars Pathfinder(1997)
VxWorks リアルタイム OS で優先度逆転発生。実装ではロック保持タスクの優先度を一時上昇させた。
対策:
- 優先度継承(Priority Inheritance):ロック保持タスク的優先度を上昇
- 優先度天井(Priority Ceiling Protocol):ロック取得時に優先度を固定値まで引き上げ
// 優先度継承 (pthread で自動適用される実装もある)
pthread_mutexattr_t attr;
pthread_mutexattr_setprotocol(&attr, PTHREAD_PRIO_INHERIT);
pthread_mutex_init(&lock, &attr);
デッドロック防止チェックリスト
- [ ] すべてのロック取得順序を統一したか
- [ ] ロック保持範囲を最小化したか
- [ ] 共有状態を削減できないか
- [ ] タイムアウトを設定したか
- [ ] 優先度逆転の可能性を考慮したか
- [ ] Try-Lock でフォールバックできるか
どう防ぐか
典型的な方針は、
- ロック取得順序を統一する
- タイムアウトや再試行を入れる
- そもそも共有状態を減らす
です。根本的には「待ちの輪」を作らないことが大切です。
分散システムの難しさ
複数マシンにまたがると、
- 故障
- 通信遅延
- 部分的不一致
- 再試行
が前提になります。
単一マシン感覚が壊れる場所
分散で厄介なのは、相手が遅いのか、落ちたのか、返事が途中で消えたのか、こちらからは区別しにくいことです。
つまり「失敗した」と見える事象の裏に、
- 実行されていない
- 実行されたが返事が消えた
- 一部だけ進んだ
といった複数の可能性があります。これが再試行や冪等性の話へつながります。
分散システムの障害モデル
クラッシュ故障(Crash Failures)
ノードが急に停止。以降応答なし。比較的扱いやすい。
オムニッシェント障害(Omni-present Failures)
実装依存だが、ノードは予告なく停止することもあれば、通信が遅れることもある。
ビザンチン障害(Byzantine Failures)
ノードが任意に振る舞える(故意または破損)。悪意ある攻撃シミュレーション。
正常: 正しい応答
クラッシュ: 応答なし
ビザンチン: 矛盾した応答、順序逆転、捏造データ
ネットワーク遅延と信頼性
同期モデル(Synchronous Model)
メッセージ配送に上限 Δ がある(理想的だが現実的でない)
非同期モデル(Asynchronous Model)
メッセージ配送時間に上限がない(現実的だが対応困難)。FLP 定理(Fischer-Lynch-Paterson, 1985)によれば、非同期環境で確実な合意は不可能。
部分同期(Partial Synchrony)
通常は同期的だが、時々上限が破られる。実務的な中間モデル。
分散システムの特性
因果性(Causality)
イベント間の依存関係:A → B のとき A は B より先(他は順序不定)。
Event A: データ X に値 1 を書く
Event B: X を読むと 1 が見える(A の後)
Event C: Y に値 2 を書く(A と因果無関係)
可見性(Visibility)の遅延
ネットワーク遅延により、あるノードの変更が別ノードに見えるまでに時間が必要。
タイムスタンプの役割
分散システムでは各ノードが独立した時計を持つため、絶対時刻では順序付けできない。
Lamport クロック(Lamport, 1978)
因果順序を捕捉する論理時計:
ルール:
1. 各プロセスは時計 L を保持(初期値 0)
2. イベント発生時: L = L + 1
3. メッセージ送信: タイムスタンプ T を付加
4. メッセージ受信: L = max(L, T) + 1
Process A Process B
Event: L_A = 1
send(msg, L=1)
receive(msg, L=1)
L_B = max(2, 1) + 1 = 3
Event: L_B = 4
特性:
- A → B (因果順序)なら L_A < L_B
- 逆は保証されない(因果無関係なイベント間でも時計値で順序付けは可能だが、意味がない)
ベクタークロック(Vector Clock, Mattern 1988)
より強い順序保証。各プロセスの時計を配列で管理:
Process A: VC_A = [1, 0]
send(msg, VC=[1, 0])
Process B: VC_B = [0, 1]
receive(msg)
VC_B = max([0,1], [1,0]) + [0,1] = [1, 2]
特性:
- A → B iff VC_A < VC_B (すべての要素で ≤、少なくとも 1 つで <)
- 因果順序を完全に捕捉
欠点:スケーラビリティ(O(n) サイズ)
ハイブリッド論理時計(Hybrid Logical Clock, Kulkarni et al. 2014)
Lamport + 物理時計。スケーラビリティと物理時間の関連を両立:
HLC = <pt, l>
pt: 物理時刻(ナノ秒)
l: 論理部(pt が同じ場合の順序付け)
利点:メタデータサイズが小さい。Google Spanner で採用。
時間同期の課題
NTP(Network Time Protocol)
ネットワーク経由で時刻合わせ。ただし遅延やネットワーク分断で精度喪失:
クライアント サーバー
t1: 送信
t2: 受信
t3: 応答送信
t4: 受信
ラウンドトリップ遅延 = (t4 - t1) - (t3 - t2)
オフセット ≈ ((t2 - t1) + (t3 - t4)) / 2
精度:ネットワーク遅延に依存。LAN で数 ms、WAN で数十 ms。
GPS/原子時計
高精度同期。データセンタで使用可能。
Google TrueTime API
複数時源から信頼区間 [earliest, latest] で時刻を提供。Spanner で一貫性読み取りを実現。
TrueTime.now() = { earliest: 12:34:56.100, latest: 12:34:56.150 }
不確実さ: 50ms
CAP 定理と一貫性モデル
分断がある世界では、
- Consistency(一貫性)
- Availability(可用性)
- Partition tolerance(分割耐性)
を同時に最大化できません。
これは「どの性質を優先する設計か」を考える道具です。
CAP の由来と意味
Gilbert & Lynch, 2002 が証明。実は Brewer の推測(2000) を厳密化したもの。
定義:
- C(Consistency):すべてのノードが同じデータを見る(Linearizability)
- A(Availability):すべてのリクエストが完了応答を得る
- P(Partition tolerance):ネットワーク分断下でも動作
厳密な主張:
- 正常時(分断なし):CA 両立可能
- 分断時:C と A のトレードオフが発生。P は選択肢ではなく前提。
PACELC 定理(Abadi, 2010)
CAP をさらに精密化:
- P:分断時は C と A のトレード
- E:通常時は L(遅延)と C(一貫性)のトレード
通常時:
高レイテンシ(複数ノード同期待ち)
vs
低遅延応答(古い値でも返す)
分断時:
強一貫性保証(応答制限)
vs
高可用性(古い値許容)
実務的には多くのシステムが PA(Partition時 Availability 優先) で設計され、通常時は 低遅延 を選択。
一貫性モデルの階層
Linearizability(線形化可能性)
最も強い。すべてのオブザーバーが同じ時系列を見る:
Writer: write(x, 1) at t=0
Reader A: read(x) at t=1 → 1 が見える
Reader B: read(x) at t=2 → 1 が見える
実装コスト高。ロック、レプリケーション遅延により遅い。
Sequential Consistency(順序一貫性)
プログラム順序は維持。ただし絶対時系列は保証されない:
Program A: write(x, 1), write(y, 2)
Program B: read(y) → 0 or 2 OK, read(x) → 1 が見える
(A の write(x,1) → write(y,2) の順序は保証)
Causal Consistency(因果一貫性)
因果関係にあるイベントだけ順序保証:
Process A: write(x, 1)
Process B: read(x)=1, write(y, 2)
Process C: read(y)=2, read(x) → 1 が見える(因果遵守)
read(y)=2, read(x)=0 は不可
Eventual Consistency(結果整合性)
長期的には全ノードが同じ状態に収束。短期的不一致を許容:
時刻 0: Node A write(x, 1)
時刻 1: Node B read(x) → 0 or 1 不定
時刻 100ms: Node B read(x) → 1 確定
多くの NoSQL(Dynamo, Cassandra)が採用。
Strong Eventual Consistency(強い結果整合性)
結果整合性の下で、衝突自動解決が一意:
Node A: x := 1 (timestamp: t1)
Node B: x := 2 (timestamp: t2)
マージ後: 両ノードとも x := max(t1, t2) → 同じ値
CRDTで実現。
Consistency の意味に注意
ここでの C は「すべてのノードが最新値を見る」という分散システム文脈の一貫性で、DB の ACID における Consistency(トランザクション正合性)と同じ語でもニュアンスが違います。
実務での一貫性選択
| モデル | 遅延 | 複雑さ | 用途 |
|---|---|---|---|
| Linearizable | 高 | 高 | 金融決済、リーダー選出 |
| Sequential | 中 | 中 | 一般的なアプリケーション |
| Causal | 低 | 中 | ソーシャルメディア(投稿順序) |
| Eventual | 低 | 低 | キャッシュ、ログ蓄積 |
| Strong Eventual | 低 | 中 | リアルタイムコラボレーション(Google Docs) |
ネットワーク分断の現実
Jepsen Analysis(Kyle Kingsbury)によると、大規模分散システムは:
- AWS で分断イベント月 1 回程度
- 遠地データセンタ間で数秒規模
- 予告なく発生
対策:
- テスト環境で意図的に分断を発生させる(Chaos Engineering)
- タイムアウト値を適切に設定
- 分断時の振る舞いを明確に定義
合意形成とリーダー選出
複数ノードで「どの順序で何を採用するか」をそろえる必要があります。
- Raft
- Paxos
- その他(HotStuff、Tendermint)
が代表です。
リーダーを立てると、順序づけを一か所へ寄せやすくなります。
FLP 不可能性定理(Fischer-Lynch-Paterson, 1985)
主張:非同期分散システムで確実な合意は不可能(ビザンチン障害なし)。
前提:
- 非同期(メッセージ遅延に上限なし)
- クラッシュ可能
- 信頼通信
結論:
- 安全性(すべてが同じ値で決定)と
- 活性(すべて有限時間で決定)
を同時に保証できない。
実務的対処:
- 部分同期仮定(通常は同期、時々非同期)
- タイムアウトによる推定
- 確率的アルゴリズム
何を合意するのか
「今の値」そのものより、どの順番でどの命令を採用したか に合意する、と考えると理解しやすいです。順序がそろえば、各ノードは同じ状態機械を再生できます。
Raft 合意形成アルゴリズム(Ongaro & Ousterhout, 2014)
設計目標:正確性を保ちながら理解しやすく。
Raft の 3 つの要素
1. Leader Election(リーダー選出)
各ノードは term(世代)を持つ。term が進むと古いリーダーは無視される:
初期状態:全ノードが Follower, term=1
Follower がタイムアウト(election timeout: 150-300ms)
→ Candidate へ遷移
→ term を増やす(term=2)
→ 他ノードへ投票要求(RequestVote)
他ノードで応答:
→ Candidate の term が高ければ投票
→ Majority 獲得 → Leader 昇格
Leader は定期的に Heartbeat(AppendEntries)を送信
→ Follower のタイムアウトをリセット
タイムアウト設定の重要性:
- Election timeout が短すぎる → 頻繁なリーダー切り替え
- Election timeout が長い → 故障復旧に時間
- 一般的:150-300ms
2. Log Replication(ログ複製)
Client は Leader へエントリを送信。Leader が Followers へ複製:
Log structure:
[Entry] = { term, index, command, ...}
例:
Follower 1: [1,cmd_a] [1,cmd_b] [2,cmd_c]
Follower 2: [1,cmd_a] [1,cmd_b] [2,cmd_c]
Follower 3: [1,cmd_a] (遅延中)
AppendEntries RPC で同期:
// Leader が Follower へ送信
AppendEntries {
term: 2,
leaderId: node_1,
prevLogIndex: 2, // 前のエントリ index
prevLogTerm: 1, // 前のエントリ term
entries: [cmd_c],
leaderCommit: 2
}
// Follower の応答ロジック
if (request.term < currentTerm) {
return false; // 古い term は拒否
}
if (log[prevLogIndex].term != request.prevLogTerm) {
return false; // ログ不一致は拒否(ロールバック)
}
append(entries);
return true;
スナップショット:ログが長くなりすぎないよう、一定周期で state machine の状態を保存。
3. Safety Guarantee(正合性保証)
- Election Safety:1 term に 1 Leader のみ
- Leader Append-Only:Leader は既存ログを削除しない
- Log Matching:2 ノードのログが同じ index, term を持つなら、それ以前の内容も同じ
- Leader Completeness:committed entry は次 Leader へ継承
- State Machine Safety:各 state machine が同じ entry を同じ index に適用
Paxos アルゴリズム(Lamport, 1998)
背景:古い。難しい。だが数十年実績。Google Chubby、Apache Zookeeper で採用。
3 つのロール
Proposer: 提案を出す(通常 Leader)
Acceptor: 提案を受け入れる(複数ノード)
Learner: 承認された値を学ぶ(どのノードでもよい)
2 つのフェーズ
Phase 1a: Prepare Proposer が提案 N を送信
Proposer:
prepare(proposal_number=n) をすべて Acceptor へ
Acceptor:
if (n > max_promised_number):
max_promised_number = n
return highest_accepted_proposal
else:
return nack
Phase 1b: Promise Acceptor が約束を返す
Acceptor:
「この proposal_number 以上の提案だけ受け入れる」と約束
Phase 2a: Accept Request Proposer が値提案
Proposer:
(Majority が promise を返したら)
最も recent な accepted value を取得し、なければ自分の値を提案
accept(proposal_number=n, value=v) をすべてへ
Acceptor:
if (n >= max_promised_number):
accepted_value = v
return ack
Phase 2b: Accepted Acceptor が受け入れ
Acceptor:
Learner(および Proposer)へ ack を返す
Learner:
Majority の ack を確認 → value = v で決定
特性:
- 正確性保証は強い
- 実装が複雑
- Multi-Paxos(連続提案)の設定が難しい
Raft vs Paxos
| 側面 | Raft | Paxos |
|---|---|---|
| 理解しやすさ | ◎ 設計目標 | △ 難しい |
| 正確性 | ○ | ◎ |
| 実装例 | etcd, Consul, TiKV | Chubby, Zookeeper |
| Leader 依存 | 強い | 弱い |
| 故障復旧 | 比較的速い | やや遅い |
リーダー選出の意味
リーダーは偉いから必要なのではなく、意思決定の入口を絞ることで競合を減らすために置かれます。ただしリーダー障害時の切り替えや、古いリーダーの扱いが難しさになります。
古いリーダー問題(Split Brain):
正常時: Leader が Followers へ Heartbeat
→ タイムアウト無し
ネットワーク分断:
Leader <--> Follower A, B(多数派)
Leader <X> Follower C, D(少数派)
少数派は新リーダー選出 → 2 つの Leader
対策:Quorum(過半数)必須で、少数派 Leader は write 受け付けず読み取りのみ。
ログ複製と状態機械複製
分散システムでは、「値を直接そろえる」というより、同じ順序のログを共有する と見ると理解しやすいです。
ログ複製のフロー
1. Client のリクエスト受け取り
→ Leader のログへ未コミット状態で追加
2. Followers へ送信(AppendEntries RPC)
→ Followers がログへ追加
3. Majority が受信確認
→ Leader が「この entry はコミット」判定
4. State Machine へ適用
→ 各ノードがコマンド実行
5. Client へ応答返却
なぜログなのか
直接「今の状態」を配るより、どう変化したかの列をそろえるほうが扱いやすいことが多いです。
利点:
- 監査(Audit):いつだれが何を変えたか追跡可能
- 再実行(Replay):ノード追加時、スナップショット + ログで復帰
- 追いつき(Catch-up):遅延ノードはログを順に実行
- 障害復旧(Recovery):ペアリング、バックアップから復元
- イベントソーシング:ビジネスロジックとの親和性
状態機械複製(State Machine Replication)
各ノードが同じ初期状態から、同じ順序でコマンドを適用すれば、最終状態もそろいやすい:
初期状態: counter = 0
全ノード: counter += 1, write_log(msg="a"), counter += 2
各ノード最終: counter = 3, log = ["a"]
Raft や Paxos は、その順序をどうそろえるかを扱っています。
スナップショット(Snapshotting)
ログが肥大化を防ぐため、定期的に状態を記録:
時刻 0-100: コマンド実行、ログに entry 追加
時刻 100: Snapshot 作成(state = {...})
時刻 101以降: スナップショット時点 + 新しいログのみ保持
新ノード追加時:
1. スナップショット送信(高速)
2. その後の差分ログ送信
実装例(etcd):
スナップショット = {
"term": 5,
"index": 1000,
"state": {
"key": "value",
...
}
}
新ノードへ送信 →
スナップショット適用 →
index > 1000 のログだけ追いつく
ログ圧縮と増分同期
RPC による増分送信:
// Leader が Follower へ送信
struct AppendEntries {
int term;
int leaderId;
int prevLogIndex; // ここまで同じと確認
int prevLogTerm;
LogEntry* entries; // prevLogIndex 以降の差分
int leaderCommit;
};
// Follower 側のロジック
if (prevLogIndex が手元にあって term が一致) {
// 差分だけ追加(効率的)
append(entries);
} else {
// ログロールバック
deleteLogsAfter(prevLogIndex);
append(entries);
}
クォーラムと遅延複製
Majority quorum での複製により、遅いノードの影響を最小化:
5 ノード構成:
Leader へ送信 →
Majority (3) へ到達で即座にコミット →
遅いノード 2 個は後で追いつく(同期不要)
Availability:
N ノード中 floor(N/2) + 1 生存すれば動作可能
冪等性と再試行
同じ操作を何度しても結果が変わらない性質が冪等性です。
再試行がある世界ではとても重要です。
通信失敗のシナリオ
シナリオ 1: Request が到達、Response 喪失
Client ---> Server (request到達)
Server が処理完了 ✓
Server --x Client (response lost)
Client は何もわからない。「失敗したのか?成功?」
再試行時:
2 回目のリクエスト送信
→ Server で「これ見たことある」判定が必要
Idempotency Key パターン
定義:同じ idempotency key で複数回リクエストしても、サーバー側の最終状態は 1 回分。
// API ハンドラ
@POST
@Path("/transfer")
public Response transfer(
@HeaderParam("Idempotency-Key") String idempotencyKey,
TransferRequest req
) {
// 1. キャッシュ確認
CachedResult cached = idempotencyCache.get(idempotencyKey);
if (cached != null) {
return cached.response; // 再試行は同じ応答
}
// 2. 処理実行
Transfer transfer = executeTransfer(req);
// 3. キャッシュへ記録
idempotencyCache.put(idempotencyKey, new CachedResult(transfer));
return response;
}
実装パターン:
- DB の一意制約:
CREATE UNIQUE INDEX idempotency_key_idx
ON transfers(idempotency_key);
INSERT INTO transfers VALUES (...)
ON CONFLICT (idempotency_key)
DO UPDATE SET ...;
- キャッシュ:
Idempotency-Key: "abc-123-def"
→ Redis へ key で lookup
→ hit: cached result 返却
→ miss: 処理実行 → キャッシュ記録
- Outbox パターン:
BEGIN TRANSACTION
INSERT INTO transfers (...)
INSERT INTO outbox (event_type='transfer', data=...)
COMMIT
Outbox 처리자:
SELECT FROM outbox WHERE processed=false
→ イベント配信
→ UPDATE outbox SET processed=true
Exactly Once の困難さ
3 つの障害モード:
Mode A: Request 到達、処理未実行、Response 喪失
→ 再試行で正しく処理
Mode B: Request 到達、処理完了、Response 喪失
→ 再試行で重複実行
Mode C: Request 到達、処理中断、Response 喪失
→ 再試行で部分的な再実行
Mode B を防ぐために冪等性必須。
実務での選択肢:
| 保証 | 説明 | 対応 |
|---|---|---|
| at-most-once | 重複なし。ただし喪失あり | 再試行なし |
| at-least-once | 再試行により重複あり | 冪等性で吸収 |
| exactly-once | 重複なし、喪失なし | at-least-once + 冪等性 |
メッセージングシステムでの保証
Kafka
デフォルト:at-least-once(正確には、プロデューサー設定依存)
Enable.idempotence=true: ブローカー側で重複排除
→ PID + SeqNum で同じメッセージを検出
RabbitMQ / AMQP
publisher-confirm: ブローカーが message 受信確認
consumer ack: コンシューマーが処理完了を通知
-> 組み合わせで at-least-once 実現
AWS SQS
デフォルト:at-least-once 唯一の exact-once 保証:SQS Fifo + ReceiveMessageWaitTime
再試行戦略
指数バックオフ
int backoff_ms = 100; // 初期値
for (int attempt = 0; attempt < MAX_RETRIES; attempt++) {
try {
return doRequest();
} catch (Exception e) {
if (shouldRetry(e)) {
sleep(backoff_ms);
backoff_ms = min(backoff_ms * 2, MAX_BACKOFF_MS);
} else {
throw;
}
}
}
リトライ間隔:100ms, 200ms, 400ms, 800ms, …(最大 10s など)
Jitter の追加
long jitter = random.nextLong(backoff_ms / 2);
sleep(backoff_ms + jitter);
多数のクライアントが同時リトライして thundering herd 問題を回避。
冪等性のレベル
Pure Idempotency(純粋な冪等性)
同じ入力 → 常に同じ出力。副作用なし。
GET /api/users/123
→ 常に {id: 123, name: "Alice"} (読み取り専用)
Semantic Idempotency(意味的冪等性)
複数回実行しても最終状態は 1 回分。
PUT /api/account/balance (body: amount=100)
→ 実行 1 回: balance = 100
→ 実行 2 回: balance = 100(同じ)
No Idempotency(冪等でない)
POST /api/queue/enqueue (body: msg)
→ 実行 1 回: queue に 1 件追加
→ 実行 2 回: queue に 2 件追加(問題!)
対策:idempotency key が必須。
実務での実装チェックリスト
- [ ] キーとなるエンティティに幾何学的 ID(UUID など)があるか
- [ ] 冪等キーの有効期限(TTL)を決めたか
- [ ] 冪等性の実装が各リソースで統一されているか
- [ ] 再試行ロジックのバックオフを設定したか
- [ ] 意味的冪等性の境界を明確に定義したか
- [ ] テストで重複実行をシミュレートしたか
何に似ているか
「注文書を送ったが返事が来ないので再送したら、相手は最初の分も処理していた」という事務ミスに似ています。通信の失敗と処理の失敗は別なので、重複を吸収する仕組みが必要です。
キューとストリーム処理
キュー(Queue)
仕事をためて、あとで非同期に処理する仕組みです。
- 平滑化
- 疎結合
- 再試行
に効きます。
キューの動作モデル
Producer(生産者)
↓
キュー(メモリ、Redis、RabbitMQ など)
↓
Consumer(消費者)
例:
リクエスト受け取り → キューに積む → 即座に応答
別プロセスでキュー取り出し → 非同期処理
キューの特性と応用
Decoupling(疎結合):
同期API: Client → Service
Failure: Service が遅い → Client も遅い
Async Queue: Client → Queue → Service
Service が遅くても Queue は即座に応答
Service 再起動時も Queue 内のジョブは保持
Backpressure Handling(負荷調整):
Peak時: リクエスト速度 > 処理速度
→ キュー長が増加
→ Consumer を増やす
→ Consumer が多数のジョブを並列処理
Peak終了後: キュー処理
→ Consumer 数削減(コスト削減)
失敗時の自動再試行:
// Consumer コード
while (true) {
Job job = queue.dequeue();
try {
process(job);
queue.ack(job); // 成功: 削除
} catch (Exception e) {
// 自動的に再キュー
queue.nack(job); // 失敗: キューに戻す
queue.retry_later(job, delay=exp_backoff);
}
}
Dead Letter Queue(DLQ): 何度も失敗するジョブは DLQ へ移動して、後で調査:
Normal Queue
→ Process → Success → ACK
→ Process → Fail → Retry
→ Process → Fail → Retry
→ ... (MAX_RETRIES) ...
→ Dead Letter Queue(人間が確認)
ストリーム処理(Stream Processing)
流れてくるイベントを継続的に処理します。
イベントストリーム
→ フィルタリング
→ 変換
→ 集約
→ 外部システムへ配信
キューとストリームの比較
| 側面 | キュー | ストリーム |
|---|---|---|
| セマンティクス | 仕事の消費 | イベントの観測 |
| 複数消費者 | 通常は 1 個(競争) | 複数可(独立) |
| リプレイ | 削除済みは不可 | 保持期間内なら可能 |
| 用途 | タスク実行 | ログ、監視、イベント駆動 |
| 例 | Job Queue (RabbitMQ) | Event Stream (Kafka) |
ストリーム処理の実装パターン
Map(変換):
// Kafka Streams
stream
.map((key, value) -> new Record(key, value.toUpperCase()))
.to("output-topic");
Filter(フィルタリング):
stream
.filter((key, value) -> value.getTemperature() > 30)
.to("high-temp-topic");
Aggregate(集約):
// ウィンドウ集約:直近 5 分間のメッセージ数
stream
.groupByKey()
.windowedBy(TimeWindows.ofSizeMs(5 * 60 * 1000))
.count()
.toStream()
.to("count-topic");
Stateful Processing(状態保持):
// ユーザーセッションの追跡
stream
.selectKey((k, v) -> v.userId)
.groupByKey()
.aggregate(
() -> new Session(),
(key, event, session) -> {
session.addEvent(event);
return session;
},
TimeWindows.ofSizeMs(30 * 60 * 1000) // 30 min session
);
代表的なストリーム処理エンジン
Apache Kafka Streams
嵌め込み型フレームワーク。専用クラスタ不要:
StreamsBuilder builder = new StreamsBuilder();
KStream<String, String> source = builder.stream("input-topic");
source
.filter((key, value) -> value.contains("error"))
.to("error-topic");
KafkaStreams streams = new KafkaStreams(builder.build(), props);
streams.start();
利点:シンプル、遅延小、デプロイ容易
Apache Flink
分散フレームワーク。スケーラビリティ重視:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<Event> source = env.addSource(new KafkaSource<>(...));
source
.keyBy(Event::getUserId)
.window(TumblingEventTimeWindows.of(Time.minutes(1)))
.sum("amount")
.addSink(new PrintSinkFunction<>());
env.execute("Flink Job");
利点:複雑な processing、Exactly-Once 保証、高スケーラビリティ
Google Cloud Dataflow / Apache Beam
クラウド向け統一 API:
pipeline = beam.Pipeline()
events = pipeline | 'read' >> beam.io.ReadFromKafka(...)
filtered = events | 'filter' >> beam.Filter(lambda x: x['temp'] > 30)
windowed = filtered | 'window' >> beam.WindowInto(beam.window.FixedWindows(60))
result = windowed | 'output' >> beam.io.WriteToKafka(...)
pipeline.run()
利点:マルチクラウド対応、バッチ + ストリーム統一
ストリーム処理での重要概念
ウィンドウ処理(Windowing)
時間的にイベントをグループ化:
Tumbling Window(タンブリング):
|----1min----|----1min----|----1min----|
[1,2,3,...] [10,20,30,...][15,25,...]
Sliding Window(スライディング):
|--1min--|
|--1min--|
|--1min--| (50% オーバーラップ)
Session Window(セッション):
Event stream: [1] [2] [3] ... (30sec gap) ... [10] [11]
Sessions: [1,2,3,...] | [10,11] (30sec 以上ギャップで分割)
Watermark(ウォーターマーク)
遅延データをいつまで待つかを指定:
Watermark: イベント時刻 - 許容遅延
例:現在の max event time が 12:00 なら
Watermark = 12:00 - 1min = 11:59
→ 11:59 以前のウィンドウは close
→ その後到着したデータは無視(またはサイドアウト)
状態バックエンド
ストリーム処理エンジンの状態(中間結果など)をどこに保存:
Memory: 高速だが紛失リスク(再起動で喪失)
RocksDB: エンジン組込 DB。高速、持続性
External DB: Redis、DynamoDB など(遅いが確実)
キューとストリーム処理の選択フロー
非同期プログラミング
コールバック、Promise、async/await の進化
Callback(コールバック)
最初期の非同期パターン。関数を引き渡して、完了時に呼び出す:
// Node.js コールバック地獄
getUserData(userId, function(err, user) {
if (err) {
console.error(err);
} else {
getOrders(user.id, function(err, orders) {
if (err) {
console.error(err);
} else {
getOrderDetails(orders[0].id, function(err, details) {
if (err) {
console.error(err);
} else {
console.log(details);
}
});
}
});
}
});
問題:
- ピラミッド状のコード(callback hell)
- エラーハンドリングが散乱
- 順序制御が直感的でない
Promise
チェーン可能な非同期。.then() で順序制御:
getUserData(userId)
.then(user => getOrders(user.id))
.then(orders => getOrderDetails(orders[0].id))
.then(details => console.log(details))
.catch(err => console.error(err));
利点:
- ネスト減少
- 統一的なエラーハンドリング(
.catch())
async/await
Promise の糖衣構文。同期コードのように書ける:
async function processOrder(userId) {
try {
const user = await getUserData(userId);
const orders = await getOrders(user.id);
const details = await getOrderDetails(orders[0].id);
console.log(details);
} catch (err) {
console.error(err);
}
}
特性:
- 可読性 ◎
- 制御フロー直感的 ◎
- 内部は Promise (変わらず)
並列実行 vs 順序実行
// 順序実行(前のが終わるまで待つ)
const user = await getUserData(userId); // 1s
const orders = await getOrders(user.id); // 1s
// 合計 2s
// 並列実行(同時開始)
const [user, orders] = await Promise.all([
getUserData(userId), // 1s
getOrders(userId) // 1s(並列)
]);
// 合計 1s(ほぼ)
Go の Goroutine と Channel
Go は言語レベルで並行性をサポート:
// Goroutine: 軽量スレッド(コーチン的)
go fetchUser(userId) // 新ゴルーチンでバックグラウンド実行
// Channel: ゴルーチン間通信
resultChan := make(chan User)
go func() {
user := fetchUser(userId)
resultChan <- user // 送信
}()
user := <-resultChan // 受信(ブロック)
Channel の同期メカニズム
// Buffered Channel: 複数値を保持
ch := make(chan int, 3)
ch <- 1 // ブロックしない(バッファに space あり)
ch <- 2
ch <- 3
val := <-ch // 受信
// Unbuffered Channel: 送受信で同期
ch := make(chan int)
go func() {
ch <- 1 // ここでブロック(受信者待ち)
}()
val := <-ch // ここで synchronize
Select(複数 Channel の待機)
select {
case val := <-ch1:
fmt.Println("From ch1:", val)
case val := <-ch2:
fmt.Println("From ch2:", val)
case <-timeout:
fmt.Println("Timeout")
}
Rust の Future と async/await
Rust も async/await をサポート。メモリ安全性保証:
async fn fetch_user(id: u32) -> User {
// HTTP リクエスト
let response = http::get(&format!("/users/{}", id)).await;
response.parse()
}
// 使用
let user = fetch_user(123).await;
// 並列実行: join!
let (user, posts) = tokio::join!(
fetch_user(123),
fetch_posts(123)
);
Runtime 選択
Tokio(マルチスレッド):
#[tokio::main]
async fn main() {
tokio::task::spawn(async { /* ... */ }).await;
}
async-std(シングルスレッド or マルチスレッド):
#[async_std::main]
async fn main() {
async_std::task::spawn(async { /* ... */ }).await;
}
Python の asyncio
import asyncio
async def fetch_user(user_id):
await asyncio.sleep(1) # I/O操作のシミュレーション
return f"User {user_id}"
async def main():
# 並列実行
results = await asyncio.gather(
fetch_user(1),
fetch_user(2),
fetch_user(3)
)
print(results)
asyncio.run(main())
GIL の影響: CPU バウンドタスクでは parallel 効果なし。I/O バウンドのみ有効。
Future パターン(Java)
ExecutorService executor = Executors.newFixedThreadPool(4);
// Future: 非同期計算の結果
Future<User> future = executor.submit(() -> {
return fetchUser(123); // バックグラウンド実行
});
User user = future.get(5, TimeUnit.SECONDS); // ブロック待機
CompletableFuture(Java 8+):
CompletableFuture
.supplyAsync(() -> fetchUser(123))
.thenApply(user -> getOrders(user.id))
.thenAccept(orders -> System.out.println(orders))
.exceptionally(ex -> {
ex.printStackTrace();
return null;
});
Actor モデル
概念
Actor = 独立したエンティティ。メッセージ受信 → 状態変更 → メッセージ送信。
Actor A Mailbox Actor B
|<--- Message 1 ---|
|<--- Message 2 ---|
Process Message 1
Send response ---> (別 Mailbox)
特性:
- 独立:各 Actor は独立した state 保持
- 非ブロッキング:メッセージ処理は順序保証
- 分散可能:ネットワーク越しのメッセージ送信可能
Erlang/OTP
元祖 Actor。高可用性が売り:
% Actor 定義
-module(counter).
start() ->
spawn(fun loop/0).
loop() ->
receive
{increment, From} ->
From ! {result, 1},
loop();
{stop, From} ->
From ! stopped
end.
% 使用
Counter = counter:start(),
Counter ! {increment, self()},
receive
{result, Val} -> io:format("Result: ~p~n", [Val])
end.
Akka(JVM 向け Actor Framework)
// Actor クラス定義
class CounterActor extends Actor {
var count = 0
def receive = {
case Increment =>
count += 1
sender() ! Result(count)
case GetCount =>
sender() ! Result(count)
}
}
// 使用
val system = ActorSystem("myapp")
val counter = system.actorOf(Props[CounterActor], "counter")
counter ! Increment
counter ! GetCount
メリット:
- スレッド安全(各 Actor は single-threaded)
- 障害分離(1 つの Actor crash が他に影響小)
- 容易なスケーリング
デメリット:
- デバッグが難しい(分散)
- 「メッセージ喪失」を処理者が対応
CSP モデル(Communicating Sequential Processes)
Actor より同期的。チャネル中心:
Go の例
// 複数 worker で処理
func worker(id int, jobs <-chan int, results chan<- int) {
for job := range jobs {
fmt.Printf("Worker %d processing %d\n", id, job)
time.Sleep(time.Second)
results <- job * 2
}
}
func main() {
jobs := make(chan int, 100)
results := make(chan int, 100)
// 3 worker 起動
for w := 1; w <= 3; w++ {
go worker(w, jobs, results)
}
// ジョブ送信
for j := 1; j <= 10; j++ {
jobs <- j
}
close(jobs)
// 結果受け取り
for a := 0; a < 10; a++ {
<-results
}
}
特性:
- 型安全(チャネル型で制御)
- デッドロック検出容易(channel close で信号)
- クローズゲーティング:channel close ですべての受信者に信号
Actor vs CSP
| 側面 | Actor | CSP |
|---|---|---|
| 通信 | メッセージ(async) | チャネル(sync/async) |
| 状態 | 各 Actor が保持 | 明示的に共有 |
| 障害 | Actor の崩壊で分離 | チャネル close で传播 |
| 学習曲線 | 高 | 中〜低 |
楽観制御と悲観制御
共有データの競合をどう扱うかには、大きく 2 つの方向があります。
- 悲観制御: ぶつかる前提で先にロックする
- 楽観制御: たいていぶつからない前提で最後に検査する
どちらがよいか
一概には言えません。
- 競合が多いなら悲観制御が自然
- 競合が少なく、待ちを減らしたいなら楽観制御が自然
です。
CRDT(Conflict-free Replicated Data Type)
背景と動機
結果整合性では、複数ノードが同じデータを変更すると衝突が起きる:
Node A: value = "Alice"
Node B: value = "Bob"
マージ時:どっちが正しい?
CRDT はこの衝突を 自動的かつ一貫性を保ちながら 解決:
Google Docs: 複数人が同時編集
Yjs: リアルタイムコラボレーション
Apple Notes: オフライン編集のマージ
カウンター CRDT
G-Counter(増加専用)
Replica A: counter_A = 5
Replica B: counter_B = 3
マージ: total = max(counter_A) + max(counter_B)
= 5 + 3 = 8
class GCounter:
def __init__(self, replica_id):
self.value = {replica_id: 0}
def increment(self):
self.value[self.replica_id] += 1
def value_total(self):
return sum(self.value.values())
def merge(self, other):
for replica, count in other.value.items():
self.value[replica] = max(
self.value.get(replica, 0),
count
)
PN-Counter(増減可能)
Positive + Negative カウンタの差:
PN-Counter = G-Counter(positive) - G-Counter(negative)
increment() → G-Counter(positive) += 1
decrement() → G-Counter(negative) += 1
value = sum(positive) - sum(negative)
テキスト CRDT(RGA, YATA)
複数ユーザーが同時編集したテキストをマージ:
User A edits: "Hello" → "Hallo" (e削除, a追加)
User B edits: "Hello" → "Hello!" (!追加)
マージ: "Hallo!" (順序、編集両方反映)
実装:各文字にユニーク ID(replica_id + timestamp)を付加:
文字 H: {replica: A, seq: 0}
文字 e: {replica: A, seq: 1}
文字 l: {replica: A, seq: 2}
文字 l: {replica: A, seq: 3}
文字 o: {replica: A, seq: 4}
User A delete char seq=1:
e の tombstone flag = true
User B insert after o:
! → {replica: B, seq: 1}(クロック独立)
マージ時:
Replica ID + seq で一貫性ある順序を再構築
tombstone=true な文字をスキップ
→ "Hallo!"
OR-Set(Observed-Remove Set)
集合の加算・削除が可換:
Set A:
add('alice', id=A1)
add('bob', id=A2)
State = {alice, bob}
Set B:
remove('alice') ← A から見えていない
State = {}
マージ:
A の state: {(alice, A1), (bob, A2)}
B の tombstone: {A1}
結果: {bob} (tombstone を含むので alice は除去)
class ORSet:
def __init__(self, replica_id):
self.replica_id = replica_id
self.elements = {} # {value: set of (replica, seq)}
self.seq = 0
def add(self, value):
if value not in self.elements:
self.elements[value] = set()
self.seq += 1
self.elements[value].add((self.replica_id, self.seq))
def remove(self, value):
if value in self.elements:
del self.elements[value]
def merge(self, other):
for value, tags in other.elements.items():
if value not in self.elements:
self.elements[value] = set()
self.elements[value].update(tags)
Last-Write-Wins(LWW)
タイムスタンプが最新の値を採用:
Node A: x=1 (timestamp: 1000)
Node B: x=2 (timestamp: 2000)
マージ: x = 2 (2000 > 1000)
問題:因果関係を無視。A の変更が B への変更を誘発した場合でも、LWW は B の值を選ぶ。
アウトボックスとサガ
Outbox パターン
問題:DB 更新とメッセージ送信を同時に成功させたい。2PC(二フェーズコミット)は遅い。
悪いパターン:
DB update ← 成功
Event send ← 失敗(ネットワーク遅延)
→ DB は更新されたが、イベントが配信されない
解決:Outbox テーブルで原子性を確保
1 つのトランザクション:
INSERT INTO users (name) VALUES ('Alice')
INSERT INTO outbox (event_type, data)
VALUES ('user_created', '{"id":123,"name":"Alice"}')
COMMIT
別プロセス(Outbox Poller):
SELECT FROM outbox WHERE processed=false
→ Event 配信
→ UPDATE outbox SET processed=true
CREATE TABLE users (
id BIGINT PRIMARY KEY,
name VARCHAR(255)
);
CREATE TABLE outbox (
id BIGINT PRIMARY KEY AUTO_INCREMENT,
event_type VARCHAR(100),
data JSON,
processed BOOLEAN DEFAULT FALSE,
created_at TIMESTAMP DEFAULT NOW()
);
-- アプリケーション層
BEGIN TRANSACTION;
INSERT INTO users (id, name) VALUES (1, 'Alice');
INSERT INTO outbox (event_type, data)
VALUES ('UserCreated', JSON('{"userId":1,"name":"Alice"}'));
COMMIT;
-- Outbox Poller(別プロセス)
LOOP:
SELECT id, event_type, data FROM outbox WHERE processed=false LIMIT 100;
FOR each event:
publish_to_kafka(event.data);
UPDATE outbox SET processed=true WHERE id IN (...);
特性:
- DB transaction 内で確実に記録
- 後で確実に配信(at-least-once)
- メッセージ喪失を防止
Inbox パターン(受け取り側)
複数サービスからのイベントで重複受け取りを防止:
Event from Service A:
BEGIN
INSERT INTO inbox (event_id, payload) VALUES (event.id, payload)
UPDATE inventory SET quantity = quantity - 1
COMMIT
同じ event が再度来た場合:
Unique Constraint on event_id
→ INSERT fail(安全に無視)
Saga パターン
長い処理を補償可能なステップに分割。分散トランザクション:
注文フロー:
1. 注文作成(Saga start)
2. 支払い処理(Payment Service)
3. 在庫確保(Inventory Service)
4. 配送予約(Shipment Service)
5. メール送信(Email Service)
どこかで失敗 → Compensation(ロールバック):
支払い失敗 → 注文をキャンセル
在庫不足 → 支払いを返金
配送失敗 → 在庫を戻す
Orchestration(直列型)
中央の Saga Orchestrator が各サービスを呼び出し:
Orchestrator
→ Payment Service (call)
← Success: Inventory Service call
→ Inventory Service (call)
← Fail: call Payment.refund()
→ Payment.refund() (compensate)
← Success: Notify User
@Service
public class OrderSagaOrchestrator {
@Transactional
public void createOrder(OrderRequest req) {
Order order = orderRepo.save(new Order(req));
try {
// Step 1: Payment
PaymentResult payment = paymentService.charge(req.amount);
// Step 2: Inventory
inventoryService.reserve(req.items);
// Step 3: Shipment
shipmentService.schedule(order);
order.setStatus(OrderStatus.CONFIRMED);
} catch (Exception e) {
// Compensations
paymentService.refund(order.paymentId);
inventoryService.unreserve(order.items);
order.setStatus(OrderStatus.CANCELLED);
throw new OrderFailedException(e);
}
}
}
Choreography(非直列型)
各サービスが互いにイベント購読。自律的に動作:
Order Service: OrderCreated イベント配信
Payment Service:
(OrderCreated リッスン)
→ 支払い処理
→ PaymentCompleted or PaymentFailed イベント配信
Inventory Service:
(PaymentCompleted リッスン)
→ 在庫確保
→ InventoryReserved or InventoryFailed イベント配信
Shipment Service:
(InventoryReserved リッスン)
→ 配送予約
→ ...
利点:
- Decoupling:各サービスが独立
- Scalability:新しいステップ追加が容易
欠点:
- Complexity:全体フローが不透明
- 循環イベントリスク
一貫性パターン
Outbox + Inbox
Service A:
UPDATE db
INSERT INTO outbox
Outbox Poller:
SELECT FROM outbox
→ Event 配信(at-least-once)
Service B:
Event 受信
BEGIN
INSERT INTO inbox (event_id, data)
UPDATE db (based on event)
COMMIT
同じイベント再配信:
inbox の UNIQUE event_id constraint
→ 重複は自動無視
Change Data Capture(CDC)
DB の変更を自動的にキャプチャ。イベント駆動の実装:
DB Write Log
↓
CDC Engine (Debezium, etc.)
↓
Kafka Topic(Event Stream)
↓
Multiple Services(Subscribe)
Debezium (PostgreSQL 例):
{
"before": {"id": 1, "name": "Alice"},
"after": {"id": 1, "name": "Alicia"},
"source": {
"db": "mydb",
"table": "users",
"lsn": 123456
},
"op": "u", // u=update, c=create, d=delete
"ts_ms": 1629800000000
}
ロックフリーデータ構造
動機と分類
ロックフリー = ロック(mutex)を使わない。より高性能:
Lock-based: 待ち時間あり、スレッド阻害
Lock-free: CAS で retry。待ち時間小、スケーラビリティ高
Wait-free: 最悪ケースでも bounded steps
Wait-Free な操作の特性
定義:各スレッドが有限ステップで必ず完了。他スレッドの遅延に左右されない。
// Lock-free stack(CAS ベース)
void push(Stack *s, int value) {
Node *new = malloc(sizeof(Node));
new->value = value;
while (true) {
Node *old_top = s->top;
new->next = old_top;
// CAS: old_top が変わっていなければ new_top に置き換え
if (CAS(&s->top, old_top, new)) {
return; // 成功
}
// CAS 失敗 → リトライ
}
}
int pop(Stack *s) {
while (true) {
Node *top = s->top;
if (top == NULL) return EMPTY;
if (CAS(&s->top, top, top->next)) {
return top->value; // 成功
}
}
}
問題点:高競合下では CAS リトライが増加(バックオフ必要)
実用的なロックフリーキューの例
Michael & Scott’s Queue(1996):
typedef struct {
Value value;
Node *next;
} Node;
typedef struct {
Node *head;
Node *tail;
} Queue;
void enqueue(Queue *q, Value v) {
Node *new = malloc(sizeof(Node));
new->value = v;
new->next = NULL;
while (true) {
Node *tail = q->tail;
Node *tail_next = tail->next;
// Tail が最新か確認
if (tail == q->tail) {
if (tail_next == NULL) {
// Tail が本当に末尾
if (CAS(&tail->next, NULL, new)) {
CAS(&q->tail, tail, new); // tail 進める(失敗ok)
return;
}
} else {
// Tail が古い → 前へ進める
CAS(&q->tail, tail, tail_next);
}
}
}
}
Value dequeue(Queue *q) {
while (true) {
Node *head = q->head;
Node *tail = q->tail;
Node *head_next = head->next;
if (head == q->head) {
if (head == tail) {
// キューが空またはタイミング的問題
if (head_next == NULL) {
return EMPTY;
}
CAS(&q->tail, tail, head_next);
} else {
Value v = head_next->value;
if (CAS(&q->head, head, head_next)) {
return v;
}
}
}
}
}
実装言語でのロックフリー
Java の AtomicReference
class LockFreeStack<T> {
private AtomicReference<Node<T>> top = new AtomicReference<>();
public void push(T value) {
Node<T> newNode = new Node<>(value);
while (true) {
Node<T> oldTop = top.get();
newNode.next = oldTop;
if (top.compareAndSet(oldTop, newNode)) {
return;
}
}
}
public T pop() {
while (true) {
Node<T> oldTop = top.get();
if (oldTop == null) return null;
if (top.compareAndSet(oldTop, oldTop.next)) {
return oldTop.value;
}
}
}
}
Rust の AtomicPtr
use std::sync::atomic::{AtomicPtr, Ordering};
use std::ptr;
struct LockFreeStack<T> {
top: AtomicPtr<Node<T>>,
}
impl<T> LockFreeStack<T> {
fn push(&self, value: T) {
let new = Box::into_raw(Box::new(Node { value, next: ptr::null_mut() }));
loop {
let old_top = self.top.load(Ordering::Relaxed);
unsafe { (*new).next = old_top; }
match self.top.compare_exchange(
old_top,
new,
Ordering::Release,
Ordering::Relaxed,
) {
Ok(_) => return,
Err(_) => {}
}
}
}
}
ロックフリー vs ロック付き
| 観点 | ロックフリー | ロック付き |
|---|---|---|
| スケーラビリティ | ◎(低競合) | △(高競合時) |
| 遅延 | 低 | 高(待ち) |
| キャッシュ効率 | △(CAS retry) | ○ |
| 実装複雑度 | 高 | 低 |
| デバッグ | 難しい | 容易 |
| 本番推奨 | 高性能必須時のみ | 一般的 |
分散ストレージシステム
Dynamo(Amazon, 2007)
設計目標:高可用性、最終整合性。スケーラビリティ。
主な特性
Consistent Hashing:ノード追加/削除時に最小限のデータ移動
ハッシュリング:
Node 1 (0-100)
↗ ↖
Node 3 Node 2
(200-300) (100-200)
キー "foo": hash(foo) = 50 → Node 1 が担当
Quorum ベースレプリケーション:
N = 3 (レプリケーション係数)
R = 2 (読み取り quorum)
W = 2 (書き込み quorum)
write: 2 ノード以上成功で OK
read: 2 ノード以上から取得、conflict resolution
R + W > N を満たすと strongness が向上
例: 2 + 2 > 3 → Strong Consistency に近い
Vector Clocks:因果順序の追跡
Server A puts(key, value_v1): [A:1]
Server B puts(key, value_v2): [A:1, B:1]
並列更新時: 衝突(conflict)
value_v1 と value_v2 両方保存
クライアントが解決(例:merge)
Cassandra(Apache)
Dynamo に影響されつつ、自社改善。Twitter, Netflix で使用。
特性
Row-based vs Column-based:
Row Store (MySQL): 行を整列(OLTP向け)
Column Store (Cassandra): 列を整列(OLAP向け)
Partitioning + Replication:
Primary Key = Partition Key + Clustering Key
例:
Partition Key: user_id
Clustering Key: timestamp
SELECT * FROM events WHERE user_id = 123 AND timestamp > 2024-01-01
→ Partition 123 内で timestamp 範囲検索
Read Repair & Anti-Entropy:
読み取り時:
複数レプリカから読み → バージョン最新の返却
古いレプリカに最新版を write back(Read Repair)
バックグラウンド:
Merkle tree で全レプリカを定期比較
差分を検出・修復(Anti-Entropy)
Google Spanner
同期レプリケーション + 外部一貫性。TrueTime API。
Strong Consistency + Horizontal Scalability
↓
TrueTime API で多地域レプリケーション
TrueTime の利用
write(key, value) at t1:
TrueTime.now() = [t1_early, t1_late]
Timestamp = t1_late
read(key) at t2:
TrueTime.now() = [t2_early, t2_late]
if t2_early > t1_late:
→ write は確実に完了
→ 読み取り値は最新
レプリカ間のタイムスタンプ同期により Linearizability 実現。
CockroachDB
Spanner に影響されつつ、オープンソース。
// CockroachDB クライアント(Go)
client := crdb.Open("postgresql://localhost:26257/...")
err := crdb.ExecuteTx(ctx, client, func(tx *sql.Tx) error {
// トランザクション内の操作
// Serializable Isolation Level(強い一貫性)
_, err := tx.ExecContext(ctx, "UPDATE account SET balance = balance - ? WHERE id = ?", amount, from_id)
if err != nil {
return err
}
_, err = tx.ExecContext(ctx, "UPDATE account SET balance = balance + ? WHERE id = ?", amount, to_id)
return err
})
特性:
- SQL インターフェース
- ACID トランザクション
- 地理的分散対応
Redis
インメモリストア。遅延小、スルー高。
データ構造
String: key-value(キャッシュ)
List: queue(ジョブキュー)
Set: 一意要素(ユーザーID集合)
Sorted Set: ランキング(スコア付き順序)
Hash: object(user profile)
Stream: イベントストリーム(Kafka的)
Replication & Persistence
Replication:
Master (write)
→ Slave (read-only, async)
Persistence:
RDB: スナップショット(起動速い)
AOF: Append-Only File(遅延小だが遅い)
Redis Cluster
TiKV(PingCAP)
分散トランザクショナルストア。TiDB の基盤。
Region-based partitioning:
大量のキー→ Region へ分割
各 Region は Raft で複製
Key: 0-100 Key: 100-200 Key: 200-300
Region A (Raft) Region B (Raft) Region C (Raft)
設計原則として見る分散
分散システムでは、「速そうだから分ける」ではなく、
- 境界を分ける価値があるか
- 故障時にどう観測し、どう戻すか
- 再試行と重複をどう吸収するか
- どこまで一貫性を求めるか
を先に考えるべきです。
境界を増やすコスト
サービス境界を増やすと、
- 通信失敗
- 観測の難しさ
- デプロイ調整
- データ不一致
が増えます。分割には利益もありますが、常に複雑さの代償がつきます。
比較で理解する
同期処理と非同期処理
- 同期: その場で結果を待つ
- 非同期: 受け渡して後で進める
応答時間と一貫性の見え方が変わるので、単なる性能テクニックではありません。
楽観ロックと悲観ロック
- 楽観: ぶつからない前提で最後に検査する
- 悲観: ぶつかる前提で先に押さえる
競合頻度と待ちの許容度で向き不向きが変わります。
判断の指針
並行性や分散で迷ったときは、
- そもそも分ける必要があるか
- 順序保証は必要か
- 再試行は起こる前提か
- 重複実行を吸収できるか
- 障害時にどこまで不一致を許せるか
を見ると、過剰設計を減らしやすいです。
典型的な判断例
- ユーザー応答を速くしたい: 非同期化を考える
- 決済のように重複が危険: 冪等性や補償を強く考える
- 単一ノードで足りる: 無理に分散しない
実務ミニケース
メール送信を同期でやって遅い
キューへ積んで非同期化すると、ユーザー応答を速くしやすくなります。ただし重複送信対策が必要です。
在庫更新がたまにずれる
ロック、トランザクション、冪等キー、楽観ロックなど、どこで整合性を持つかを決める必要があります。
障害後にノードごとで値が違う
ログ複製、リーダー切替、古いリーダー、コミット境界の理解が必要になります。
FAQ
分散にすれば速くなるのか
速くなる可能性はありますが、通信、同期、再試行、整合性のコストも入ります。単一ノードで十分な問題まで分散にすると、むしろ難しくなります。
ロックをなくせば正しいか
いいえ。ロックを減らせても、原子性や順序の問題は別の形で残ります。メッセージングや楽観制御も万能ではありません。
CAP で C を捨てたら何でも速いのか
そう単純ではありません。古い値を許す設計にはアプリ側の整合性戦略が要り、運用も難しくなります。
ミニ比較表
| 概念 | 何を扱うか | よくある混同 |
|---|---|---|
| 並行性 | 重なって進む実行 | 並列性と同じだと思う |
| ロック | 共有資源の排他 | 正しさの万能薬だと思う |
| 冪等性 | 再試行時の重複吸収 | 失敗しないことだと思う |
| キュー | 仕事の受け渡し | ストリームと同じだと思う |
| ストリーム | イベントの継続的な流れ | 単なるジョブキューだと思う |
| 合意形成 | 順序や採用内容をそろえる | 単なる多数決だと思う |
練習問題
- 並行性と並列性の違いを、自分の言葉で説明してください。
- Exactly Once が難しい理由を、通信失敗の観点から説明してください。
- キューとストリームのどちらが向くか、メール送信と監視ログ収集で答えてください。
章末ミニテスト
- 在庫更新 API で二重実行を防ぐために、冪等性をどう設計するか説明してください。
- CAP を「分断が起きたときの選択」として短く説明してください。
- キューを入れることで得られる利点と、新しく持ち込まれる難しさを 1 つずつ挙げてください。
ケーススタディ
同じメールが二重送信される
アプリから見ると「失敗したからもう一度送った」だけでも、相手側では最初の処理がすでに終わっていたかもしれません。ここで冪等性キーや重複抑止の設計が効きます。
注文確定と在庫更新が別サービス
片方だけ成功して片方が失敗する可能性があるので、単一 DB のトランザクション感覚が通用しません。アウトボックスやサガの考え方が必要になります。
解答の考え方
練習問題 1 の考え方
重なって進むことと、本当に同時に別コアで走ることを分けて言えると強いです。
練習問題 2 の考え方
「実行されたか」「返事が返ったか」が分離している、という点を押さえると説明しやすいです。
練習問題 3 の考え方
一回きりの仕事の引き渡しか、継続的イベントの流れか、という用途差で考えると整理できます。
よくある失敗パターン
単一ノード感覚のまま分散化する
「DB を更新してからメッセージを送る」をそのまま複数サービスへ持ち込むと、境界で失敗しやすくなります。
再試行すれば安全になると思う
重複実行、順序逆転、負荷増幅の問題が出ます。
CAP をスローガンとしてだけ使う
分断時に何を優先するか、という具体的な設計判断へ落とさないと役に立ちません。
コラム
分散システムは「不確実さを飼いならす学問」
遅い、落ちる、返事が消える、順番が前後する。そういう不確実さを前提にして、それでも全体を破綻させない工夫の集まりです。
学習ロードマップ
学ぶ順番
- 並行性と競合
- ロックとデッドロック
- 分散で増える失敗の種類
- CAP と合意形成
- ログ複製
- 冪等性と再試行
- キュー / ストリーム
- 楽観制御、アウトボックス、サガ
この順番にすると、単一プロセスの難しさから分散の難しさへ自然に広がります。
どこで詰まりやすいか
- 並行と並列を混同する
- ロックで全部解決できると思う
- 分散を性能改善の道具としてだけ見る
- 冪等性を「失敗しないこと」だと誤解する
実務での見方
非同期化を入れる前に
- 何を非同期にしたいのか
- 順序は要るか
- 再試行してよいか
- 重複を吸収できるか
を決めないと、ただ複雑になることがあります。
サービス分割の判断に効く
分散システムの知識は、マイクロサービスを増やす理由を考えるときにも効きます。分けるほど通信、整合性、監視、障害対応のコストが増えるからです。
実務チェックリスト
- 同期化の対象を最小化できているか
- 再試行と重複対策をセットで考えているか
- 順序保証が必要かを言語化しているか
- 単一ノードで済む問題を無理に分散化していないか
- 非同期化で失う一貫性を把握しているか
模範解答例
例: Exactly Once が難しい理由
送信側から見ると失敗に見えても、受信側では処理済みかもしれません。通信失敗と処理失敗が一致しないため、重複実行を完全になくすのは難しく、冪等性や重複抑止が重要になります。
例: キューとストリームの違い
キューは仕事を受け渡して消費する感覚で、ストリームはイベントの流れを継続的に複数の読者が扱う感覚です。用途が違うので、同じ基盤でも設計が変わります。
章末まとめ
- 並行性は速さだけでなく、順序不確定と競合を持ち込む
- 分散では遅延、故障、不一致、再試行が前提になる
- CAP や合意形成は「分断や不一致にどう向き合うか」の道具
- 冪等性は再試行世界の中核概念
- アウトボックスやサガは複数システムをまたぐ処理の実務的な工夫
次に読むなら
何に使うか
- ジョブキュー設計
- マイクロサービスの再試行や二重実行対策
- 分散システムの一貫性と可用性の議論
何に似ているか
分散システムは、離れた支店どうしで同じ台帳をそろえ続ける仕事に似ています。遅延、聞き違い、欠席、重複連絡が前提になります。
小さな題材
- ジョブキューで非同期メール送信を作る
- 冪等キーつき API を設計する
- Redis と DB の併用で整合性の難しさを見る
ロックフリーとコンセンサス階層
Herlihy-Wing 計算論的階層
すべての共有データ構造を「いくつのスレッドで wait-free 実現可能か」で分類:
Consensus Number:
0: アトミック読み書き(1スレッドのみ)
1: Test-and-Set, Compare-And-Swap
∞: Monitor, Mutex(任意数)
定理:Consensus Number n の primitive では n スレッドまで wait-free construct 可能。
CAS は Consensus Number 無限 → wait-free stack, queue, etc. 実装可能
Observability パターン
分散システムは不透明。観測が重要:
分散トレーシング(Distributed Tracing)
Jaeger, Zipkin, Datadog APM など:
各スパンにメタデータ(duration、status、tags)を記録。全体の critical path を分析。
Causal Profiling
Perf Predict や LPerfTool で、どの操作が全体の遅延に影響しているかを検出:
Observation: Service が遅い
Causal profiling:
Operation X の delay を +10% にしてシミュレート
→ Overall latency へのインパクト測定
→ Operation X が critical path
2025-2026 の動向
HotStuff(Yin et al., 2018)
ビザンチン fault tolerant の新世代。BFT Raft。
従来 BFT: O(n²) メッセージ複雑度
HotStuff: O(n) 複雑度 + パイプライン化で高スループット
採用例: Aptos, Sui(Move言語 blockchain)
CRDT の実践化
Google Docs, Apple Notes, VS Code Live Share:リアルタイムコラボレーション。
CRDT ライブラリ:
- Yjs (JavaScript)
- Automerge (JS, Rust)
- CRDTs.jl (Julia)
- Yi (Rust)
Async Runtime の進化
Tokio(Rust)、async-std の最適化。ブロッキング I/O の非同期化(io_uring ベース)。
Event Sourcing と CQRS の確立
Axon Framework, EventStoreDB、AWS EventBridge で主流化。
Event Sourcing: 状態ではなく事象を保存
CQRS: Command(書き込み)と Query(読み取り)を分離
→ スケーラビリティ、監査性向上
eBPF による可観測性
Linux カーネル内で任意コード実行。低オーバーヘッド観測:
従来: User space で trace → kernel context switch overhead
eBPF: Kernel space で直接 trace → overhead 小
利用: Cilium(ネットワークセキュリティ)、Datadog Agent
WebAssembly(WASM)の台頭
言語中立なバイナリ。サーバーサイドでの利用も。
Wasmtime, Wasmer: WASM runtime
→ Safe multi-tenant execution
→ Cloudflare Workers, Fastly でサーバー処理
実務チェックリスト拡張
並行性設計
- [ ] 共有状態の最小化を検討したか
- [ ] ロック粒度を決めたか(粗 vs 細)
- [ ] メモリオーダリングを考慮したか
- [ ] デッドロック検出・回避戦略を定めたか
- [ ] スレッドプールのサイズ決定ロジックがあるか
- [ ] スレッドローカルストレージの必要性を判断したか
分散システム設計
- [ ] 一貫性要件を明記したか(Linearizable? Eventually consistent?)
- [ ] リーダー選出とリーダー失敗時の振る舞いを定義したか
- [ ] Quorum サイズを決定したか
- [ ] ネットワーク分断検出・対応策を用意したか
- [ ] Idempotency key の仕様を定義したか
- [ ] 再試行戦略(指数バックオフ、jitter)を決めたか
- [ ] Outbox/Inbox パターンの導入を検討したか
- [ ] 分散トランザクション(Saga)の必要性を判断したか
データベース・ストレージ
- [ ] シングルマシンで十分かを評価したか
- [ ] レプリケーション方式を選択したか(Raft, 非同期, 同期)
- [ ] スナップショット + ログリプレイ戦略を定めたか
- [ ] Read Repair / Anti-Entropy の方針を決めたか
- [ ] TTL(Time-To-Live)やデータ削除ポリシーを定義したか
メッセージング・キュー
- [ ] キューかストリームか判定したか
- [ ] 配信保証(at-most-once, at-least-once, exactly-once)を決めたか
- [ ] Dead Letter Queue の運用方法を決めたか
- [ ] バックプレッシャーハンドリングを実装したか
- [ ] Consumer offset 管理戦略を定めたか
観測性・運用
- [ ] 分散トレーシング基盤を導入したか
- [ ] ログ収集・集約方針を定めたか
- [ ] メトリクス(RED: Rate, Errors, Duration)を定義したか
- [ ] アラート閾値とエスカレーション手順を定めたか
- [ ] カオスエンジニアリングテストを計画したか
セキュリティ
- [ ] ネットワーク暗号化(TLS)を必須としたか
- [ ] 認証・認可方式を定めたか(JWT, OAuth, mTLS)
- [ ] キー管理・ローテーション戦略を定めたか
- [ ] Gossip プロトコル時の中間者攻撃対策を考慮したか
- [ ] 監査ログの保存・アクセス制御を設定したか
学習ロードマップ(詳細版)
Phase 1: 基礎(1-2週間)
- 並行性と並列性の違い
- スレッド、プロセス、タイムスライシング
- レースコンディションの理解
- ロック、Mutex の基本
- デッドロックの 4 条件
実習:シングルマシンの競合状態を実装・デバッグ
Phase 2: 並行プログラミング(2-3週間)
- セマフォ、条件変数、RW ロック
- アトミック操作と CAS
- メモリオーダリング(SC, TSO, Acquire-Release)
- ロックフリーデータ構造(stack, queue)
- async/await と Promise
実習:Go goroutine / Rust async でコンカレント fetch
Phase 3: 分散入門(2週間)
- ネットワーク遅延と障害モデル
- Lamport クロック、ベクタークロック
- CAP 定理と一貫性モデル
- 状態機械複製
- ログ複製
実習:Raft ゼロからの実装(難易度高)
Phase 4: 合意形成(2-3週間)
- Raft アルゴリズム詳細
- Paxos の理解
- リーダー選出と Split Brain
- スナップショットとログ圧縮
- Quorum と遅延ノード対応
実習:etcd / Consul の動作確認と簡単な分散 app
Phase 5: 実装パターン(2週間)
- 冪等性と再試行
- Outbox/Inbox パターン
- Saga(Orchestration vs Choreography)
- CRDT(OR-Set, LWW)
- イベントソーシング
実習:マイクロサービス間の saga 実装
Phase 6: ストレージと高度なトピック(2-3週間)
- 分散トランザクション(2PC, 3PC)
- 分散ストレージ(Dynamo, Cassandra, Spanner)
- ロックフリーキューの実装詳細
- Change Data Capture(CDC)
- HotStuff と次世代 BFT
実習:Redis Cluster / CockroachDB の構築・運用
実務ケーススタディ(詳細)
ケース 1: オンライン決済システム
要件:
- 一度の決済は絶対に二重実行されない
- マイクロサービス(決済、在庫、配送)
- 部分故障対応
設計:
1. 冪等キー + Outbox で注文受け取り
2. Saga Orchestration で複数サービス呼び出し
3. Payment Service: 決済は idempotent key で二重実行防止
4. 各ステップで補償戦略(refund, cancel)
5. 分散トレーシングで全体フロー観測
ケース 2: リアルタイムデータパイプライン
要件:
- 低遅延(< 100ms)
- 高スループット(millions msgs/sec)
- Exactly-once 処理保証
設計:
Source (API) → Kafka (at-least-once 配信)
→ Flink (Exactly-once processing)
→ State Backend (RocksDB)
→ Sink (Elasticsearch)
Watermark: イベント時刻 - 5秒(遅延データ許容)
ケース 3: 地理的に分散したデータベース
要件:
- 複数地域でのレプリケーション
- 強い一貫性
- Split brain 防止
設計:
Primary (East region)
↓ (同期レプリケーション Raft)
Secondary (West region)
↓ (Raft)
Tertiary (Asia region)
Quorum = 3, Write quorum = 2 (Primary + 1)
読み取り: Primary(新)or Secondary(若干古)
故障時:Majority (2個) で継続
FAQ(詳細版)
Q: 何個のレプリカが必要?
A: Fault tolerance を考えると:
- 1 故障許容 (f=1) → Quorum = 3 必要 (2f+1)
- 2 故障許容 (f=2) → Quorum = 5 必要
- 遅延ノード容認 (non-Byzantine) → N = 2f+1
3-node Raft: 1ノード障害時も majority (2) 維持
5-node Raft: 2ノード障害まで対応
7-node 以上は diminishing return
Q: Async/await で並列度がどう変わる?
A: 言語・runtime 依存:
JavaScript (Node.js): single-threaded event loop
→ 多数の async 関数でも CPU は 1 個
→ I/O バウンド限定
Go: M goroutines on N OS threads
→ goroutine 数 = CPU-bound + I/O-bound
→ 数千 goroutines 同時実行可能
Tokio (Rust): configurable thread pool
→ 4 cpus で 4 worker threads
→ 数万 tasks 同時スケジュール
Q: Raft vs Paxos、どちらを選ぶ?
A:
Raft:
+ 理解しやすい
+ 実装シンプル
+ etcd, Consul, TiKV で実績
→ 一般的な選択
Paxos:
+ 歴史と理論的確実性
+ Google Chubby の信頼性
+ Multi-Paxos で高度な制御可能
→ エンタープライズ・金融系
実務: Raft で OK。必要なら Paxos へ移行
Q: CAP で C を選ぶとどうなる?
A: 分断時は応答を止める:
正常時: 即座に応答、強い一貫性
分断時: write 受け付けない(only read)
→ ユーザーに impact
Golden rule:
P(分割耐性)は選択肢ではなく前提
分断時は C vs A トレードオフ
→ 金融: C 優先、E-commerce: A 優先
Q: Event Sourcing は必ずやるべき?
A: 選択肢:
不要な場面:
- 単純な CRUD (blog, todo list)
- 監査ログ不要
- イベント駆動でない
有効な場面:
- 複雑なビジネスロジック
- 監査・コンプライアンス要求
- リアルタイムイベント駆動
- タイムトラベル(状態を過去時点で復元)
→ 必ずではなく、ビジネス要件で判断
最後に
並行性と分散システムはエンジニアの最難関スキルの 1 つです。
- 単一マシン感覚が通じない
- 本番環境でしか再現しないバグ
- トレードオフの選択の連続
ただし理解すると:
- より自信を持ってシステム設計できる
- 複雑なバグ をデバッグ・予防できる
- パフォーマンスの限界が見える
- チーム全体の技術レベルが向上
推奨学習:
- 理論(本教科書)
- 実装(MIT 6.5840 lab)
- 本番運用(実務プロジェクト)
頑張ってください!
補足
第9章 並行性と分散システム
この章が実務で役立つ場面
- バックグラウンドジョブやメッセージキュー設計
- 二重実行、競合状態、デッドロックの調査
- 分散システムでのリトライ、一貫性、可用性の判断
9.1 並行性
複数の処理が重なって進むことです。高速化だけでなく、応答性向上のためにも使います。
9.2 競合状態
複数の実行主体が同じデータへ同時アクセスすると、順番によって結果が変わることがあります。
9.3 ロック
共有資源へ安全にアクセスするための仕組みです。
ただし、ロックは
- デッドロック
- 性能低下
- 待ち
も生みます。
9.4 デッドロック
互いに相手の資源待ちになって止まる状態です。
【図27】デッドロックの発生パターン:
9.5 分散システム
複数のコンピュータでひとつのシステムを作ると、
- 故障
- 通信遅延
- 部分的な不一致
が前提になります。
9.6 なぜ難しいか
1台の中ではメモリ共有で済んだことが、ネットワーク越しでは急に難しくなります。
【図28】単一マシンと分散システムの違い:
9.7 一貫性と可用性
分散では、
- すぐに全ノードが同じ状態になるか
- 障害時にも応答を返すか
の両立が難しい場面があります。
CAP 定理(Brewer 2000、Gilbert-Lynch 2002)
分散システムで、以下の 3 つを同時に満たすことはできない:
- C (Consistency):全ノードで同じ値が見える
- A (Availability):全リクエストに応答する
- P (Partition tolerance):ネットワーク分断に耐える
実システムではネットワーク分断は避けられないので、CP(整合性優先) または AP(可用性優先) を選ぶ。例:銀行は CP、SNS タイムラインは AP。
【図28-2】CAP の考え方:
合意アルゴリズム
複数ノードで「同じ順序で状態を変える」合意をとる仕組み:
- Paxos(Lamport 1989):原典、難解で有名
- Raft(Ongaro 2014):Paxos を分かりやすくした、etcd / Consul / TiKV 採用
- Zab(Apache ZooKeeper):Paxos 派生
- PBFT(1999):ビザンチン耐性(悪意ノード耐性)
- HotStuff / Tendermint:ブロックチェーン向け BFT
9.7.2 リーダー選出は何を楽にするか
分散システムでは、全員が同時に勝手な順序で更新を決めると混乱しやすくなります。そこで、ある時点では 1 台を リーダー として扱い、更新の順序づけを集約することがあります。
リーダー選出の利点は、
- 書き込み順序をまとめやすい
- 競合解決の窓口を減らせる
- 状態複製を理解しやすい
ことです。
一方で、リーダー障害時の切り替え、スプリットブレイン防止、多数決の扱いなど、新しい難しさも生まれます。
9.7.3 ログ複製という見方
Raft などの合意アルゴリズムを理解するときは、「値そのものを合わせる」というより、同じ順序のログを共有する と考えると見通しがよくなります。
各ノードが同じ順番で
- コマンドを受け取り
- ログへ積み
- コミットし
- 状態機械へ適用する
なら、最終状態もそろいやすくなります。
この見方は、分散システムを「魔法の同期装置」ではなく、「順序をそろえる工夫の集まり」として理解する助けになります。
9.7.1 分散システムでの「時間」
分散システムでは、絶対時刻に頼れない。代わりに:
- Lamport clock:論理時刻(順序のみ)
- Vector clock:因果関係を保持
- Hybrid Logical Clock (HLC):物理 + 論理、CockroachDB などで採用
- TrueTime(Google Spanner):GPS と原子時計で不確実性区間つき時刻
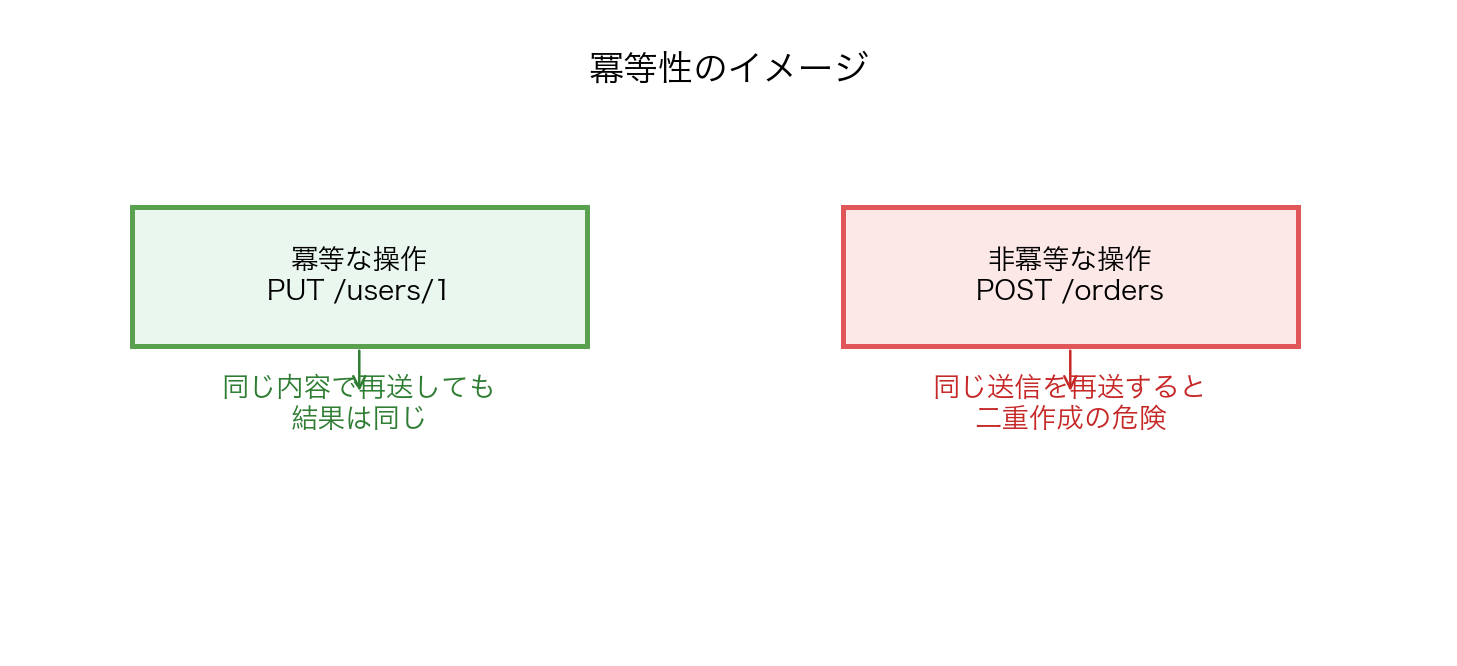
9.8 冪等性
同じ操作を複数回行っても結果が変わらない性質です。再試行がある世界ではとても重要です。
【図28-3】冪等な操作と非冪等な操作:
9.8.1 「Exactly Once」はなぜ難しいか
分散システムでよく出る理想が「必ず1回だけ実行したい」です。ただし実際には、
- 送ったが応答が返らなかった
- 相手は実行したが、こちらは失敗と思った
- 再試行したら二重実行になった
という曖昧さが常にあります。
そのため実務では、
- at-most-once
- at-least-once
- できるだけ冪等に設計する
という発想で扱うことが多いです。Exactly once は魔法のスイッチではなく、強い前提や追加設計のうえで近づける目標だと見るのが現実的です。
9.9 ミニ比較表
| 概念 | 単一マシン | 分散システム |
|---|---|---|
| 共有 | メモリ共有 | 通信で共有 |
| 障害 | 比較的局所 | 部分故障が普通 |
| 遅延 | 小さい | 無視できない |
| 一貫性 | 保ちやすい | トレードオフが出る |
9.10 よくある誤解
9.11 例題
例題1: 同じカウンタを2つのスレッドが同時に更新すると危ないのはなぜか。
解説: 更新順序によって結果が変わる競合状態が起こりうるからです。
例題2: 分散システムで再試行が重要になる理由を述べよ。
解説: 通信失敗や一時的障害が起こるので、1回で成功する前提にできないからです。
9.12 練習問題
- 互いに相手のロック待ちで止まる状態を何というか。
- 同じ操作を何度しても結果が変わらない性質を何というか。
- 分散システムで難しさを増す要因を2つ挙げよ。
9.13 練習問題の答え
- デッドロック
- 冪等性
- 例: 故障、遅延、再試行、不一致
まとめ
並行性と分散システムでは、速さだけでなく、競合、遅延、故障、不一致も同時に扱う必要があります。冪等性、再試行、順序づけ、合意形成を軸にすると、難しさの正体が見えやすくなります。