アルゴリズムとデータ構造
概要
手順・置き方・代表アルゴリズムをまとめて学ぶ
このノートは、もともと分かれていた 代表的なアルゴリズム総覧 と アルゴリズムとデータ構造テキスト を統合した総合版です。
- 前半では、計算量・探索・ソート・グラフ・動的計画法など、代表的アルゴリズムを図と一緒に学びます。
- 後半では、配列・木・ハッシュテーブル・Union-Find など、データ構造と実装の見方を補います。
- つまり、どう解くか と どう置くか を一冊で往復できる形です。
この章で重視すること
- 「速いアルゴリズム」と「向いているデータ構造」を切り離さずに考える
- Big-O を記号ではなく増え方の直感として理解する
- グラフや木のアルゴリズムを、答えたい問いごとに整理する
目次
- 全体像
- アルゴリズムとは
- 計算量
- データ構造の基本
- 木とグラフの表現
- 代表的なアルゴリズム
- 探索・検索アルゴリズム
- ソートアルゴリズム
- グラフアルゴリズム
- 設計パラダイム別のアルゴリズム
- 文字列アルゴリズム
- データ構造と強く結びつくアルゴリズム
- どのアルゴリズムを選ぶか
- 乱択・近似・ヒューリスティクス
- 数値・数論・変換アルゴリズム
- 模擬問題
- 実務ケーススタディ
- 発展ルート
- FAQ
- 参考文献・リンク集
全体像
まずは、アルゴリズムを大づかみに整理しておきます。
アルゴリズムは大きく分けると次のように整理できます。
まず覚えるとよい代表選手
| 分野 | まず覚える代表アルゴリズム |
|---|---|
| 探索 | 線形探索、二分探索 |
| ソート | マージソート、クイックソート、ヒープソート |
| グラフ | BFS、DFS、Dijkstra、Kruskal |
| 設計パラダイム | 分割統治、動的計画法、貪欲法 |
| 文字列 | KMP、Trie |
| 集合管理 | Union-Find |
アルゴリズムとは
アルゴリズムは、問題を解くための明確で実行可能な手順です。レシピに似ていますが、コンピュータでは曖昧さが許されません。
例: 配列から最大値を探す
def find_max(arr):
max_val = arr[0]
for i in range(1, len(arr)):
if arr[i] > max_val:
max_val = arr[i]
return max_val
このアルゴリズムは、先頭を仮の最大値にし、残りを順に見て、より大きければ更新します。簡潔に見えますが、実は多くの重要な性質を持っています。
アルゴリズムの歴史背景
「アルゴリズム」という言葉は、9 世紀のペルシャの数学者アル=フワーリズミー(al-Khwarizmi)の名前に由来します。彼は線形方程式の解き方を体系的に記述しました。その著作「アル・クターブ・アル・ムフタサル・フィー・ヒサーブ・アル・ジャブル・ワル・ムカーバラ」は、後にラテン語で「Algoritmi」と訳され、やがて「Algorithm」という言葉が生まれました。
計算可能性理論の観点から見ると、アルゴリズムは 決定可能問題 に対応します。チューリング機械やラムダ計算により、「計算可能とは何か」が形式化されました。すべての問題に対して解くアルゴリズムが存在するわけではなく、停止問題のように決定不能な問題も存在します。
正しさと速さは別の軸
アルゴリズムを学び始めると、つい「速いかどうか」ばかりに目が向きます。でも実際には、
- まず 正しいこと
- その上で 十分速いこと
- さらに 実装しやすいこと
の 3 つのバランスを見る必要があります。
正しくない高速化は意味がありませんし、逆に正しいだけで極端に遅いと現実の入力では使えません。アルゴリズム設計は、正しさ・速さ・実装しやすさ のバランスを見る営みです。
さらに進むと、「そもそも一般に速く解ける問題なのか」「万能な手続きが存在するのか」という問いにぶつかります。その先は 計算可能性と計算量 で扱います。
アルゴリズムの正当性の証明
アルゴリズムが正しいことを示すには、通常は 不変条件 を用いた帰納法を使います。
例えば、配列から最大値を見つけるアルゴリズムでは:
不変条件: ループの i 番目のステップの開始時点で、 には arr[0] から arr[i-1] までの最大値が格納されている。
初期条件: i=1 のとき、max_val = arr[0] であり、これは arr[0] までの最大値です(真)。
帰納ステップ: i で不変条件が真と仮定すると、max_val = max(arr[0], …, arr[i-1])。i+1 では、arr[i] を見て max(max_val, arr[i]) と更新するので、新しい max_val = max(arr[0], …, arr[i])。
終了条件: ループ終了時 i=n のとき、max_val = max(arr[0], …, arr[n-1])(最大値)。
何に似ているか
アルゴリズムは、ゴールまでの道順そのものです。データ構造は、その道順をスムーズに歩けるように道具や荷物を配置する工夫にあたります。速い道を歩くには、歩きやすい靴(データ構造)と目的地への最短ルート(アルゴリズム)の両方が必要です。
計算量
正しいだけでは足りず、どれくらい効率よく解けるかも重要です。
- 時間計算量: 実行時間がどう増えるか
- 空間計算量: メモリ使用量がどう増えるか
ここでは主に あるアルゴリズム の増え方を見ます。問題クラス全体としての難しさや、P、NP、決定不能性 へ進むときは 計算可能性と計算量 が次の段階です。
計算量記法の詳細
O(ビッグオー)記法
は「入力サイズ n に対して、実行ステップ数は f(n) 程度以下で抑えられる」という意味です。正式には:
ある正の定数 c と が存在して、すべての に対して、実行ステップ数
例:
- は n に比例する増え方
- は n×log(n) に比例する増え方
- は指数関数的に増える
Ω(ビッグオメガ)記法
Ω(f(n)) は「実行ステップ数は f(n) 程度以上かかる」という下界を表します。最悪でも必要なステップ数を示します。
Θ(シータ)記法
Θ(f(n)) は「実行ステップ数は正確に f(n) 程度」という意味です。上界と下界が等しいとき、Θ で表します。
Big-O の直感
Big-O は「今の秒数」ではなく、「大きくなったらどう悪化するか」を見る道具です。
実務的には:
- n = 10^8 のとき、 は数秒、 は数日かかる
- n = 1000 のとき、 は秒単位、 は不可能
最悪・平均・ならし計算量
計算量には見方がいくつかあります。
最悪計算量(Worst-case): いちばんつらい入力でどれくらいか
- 例:線形探索で目的要素が最後尾にある場合 → O(n)
平均計算量(Average-case): すべての入力に対して平均的にはどれくらいか
- 例:ハッシュテーブルで要素が散らばっている場合 → O(1) 平均
ならし計算量(Amortized complexity): 長く使った平均ではどれくらいか
- 例:動的配列の append は O(1) ならし(たまに再割り当てがあるが、長期的には O(1))
ハッシュテーブルは平均では非常に速いですが、衝突の偏りが極端なら悪化しえます。一方、平衡木は平均だけでなく最悪でもある程度読めます。ここが「何を保証したいか」の違いです。
ならし計算量の詳細
毎回は高くないが、たまに重い処理を平均的に見る考え方です。動的配列の append を例に説明します。
class DynamicArray:
def __init__(self):
self.data = []
self.capacity = 1
self.size = 0
def append(self, value):
if self.size == self.capacity:
# 容量が満杯なら 2 倍に拡張
new_data = [0] * (self.capacity * 2)
for i in range(self.size):
new_data[i] = self.data[i]
self.data = new_data
self.capacity *= 2
self.data[self.size] = value
self.size += 1
- 通常の append:O(1)
- 容量満杯のときの append:O(n)(全要素をコピー)
n 回の append をすると、総コスト ≈ n + (n/2 + n/4 + … ) ≈ 2n = O(n)。 1 回あたり平均 O(n)/n = O(1)。
定数倍を軽視しすぎない
Big-O は便利ですが、それだけで勝負が決まるわけではありません。
2,000,000 * n vs 100 * n^2
n < 20,000 なら前者が遅い場合があります。
- 小さな入力なら単純な実装が速いことがある
- メモリアクセスの局所性で実時間がかなり変わる(キャッシュヒット率)
- ライブラリ実装はキャッシュや分岐予測まで考えていることがある
実務では、理論の形と測定の両方を見るのが自然です。
空間計算量
時間と同様に、メモリ使用量も重要です。
- 空間:定数量のメモリのみ(in-place ソート)
- 空間:入力に比例するメモリ(新しい配列を作る)
- 空間:再帰スタック(二分探索、二分木の高さ)
再帰深度が深いと、スタックオーバーフローのリスクが高まります。
データ構造の基本
アルゴリズムを本当に使えるようにするには、データ構造の見方が必要です。ここでは総覧で出てきた道具を、置き方の観点から整理します。
配列(Array)
最も基本的なメモリ配置。連続領域にデータを置く。
特徴:
- 添字アクセス:O(1)
- 中間への挿入削除:O(n)
- キャッシュ局所性:優秀
# 静的配列
arr = [1, 2, 3, 4, 5]
print(arr[2]) # O(1)
# 動的配列(Python list)
arr.append(6) # O(1) ならし
arr.insert(2, 10) # O(n)
連結リスト(Linked List)
各要素が次の要素へのポインタを持つ構造。
class Node:
def __init__(self, data):
self.data = data
self.next = None
class LinkedList:
def __init__(self):
self.head = None
def insert_at_head(self, data): # O(1)
new_node = Node(data)
new_node.next = self.head
self.head = new_node
def search(self, data): # O(n)
current = self.head
while current:
if current.data == data:
return True
current = current.next
return False
特徴:
- 挿し込み(先頭):O(1)
- 削除(先頭):O(1)
- 添字アクセス:O(n)
- キャッシュ局所性:悪い(ポインタジャンプ)
教科書上の性質と現実: 連結リストは途中の挿入削除がわかりやすいという教育的価値がありますが、現代 CPU 上では配列に負けることが多いです。キャッシュミスが頻繁に起こるため、実メモリ効率では不利になります。
スタック(Stack)
LIFO(後入先出)データ構造。
class Stack:
def __init__(self):
self.items = []
def push(self, item): # O(1)
self.items.append(item)
def pop(self): # O(1)
return self.items.pop()
def is_empty(self): # O(1)
return len(self.items) == 0
使い道:
- 関数呼び出し(コールスタック)
- Undo/Redo 機能
- 括弧のバランスチェック
- 式評価(逆ポーランド記法)
- DFS 実装
キュー(Queue)
FIFO(先入先出)データ構造。
from collections import deque
class Queue:
def __init__(self):
self.items = deque()
def enqueue(self, item): # O(1)
self.items.append(item)
def dequeue(self): # O(1)
return self.items.popleft()
使い道:
- BFS 実装
- 待ち行列シミュレーション
- バッファ(生産者・消費者パターン)
- 印刷キュー
ハッシュテーブル
キーから値を高速に検索するデータ構造。
特徴:
- 平均検索:O(1)
- 最悪検索:O(n)(衝突が多い場合)
- 挿入・削除:O(1) 平均
# Python dict(ハッシュテーブル実装)
hash_table = {}
hash_table['key'] = 'value'
value = hash_table.get('key') # O(1) 平均
del hash_table['key'] # O(1) 平均
衝突解決戦略:
- チェーン法: 同じハッシュ値の要素をリストで繋ぐ
- オープンアドレッシング: 別の位置を探す(線形探査、二次探査、ダブルハッシング)
ハッシュテーブルは「番号札つきロッカー」という比喩がよく合います。ただしロッカー番号は完全ではないので、別の鍵が同じ箱に当たる衝突が起こります。だから本質は の魔法ではなく、うまく散らして平均的に短く済ませる設計 です。
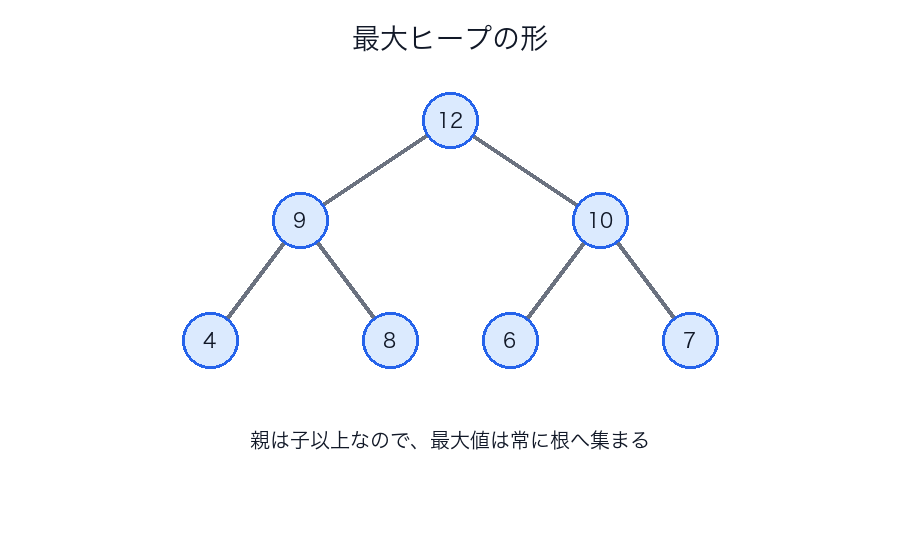
ヒープ(Heap)
親が子より小さい(または大きい)完全二分木。
import heapq
# 最小ヒープ
heap = []
heapq.heappush(heap, 5) # O(log n)
heapq.heappush(heap, 3)
heapq.heappush(heap, 7)
min_val = heapq.heappop(heap) # O(log n) → 3
# 最大ヒープ(値を反転)
max_heap = []
heapq.heappush(max_heap, -5)
max_val = -heapq.heappop(max_heap) # → 5
特徴:
- 最小/最大取り出し:O(1)
- 挿入・削除:O(log n)
- 整列済み配列ではない
ヒープは整列済み配列ではありません。親子関係だけが保証される、ほどよく整った山です。そのかわり、先頭の最小値や最大値をすばやく出し入れできます。
使い道:
- 優先度付きキュー
- Dijkstra アルゴリズム
- スケジューラ
- 複数の配列のマージ(n-way merge)
Trie(トライ)
接頭辞を効率よく管理する木構造。
class TrieNode:
def __init__(self):
self.children = {}
self.is_end = False
class Trie:
def __init__(self):
self.root = TrieNode()
def insert(self, word): # O(m) m=単語長
node = self.root
for char in word:
if char not in node.children:
node.children[char] = TrieNode()
node = node.children[char]
node.is_end = True
def search(self, word): # O(m)
node = self.root
for char in word:
if char not in node.children:
return False
node = node.children[char]
return node.is_end
def starts_with(self, prefix): # O(m) プレフィックス検索
node = self.root
for char in prefix:
if char not in node.children:
return False
node = node.children[char]
return True
特徴:
- 検索・挿入・削除:O(m)(m = 単語長)
- メモリ効率:同じ接頭辞をシェア
Trie の強みは「比較」より「文字列の共有」にあります。同じ接頭辞をまとめて持てるので、辞書やオートコンプリートのような問題に向いています。
使い道:
- 辞書検索
- オートコンプリート
- IP ルーティング
- スペルチェック
Union-Find(素集合データ構造)
グループの統合と「同じグループか」の判定を高速に行う。
class UnionFind:
def __init__(self, n):
self.parent = list(range(n))
self.rank = [0] * n
def find(self, x): # O(α(n)) α は逆アッカーマン関数
if self.parent[x] != x:
self.parent[x] = self.find(self.parent[x]) # 経路圧縮
return self.parent[x]
def union(self, x, y): # O(α(n))
px, py = self.find(x), self.find(y)
if px == py:
return False
# Union by rank
if self.rank[px] < self.rank[py]:
self.parent[px] = py
elif self.rank[px] > self.rank[py]:
self.parent[py] = px
else:
self.parent[py] = px
self.rank[px] += 1
return True
def is_same(self, x, y):
return self.find(x) == self.find(y)
特徴:
- find、union:O(α(n))(ほぼ定数時間)
- 実装がシンプル
Union-Find は、関係が変化していく集合のまとまりを見る道具です。グラフの見た目よりも、「どの頂点が今同じ連結成分にいるか」を速く知りたいときに効きます。
使い道:
- Kruskal アルゴリズム
- 接続性判定
- グループ分け
- 循環検出
セグメント木(Segment Tree)
配列に対する区間問い合わせを O(log n) で答える。
class SegmentTree:
def __init__(self, arr):
self.n = len(arr)
self.tree = [0] * (4 * self.n)
self.build(arr, 0, 0, self.n - 1)
def build(self, arr, node, start, end):
if start == end:
self.tree[node] = arr[start]
else:
mid = (start + end) // 2
self.build(arr, 2 * node + 1, start, mid)
self.build(arr, 2 * node + 2, mid + 1, end)
self.tree[node] = self.tree[2 * node + 1] + self.tree[2 * node + 2]
def query(self, node, start, end, l, r): # O(log n)
if r < start or end < l:
return 0
if l <= start and end <= r:
return self.tree[node]
mid = (start + end) // 2
return (self.query(2 * node + 1, start, mid, l, r) +
self.query(2 * node + 2, mid + 1, end, l, r))
def update(self, node, start, end, idx, val): # O(log n)
if start == end:
self.tree[node] = val
else:
mid = (start + end) // 2
if idx <= mid:
self.update(2 * node + 1, start, mid, idx, val)
else:
self.update(2 * node + 2, mid + 1, end, idx, val)
self.tree[node] = self.tree[2 * node + 1] + self.tree[2 * node + 2]
特徴:
- 区間和、区間最小値:O(log n) クエリ
- 点更新:O(log n)
使い道:
- 区間和の計算
- 区間最小/最大値
- 動的計画法の高速化
木とグラフの表現
木の種類と使い分け
二分探索木(BST)
順序つき探索に向いた木。
class TreeNode:
def __init__(self, val=0):
self.val = val
self.left = None
self.right = None
class BST:
def __init__(self):
self.root = None
def insert(self, val): # O(log n) 平均、O(n) 最悪
if self.root is None:
self.root = TreeNode(val)
else:
self._insert_helper(self.root, val)
def _insert_helper(self, node, val):
if val < node.val:
if node.left is None:
node.left = TreeNode(val)
else:
self._insert_helper(node.left, val)
else:
if node.right is None:
node.right = TreeNode(val)
else:
self._insert_helper(node.right, val)
def search(self, val): # O(log n) 平均、O(n) 最悪
return self._search_helper(self.root, val)
def _search_helper(self, node, val):
if node is None:
return False
if val == node.val:
return True
elif val < node.val:
return self._search_helper(node.left, val)
else:
return self._search_helper(node.right, val)
特徴:
- 単純な順序つき探索の発想を学ぶ入口
- 偏ると線形に悪化(最悪 O(n))
平衡木(AVL Tree、赤黒木)
木が片側へ伸びすぎないよう保つ。
# 赤黒木は実装が複雑なため、概念のみ記載
# 実務では言語標準ライブラリを使う
# Python 標準ライブラリに赤黒木相当はない
# 必要なら sortedcontainers などの外部実装を検討
# C++: std::map(赤黒木実装)
# Java: TreeMap(赤黒木実装)
特徴:
- 最悪でも O(log n) を保証
- 順序つき map や set の基盤
- 実装が複雑(回転、色付けなど)
B 木 / B+ 木
ディスク向け索引。1 回の読み込みで多くの分岐を進める。
特徴:
- メモリではなくディスクやページ I/O を意識した設計
- DB やファイルシステムと相性がよい
- 複数の子を持つ(m-way 分岐木)
セグメント木(区間問い合わせ)
既に詳細に説明しました。
グラフの表現方法
グラフの表現は、アルゴリズムの形にも影響します。
隣接行列(Adjacency Matrix)
V×V 行列でグラフを表現。
# 隣接行列表現
graph_matrix = [
[0, 1, 0, 1],
[1, 0, 1, 0],
[0, 1, 0, 1],
[1, 0, 1, 0]
]
# グラフが密な場合に向く
# メモリ:O(V²)
# 辺の存在確認:O(1)
メリット:
- 辺の存在確認が O(1)
- Floyd-Warshall のような行列演算が自然
デメリット:
- メモリが O(V²)
- 疎なグラフは無駄
隣接リスト(Adjacency List)
各頂点の隣接頂点をリストで持つ。
# 隣接リスト表現
graph_list = {
0: [1, 3],
1: [0, 2],
2: [1, 3],
3: [0, 2]
}
# または
graph_list = [
[1, 3],
[0, 2],
[1, 3],
[0, 2]
]
# グラフが疎な場合に向く
# メモリ:O(V + E)
# 辺の存在確認:O(degree)
メリット:
- メモリが O(V + E)
- 疎なグラフに効率的
- DFS/BFS と相性がよい
デメリット:
- 辺の存在確認に時間がかかる
エッジリスト(Edge List)
辺を (u, v, weight) で管理。
# エッジリスト表現
edges = [
(0, 1, 1),
(0, 3, 4),
(1, 2, 2),
(2, 3, 1)
]
# Kruskal などに向く
# メモリ:O(E)
メリット:
- Kruskal アルゴリズムに自然
- メモリが少ない
デメリット:
- 隣接情報の取得に時間がかかる
圧縮スパース行(Compressed Sparse Row / CSR)
大規模疎グラフに向く効率的な表現。
# CSR 表現の概念
# row_ptr: [0, 2, 4, 6, 8] 各行の開始インデックス
# col: [1, 3, 0, 2, 1, 3, 0, 2] 列番号
# data: [1, 1, 1, 1, 1, 1, 1, 1] 値
表現選択のガイド
代表的なアルゴリズム
ここからは、典型的なアルゴリズムをカテゴリごとに詳しく見ていきます。
探索・検索アルゴリズム
探索は「欲しいものを見つける」ための基本操作です。
線形探索
何をするか
先頭から順に見ていき、目的の値があるか確かめます。
何に使うか
- 小さな配列
- ソートされていないデータ
- 一度しか調べない簡単な処理
計算量
特徴
- 単純で壊れにくい
- 前提が要らない
- データ量が大きいと遅い
図で見る
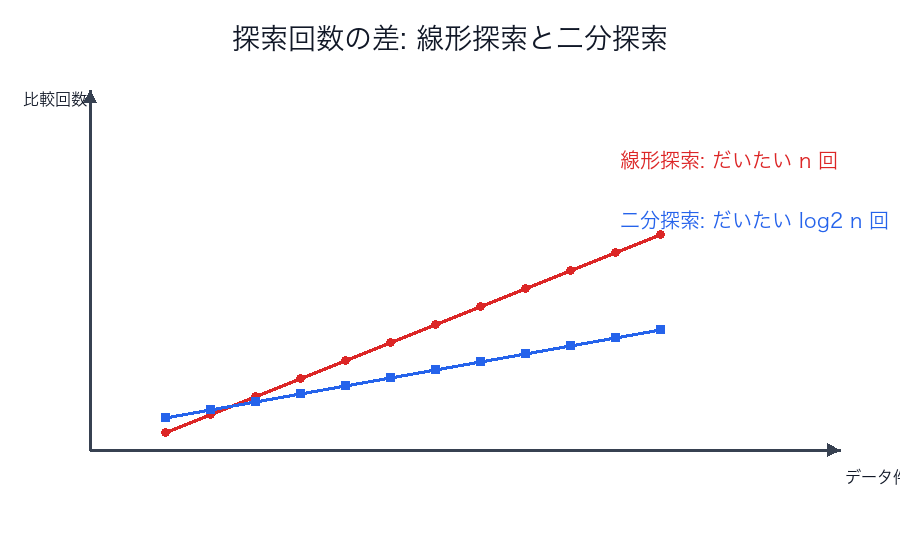
二分探索
何をするか
ソート済み配列 に対して、真ん中を見て左右どちらにあるかを判定し、範囲を半分に絞っていきます。
何に使うか
- 辞書順に並んだデータの検索
- 境界値の探索
- 「条件を満たす最小の値」を探す問題
計算量
たとえるなら
電話帳で名前を探すとき、最初から1行ずつ読むのではなく、真ん中を開いて範囲を絞る感じです。
図で見る
線形探索と二分探索の比較
| 観点 | 線形探索 | 二分探索 |
|---|---|---|
| 前提 | 不要 | ソート済みが必要 |
| 計算量 | ||
| 実装の簡単さ | とても簡単 | 少し注意が必要 |
| 向く場面 | 小規模、非整列 | 大規模、整列済み |
よくある注意
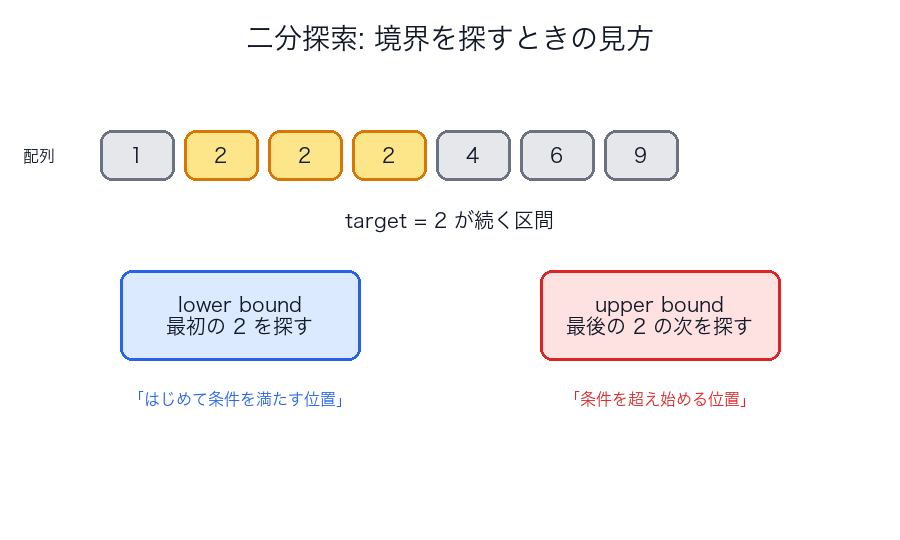
- 二分探索は ソート済み が前提
- 「見つかったか」だけでなく「最初の位置」「最後の位置」を探す変種が多い
- 不変条件を意識しないと off-by-one を起こしやすい
擬似コード
線形探索
for i = 0 .. n-1:
if a[i] == target:
return i
return -1
二分探索
lo = 0
hi = n - 1
while lo <= hi:
mid = (lo + hi) // 2
if a[mid] == target:
return mid
if a[mid] < target:
lo = mid + 1
else:
hi = mid - 1
return -1
典型問題
- 会員 ID 一覧から目的の ID を探す
- ソート済みログから最初のエラー位置を見つける
- 条件を満たす最小値や最大値を探す
つまずきやすい点
| つまずき | 何が起きているか |
|---|---|
| 二分探索なのに遅い | 毎回ソートしていて前提の利点を消している |
| 二分探索が壊れる | lo, hi, mid の更新条件が崩れている |
| 値は探せるが境界が取れない | lower bound / upper bound 問題になっている |
答えに対する二分探索
二分探索は配列検索だけの技法ではありません。
「ある値 x が実現可能か」を判定でき、その判定が単調なら、
- false false false true true true
のような境界を二分探索できます。
これは最小容量、最短日数、最大平均などの問題でよく出ます。
図だけで復習
| 図で思い出すこと | 意味 |
|---|---|
| 線形探索の横並び | 先頭から順に全部見る |
| 二分探索の左右分岐 | 真ん中を見て探索範囲を半分にする |
| 比較回数の差の図 | n と log n の差はすぐ大きくなる |
ソートアルゴリズム
ソートは、データを一定の順序へ並べる処理です。
代表的なソート
| アルゴリズム | 平均計算量 | 安定性 | 特徴 |
|---|---|---|---|
| バブルソート | 安定 | 教材向き、実用では弱い | |
| 挿入ソート | 安定 | 小規模やほぼ整列済みで強い | |
| マージソート | 安定 | 安定で予測しやすい | |
| クイックソート | 平均 | 不安定 | 実用で高速なことが多い |
| ヒープソート | 不安定 | 最悪でも安定した計算量 |
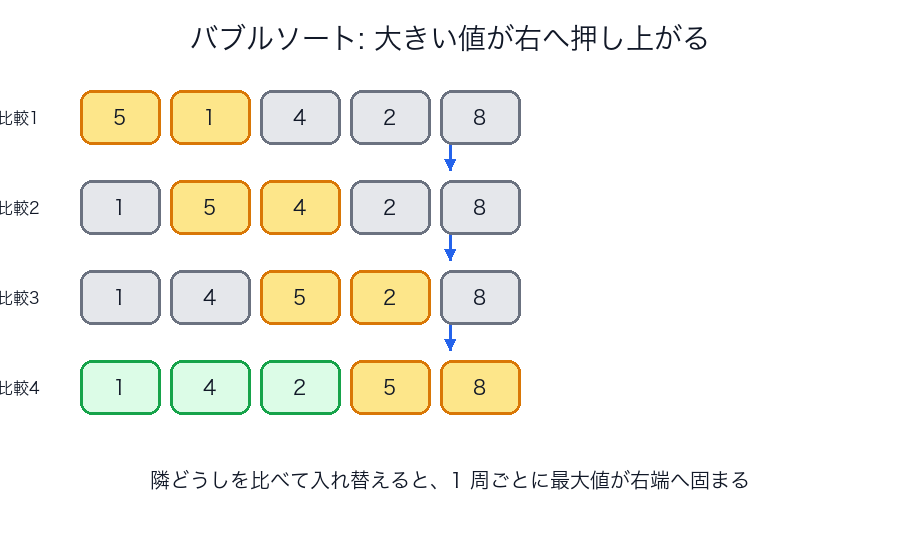
バブルソート
発想
隣り合う 2 つを比べて、順序が逆なら入れ替えます。
これを左から右へ 1 周すると、その時点の最大値が右端へ押し上がります。
どう見るとわかりやすいか
バブルソートの本質は、「全体を一気に並べる」より、
大きい値を少しずつ右へ運ぶ ところにあります。
図で見る
挿入ソート
発想
左側を「すでに整列済みの部分」と見なし、次の要素をその中の正しい位置へ差し込みます。
どう見るとわかりやすいか
挿入ソートは、カードを手札の中へ差し込む動きにかなり近いです。
比べながら右へずらして空きを作り、そこへ新しい値を入れます。
図で見る
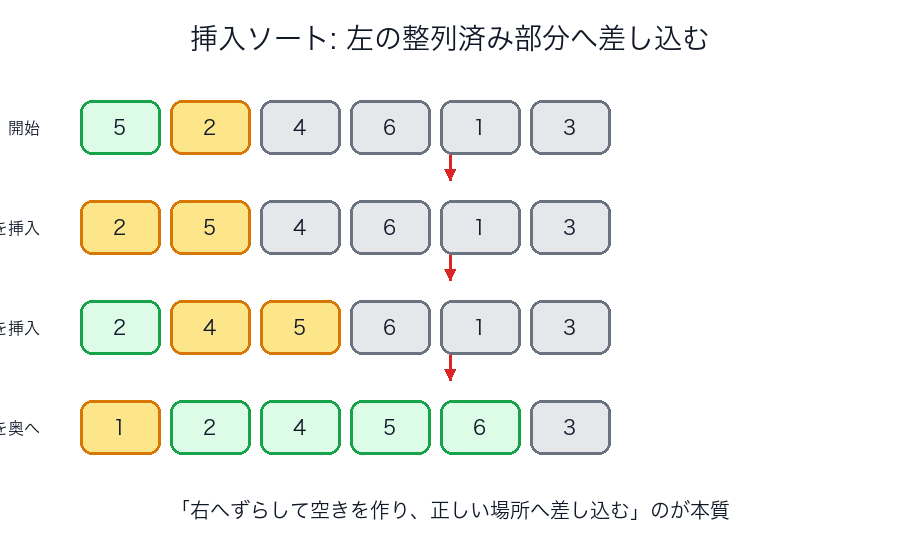
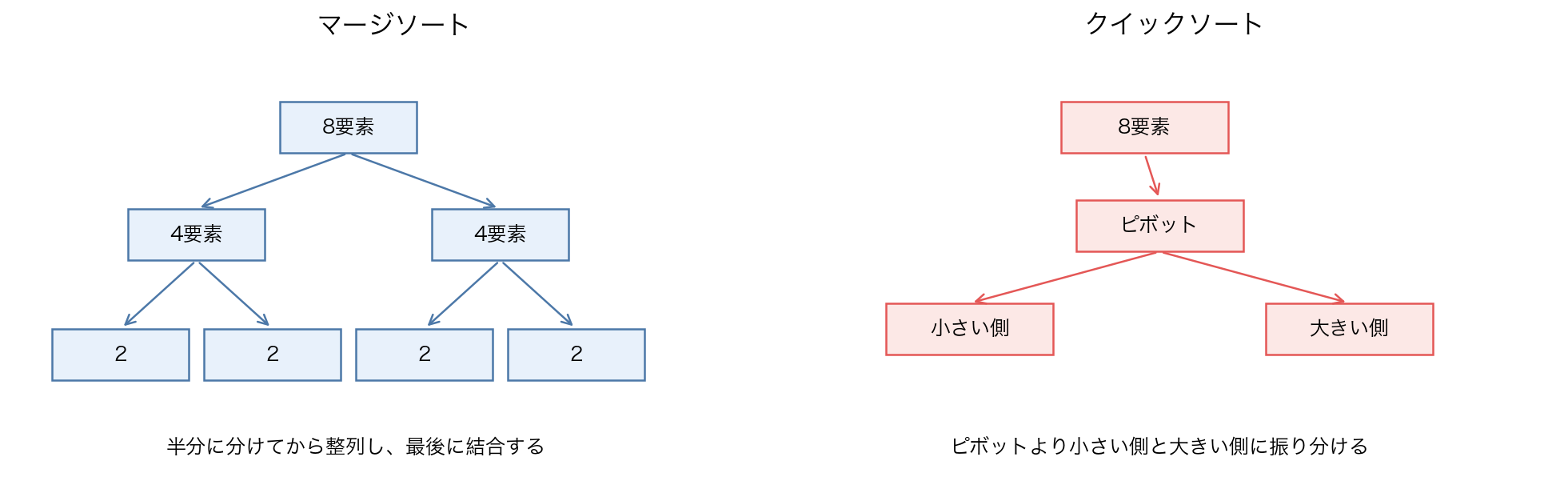
マージソート
発想
- 配列を半分に分ける
- それぞれを再帰的に整列する
- 最後に2つをマージする
分類
分割統治 の典型です。
強み
- 安定ソート
- 最悪でも
- 外部ソートとの相性がよい
なぜうまくいくか
マージソートの強さは、分けたあとに困らない ことです。
左右半分をそれぞれ整列してしまえば、最後は
- 左の先頭
- 右の先頭
を比べて小さい方を取るだけで全体を整列できます。
つまり難しさを
- 小さく分ける
- 最後の統合を単純にする
へ移しているのが本質です。
図で見る
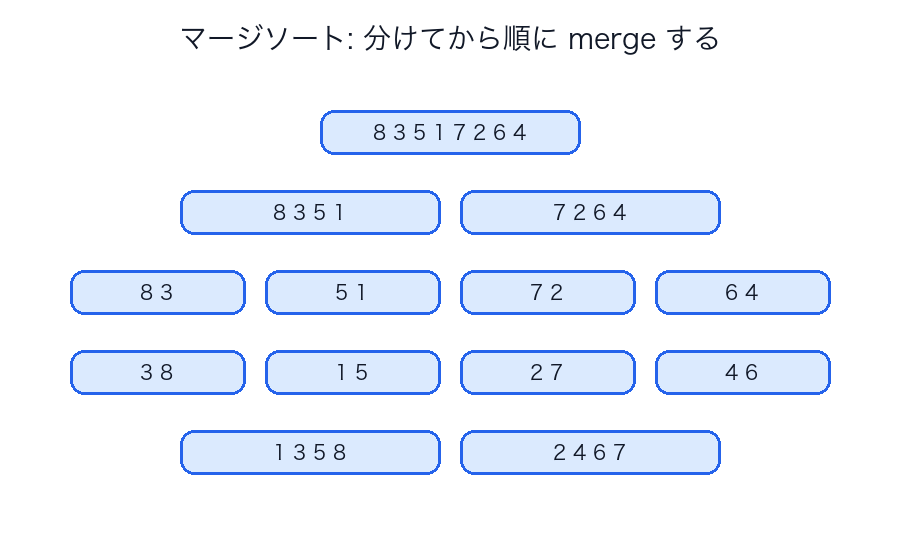
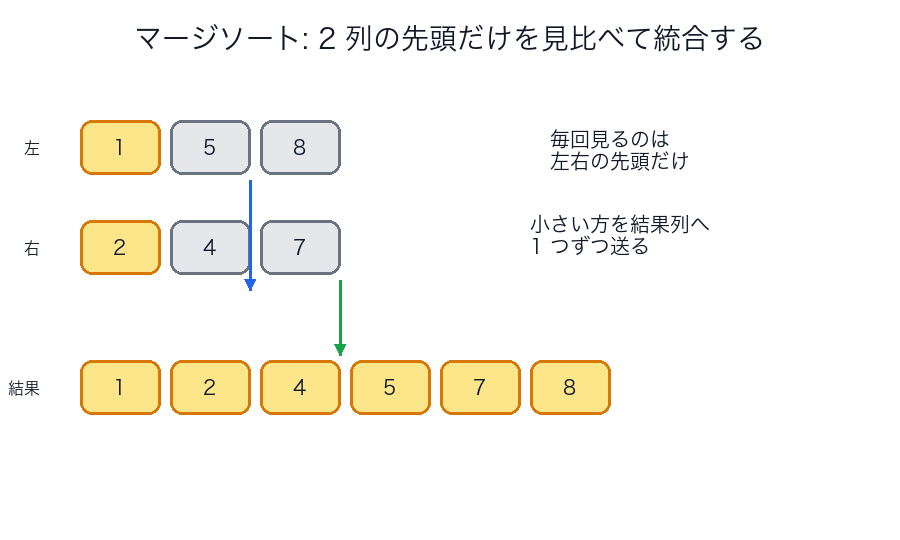
クイックソート
発想
- ある要素を pivot に選ぶ
- pivot より小さいもの / 大きいものへ分ける
- 左右を再帰的に整列する
強み
- 実装や最適化次第で非常に速い
- メモリ使用量を抑えやすい
注意
- pivot 選びが悪いと最悪
なぜ速いことが多いか
クイックソートは、マージソートより理論上きれいとは限りませんが、
- 配列をその場で分割しやすい
- キャッシュ局所性がよい
- 実装最適化が豊富
ため、実用ではかなり速くなることが多いです。
図で見る
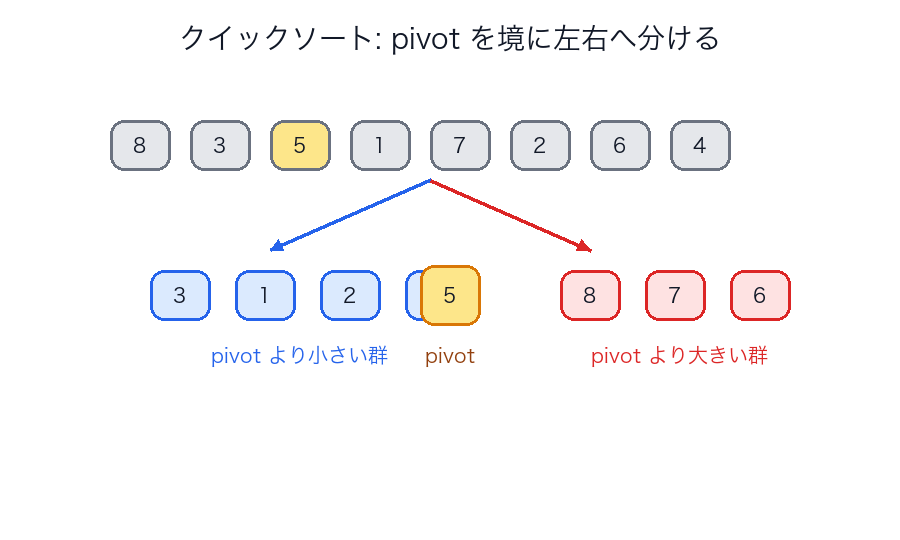
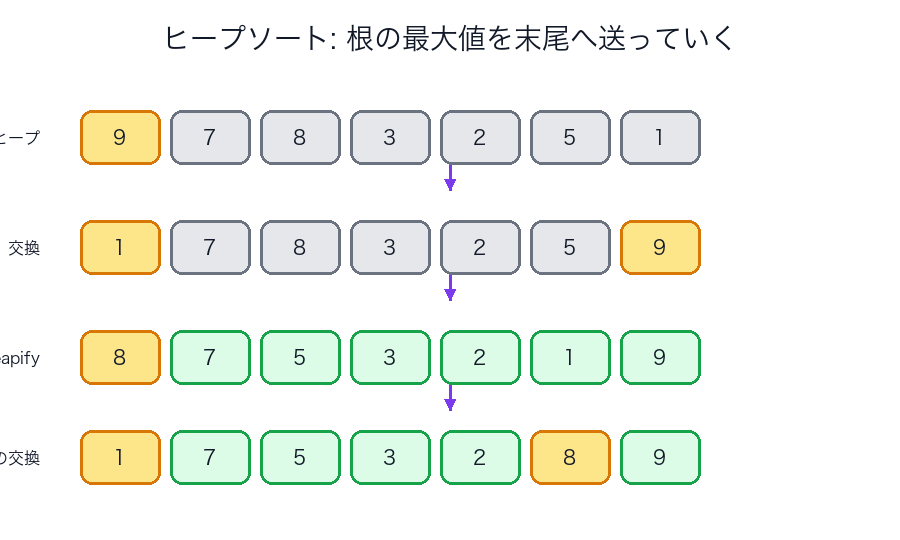
ヒープソート
発想
ヒープという「最小値または最大値をすぐ取り出せる木」を使います。
強み
- 最悪でも
- 追加メモリを抑えやすい
図で見る
既存図: ソート戦略の直感
安定性を図で見る
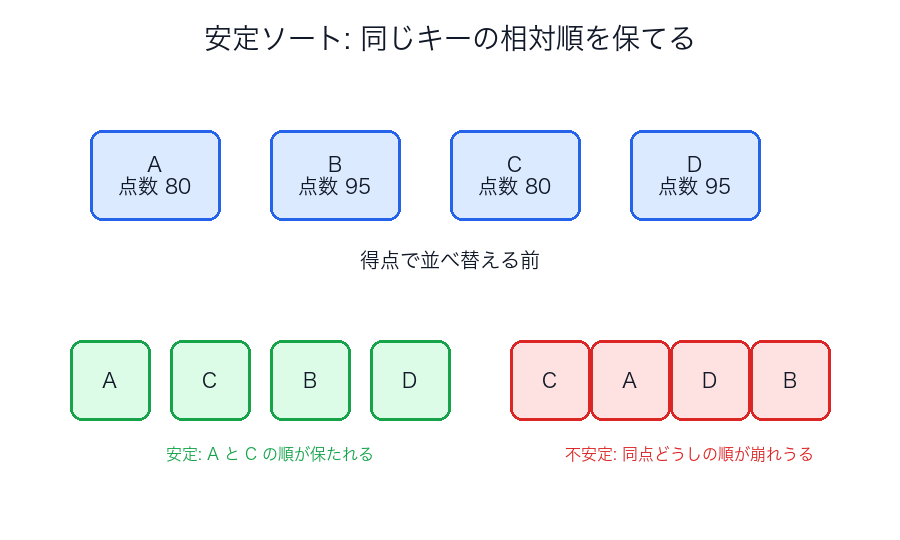
安定ソートで大事なのは、同じキーの要素どうしの順番を壊さないことです。
図のように、同点や同順位の要素に別の意味が乗っているとき、この性質がかなり効きます。
参考: 擬似コード
マージソート
merge_sort(a):
if len(a) <= 1:
return a
left = merge_sort(first half)
right = merge_sort(second half)
return merge(left, right)
クイックソート
quick_sort(a):
if len(a) <= 1:
return
pivot = choose_pivot(a)
partition into (< pivot), (= pivot), (> pivot)
quick_sort(left part)
quick_sort(right part)
典型問題
- 売上データを日付順に並べる
- 学生一覧を得点順に並べる
- ログをキー順に整理して検索しやすくする
安定ソートが大事な場面
安定ソートとは、同じキーを持つ要素の相対順序を保つソートです。
たとえば、
- まず名前順に並べる
- 次に得点順に並べる
とき、2回目のソートが安定なら、得点が同じ人の中では名前順が保たれます。
つまずきやすい点
| つまずき | 説明 |
|---|---|
| クイックソートは常に最速と思う | pivot 次第で最悪 が残る |
| バブルソートでも十分と思う | データが増えると急に厳しくなる |
| 安定性を無視する | 複数キー整列で思わぬ順序崩れが出る |
どのソートを選ぶか
| 場面 | 候補 | 理由 |
|---|---|---|
| 安定性が重要 | マージソート / Timsort 系 | 同キー順序を保ちやすい |
| 平均的に速ければよい | クイックソート系 | 実用で高速なことが多い |
| 最悪時計算量を重視 | ヒープソート | を守りやすい |
| データが小さい / ほぼ整列済み | 挿入ソート | 単純で局所的に強い |
図だけで復習
| 図で思い出すこと | 意味 |
|---|---|
| バブルソートの縦並び図 | 大きい値を右へ押し上げる |
| 挿入ソートの差し込み図 | 左側の整列済み部分へ入れる |
| マージソートの分割図 | 分けてから最後にきれいに merge する |
| マージの詳細図 | 左右の先頭だけを見比べればよい |
| クイックソートの partition 図 | pivot を境に左右へ分ける |
| ヒープの木 | 最大や最小をすぐ取り出したいときの形 |
| ヒープソートの抽出図 | 根の最大値を末尾へ送り続ける |
| 安定性の比較図 | 同じキーの順番を保つかどうか |
グラフアルゴリズム
グラフは、頂点と辺からなる構造です。
都市の地図、SNS、人間関係、依存関係、ネットワーク経路などに現れます。
BFS と DFS
BFS(幅優先探索)
- 始点から 近い順 に調べる
- キューを使うことが多い
- 辺の重みが一律なら最短手数に強い
なぜ最短手数になるか
層ごとに広がるので、ある頂点へ初めて到達した時点で、それより短い手数ではもう着けません。
DFS(深さ優先探索)
- 行けるところまで 深く 潜る
- 再帰またはスタックを使う
- 連結成分、サイクル検出、トポロジカルソートの基礎
なぜ構造把握に向くか
DFS は「潜る」「戻る」の時点がはっきりしているので、木辺・後退辺・行きがけ時刻・帰りがけ時刻のような構造情報を取り出しやすいです。
BFS / DFS の図
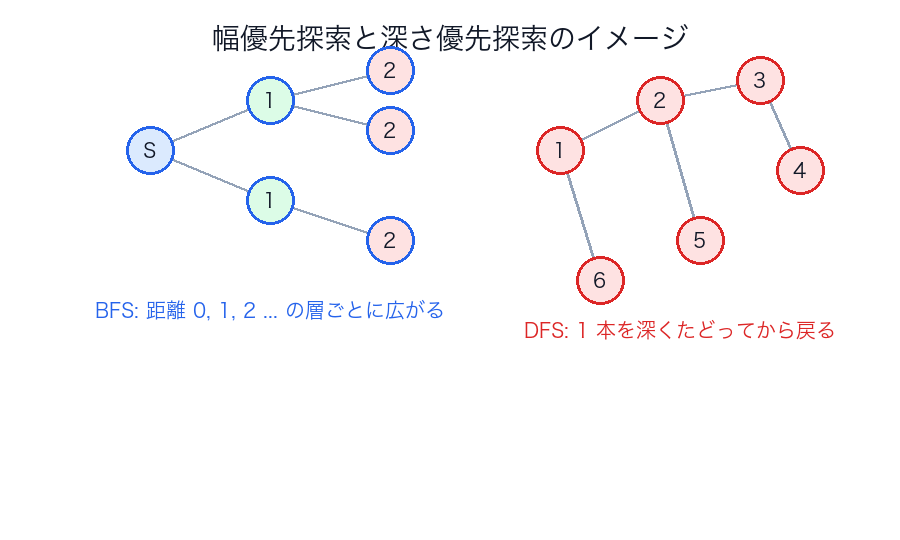
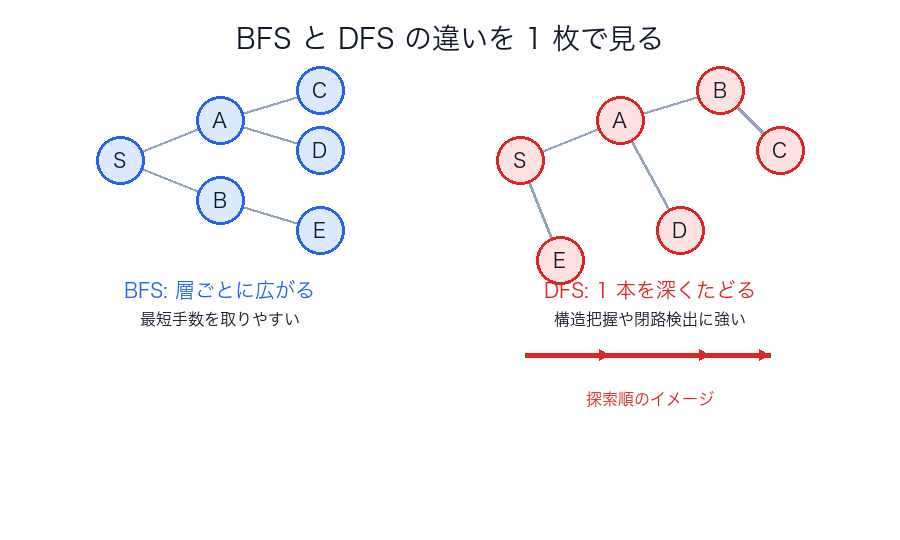
BFS / DFS の比較
| 観点 | BFS | DFS |
|---|---|---|
| 広がり方 | 層ごと | 一本を深く |
| 主な用途 | 最短手数、層構造 | 到達性、閉路、順序 |
| よく使う構造 | キュー | スタック / 再帰 |
| 計算量 |
擬似コード
BFS
queue = [start]
mark start visited
while queue is not empty:
v = pop_front(queue)
for each neighbor u of v:
if u is unvisited:
mark u visited
push_back(queue, u)
DFS
dfs(v):
mark v visited
for each neighbor u of v:
if u is unvisited:
dfs(u)
典型問題
- BFS: 迷路の最短手数、状態空間探索、層構造
- DFS: 閉路検出、到達性、トポロジカルソート、強連結成分の土台
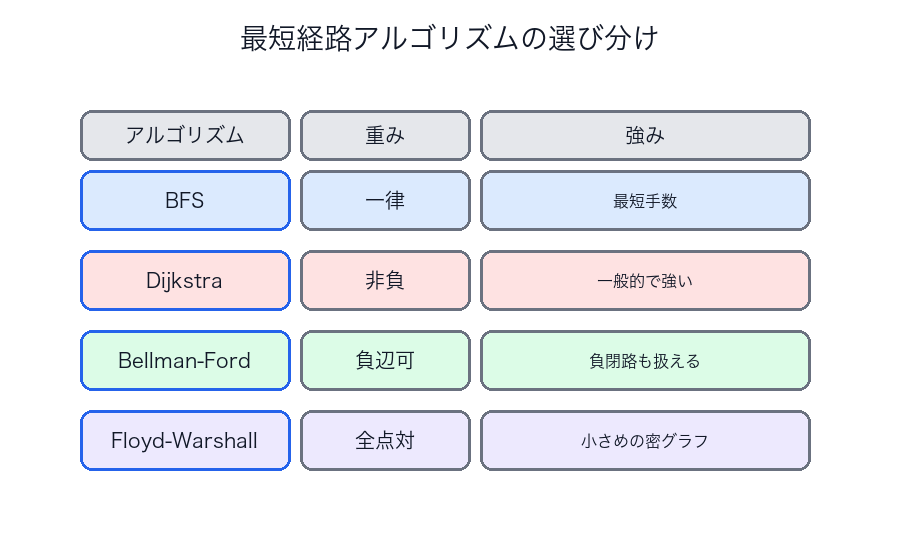
最短経路アルゴリズム
| アルゴリズム | 使える条件 | 代表計算量 | 向く場面 |
|---|---|---|---|
| BFS | 重みが一律 | 最短手数 | |
| Dijkstra | 負辺なし | 一般的な最短経路 | |
| Bellman-Ford | 負辺あり可 | 負辺検出、負閉路検出 | |
| Floyd-Warshall | 全点対 | 頂点数が比較的小さいとき | |
| A* | よいヒューリスティクスあり | 実装依存 | ゴールが明確な経路探索 |
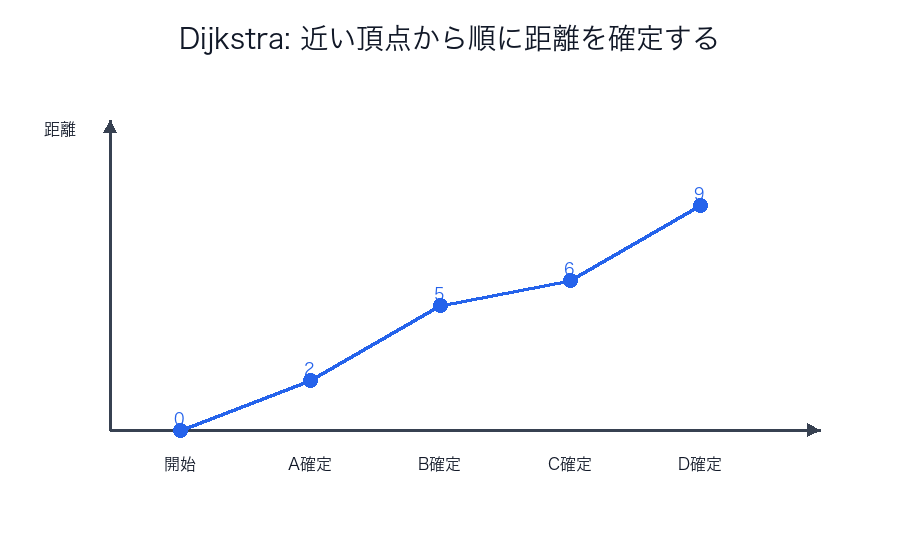
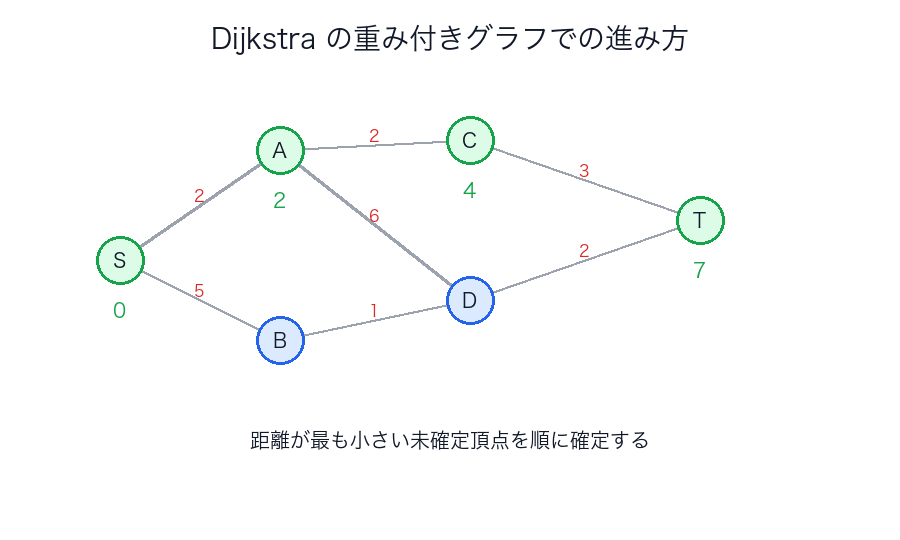
Dijkstra
いま最も距離が短いと分かっている頂点から順に確定していきます。
優先度付きキューと組み合わせるのが定番です。
典型問題
- 道路網の最短距離
- コスト最小の経路
- 重み付きグラフの単一始点最短経路
なぜ非負が必要か
いったん「最短だ」と確定した頂点が、後から負辺を通ってさらに短くなってしまうと、アルゴリズムの土台が崩れます。
非負重みなら、確定済みの距離は後から覆らない、という安心があるわけです。
Bellman-Ford
全辺に対して「もっと短くできるか」を繰り返します。
遅いですが、負の重みを扱えるのが大きな違いです。
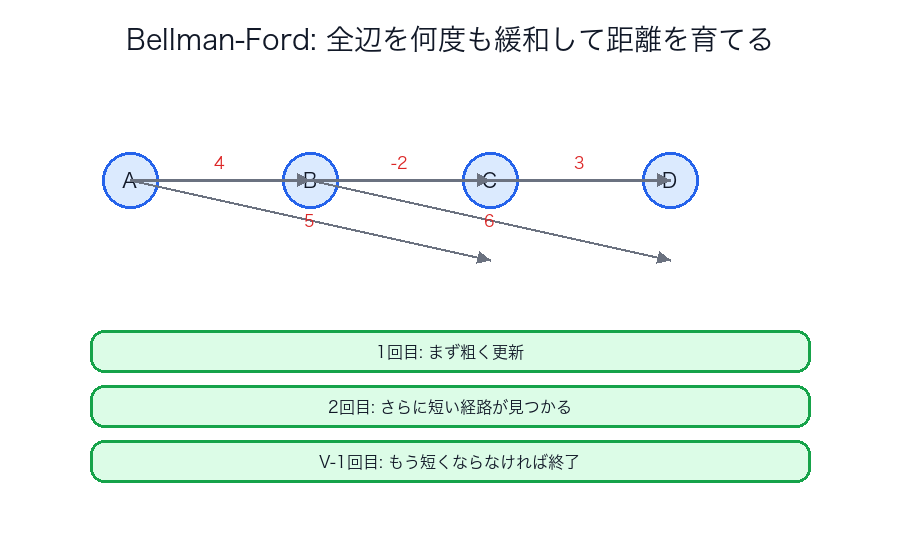
図の見方としては、1 回の走査で「完成」するのではなく、何周かするうちに距離がじわじわ改善されていくのがポイントです。
最初の周では遠回りの値しか入らなくても、別の辺を通るもっと短い経路が見つかると、次の周でその情報がまた先へ伝わります。
たとえるなら、水路の上流で水位が少し下がると、その影響が下流へ少しずつ伝わっていく感じです。
Bellman-Ford は「一気に確定する」より、全体に改善情報を何度も行き渡らせる アルゴリズムだと思うとつかみやすいです。
典型問題
- 負辺を含む最短経路
- 負閉路の検出
- 制約矛盾の発見
どこが Dijkstra と違うか
Bellman-Ford は「確定して先へ進む」のでなく、何度も全辺を緩和する ことで距離を育てます。
遅い代わりに、負辺や負閉路という難しい状況にも対応できます。
Floyd-Warshall
動的計画法で、
を全ての i, j, k について試すイメージです。
典型問題
- 全都市ペア間距離
- 小さめの密グラフの解析
- 到達性の閉包
どう考えると覚えやすいか
Floyd-Warshall は「中継点として 1 番まで使ってよい」「次に 2 番まで使ってよい」というふうに、
使ってよい中継点の集合を少しずつ増やす DP と捉えると本質が見えます。
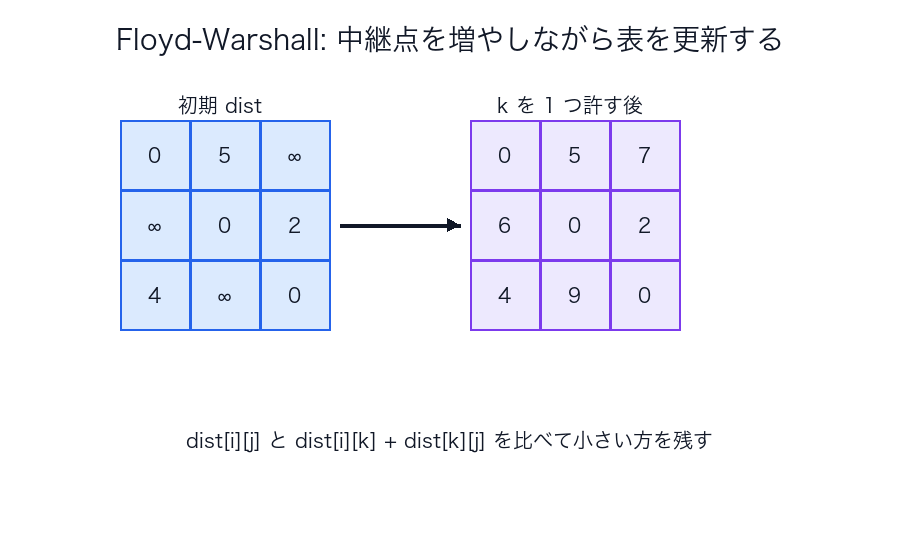
この表は、「いま許してよい中継点の種類」が増えるたびに、都市間距離の表が改善される様子を表しています。
いきなり複雑な全経路を考えるのではなく、
- まだ中継しない
- 1 番を中継してよい
- 1,2 番を中継してよい
のように、許可する経路の種類を少しずつ増やしていくのが本質です。
つまり Floyd-Warshall は、「表を 3 重ループで回す変な式」ではなく、
使ってよい寄り道を増やしながら、表全体を少しずつ良くしていく DP です。
A* の位置づけ
| 観点 | Dijkstra | A* |
|---|---|---|
| 何で優先順位を決めるか | 既知の距離 | |
| ゴール意識 | 薄い | 強い |
| 向く場面 | 全体の最短経路 | 目的地が明確な探索 |
| 注意 | 負辺不可 | ヒューリスティクス設計が重要 |
A* で大事なのは、ただ近い頂点を見るのでなく、ゴールへ近づきそうか という見積もりも混ぜることです。
図でいうと、Dijkstra が「円形に広がる」感覚なのに対し、A* は「目的地の方向へ細長く伸びる」感覚に近いです。
もちろん、その見積もり がひどいと寄り道が増えます。
逆に、ほどよく賢い見積もりなら、無関係な場所を広く探索せずに済みます。
最小全域木
Kruskal
- 辺を軽い順に見る
- 閉路を作らないなら採用する
- Union-Find と相性がよい
Prim
- ある木を少しずつ広げる
- 今の木から外へ出る最小コスト辺を選ぶ
比較
| アルゴリズム | 発想 | 相性のよい道具 |
|---|---|---|
| Kruskal | 辺を選ぶ | ソート、Union-Find |
| Prim | 木を育てる | 優先度付きキュー |
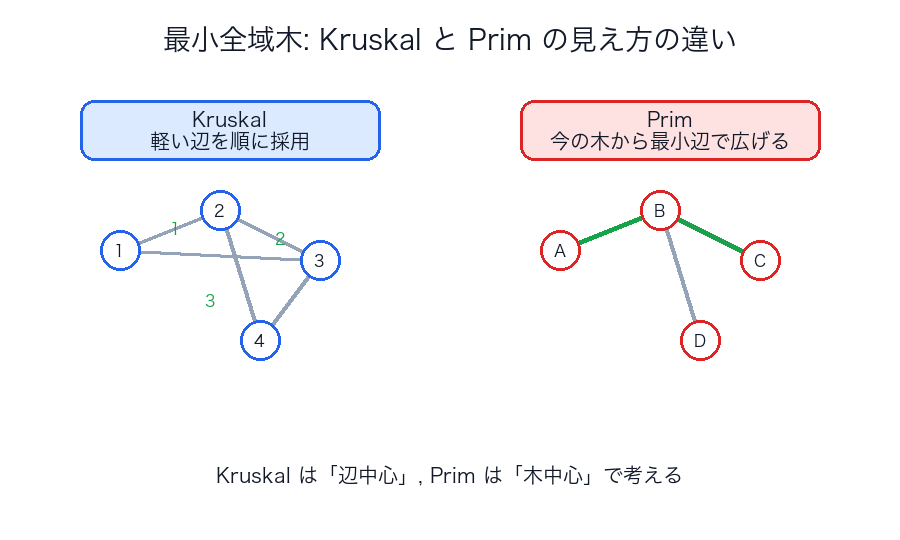
この 2 つは答えが同じでも、頭の使い方がかなり違います。
- Kruskal は「世界中の辺を軽い順に見て、使えるものを拾う」
- Prim は「いま持っている木から、次の 1 本を伸ばす」
という差があります。
だから Kruskal は ソートと Union-Find が気持ちよくはまり、
Prim は 優先度付きキュー と相性がいいわけです。
強連結成分
Tarjan / Kosaraju
有向グラフで「どこからどこへも行って戻ってこられるまとまり」を見つけます。
- Tarjan: DFS 1 回の流れで見つける
- Kosaraju: 逆向きグラフも使って整理する
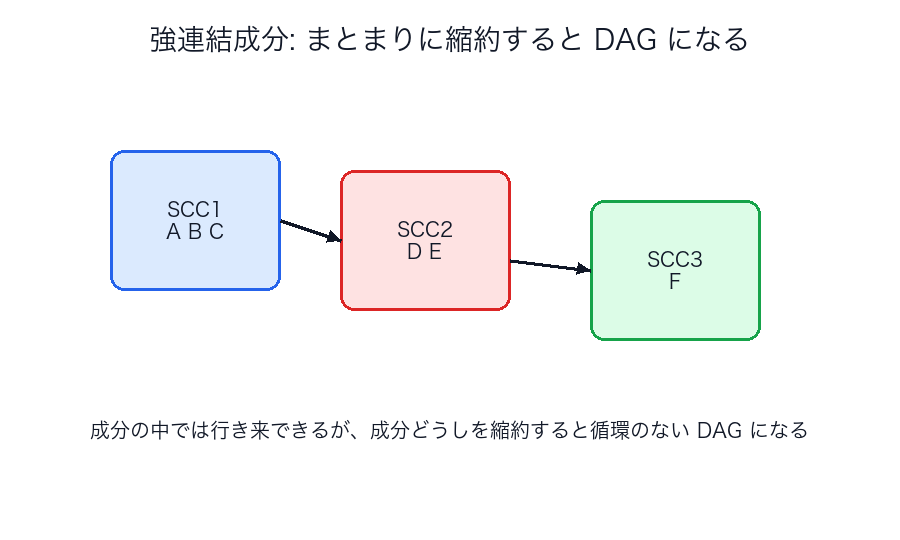
ここで大事なのは、「複雑な有向グラフも、行き来できる塊ごとに見ると整理しやすい」ということです。
塊の内部では自由に回れますが、塊どうしの関係だけを見ると循環が消えて、依存関係のような読みやすい形になります。
つまり強連結成分は、グラフを細かく調べる道具であると同時に、
複雑な循環構造を、扱いやすい部品へ圧縮する道具 でもあります。
つまずきやすい点
| つまずき | 説明 |
|---|---|
| BFS で重み付き最短経路を解こうとする | 重みが一律でないなら Dijkstra などが必要 |
| Dijkstra で負辺を見落とす | 前提が壊れて正しさが失われる |
| DFS は再帰だから遅いと思う | 本質は探索順序で、計算量は |
| Floyd-Warshall を大規模グラフで使う | は頂点数に敏感 |
グラフ問題でよくある派生
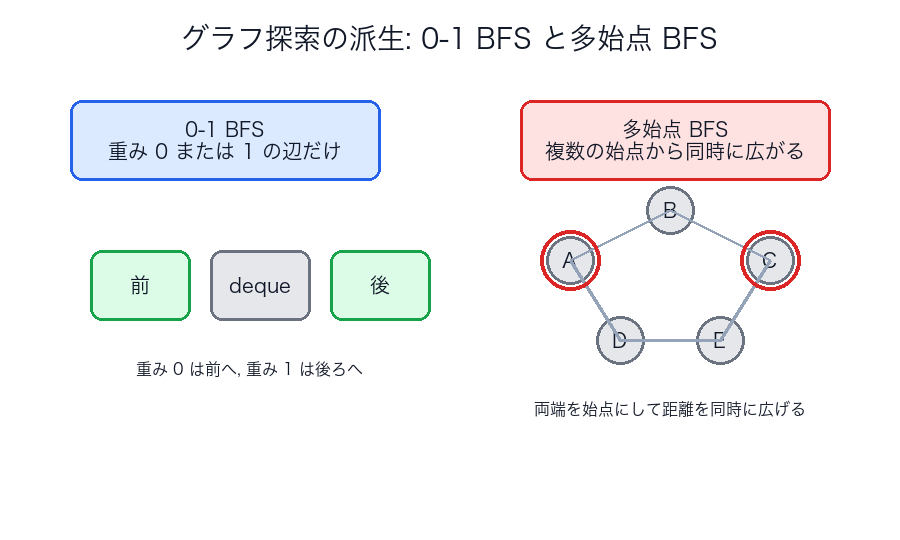
- 0-1 BFS: 辺重みが 0 または 1 なら deque で高速に解ける
- DAG 最短経路: トポロジカル順を使って高速化できる
- 多始点 BFS: 複数の始点から同時に層を広げる
- 状態付き BFS / Dijkstra: 頂点だけでなく状態も持たせる
グラフアルゴリズム選択フロー
図だけで復習
| 図で思い出すこと | 意味 |
|---|---|
| BFS / DFS の並び | 層で広がるか、深く潜るか |
| Dijkstra の距離確定図 | 最も近い未確定頂点を順に固める |
| Bellman-Ford の反復図 | 全辺を何度も緩和して改善を伝播させる |
| Floyd-Warshall の表 | 中継点を増やしながら全体の表を更新する |
| Kruskal / Prim 比較図 | 辺中心か、木中心かの違い |
| SCC の縮約図 | 循環を塊にして DAG に整理する |
設計パラダイム別のアルゴリズム
ここは個別アルゴリズムより、「どう問題を分解するか」の考え方です。
分割統治
発想
問題を小さく分けて、各部分を解き、最後に統合します。
代表例
- マージソート
- クイックソート
- FFT
図

動的計画法
発想
重なって現れる部分問題を再利用します。
典型例
- フィボナッチ
- ナップサック問題
- 最長共通部分列(LCS)
- 編集距離
数式の典型
たとえばフィボナッチは、
ですが、素朴再帰だと同じ値を何度も計算します。
DP はそこを表やメモで再利用します。
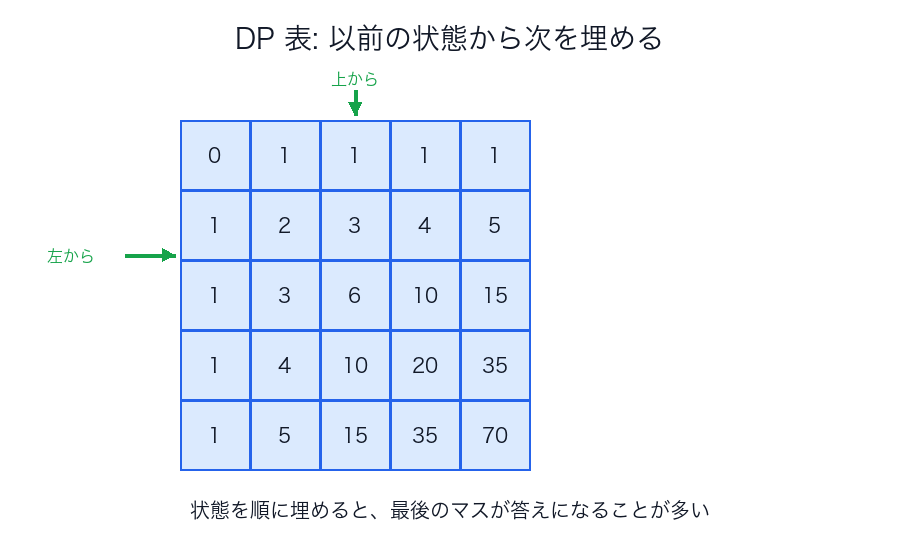
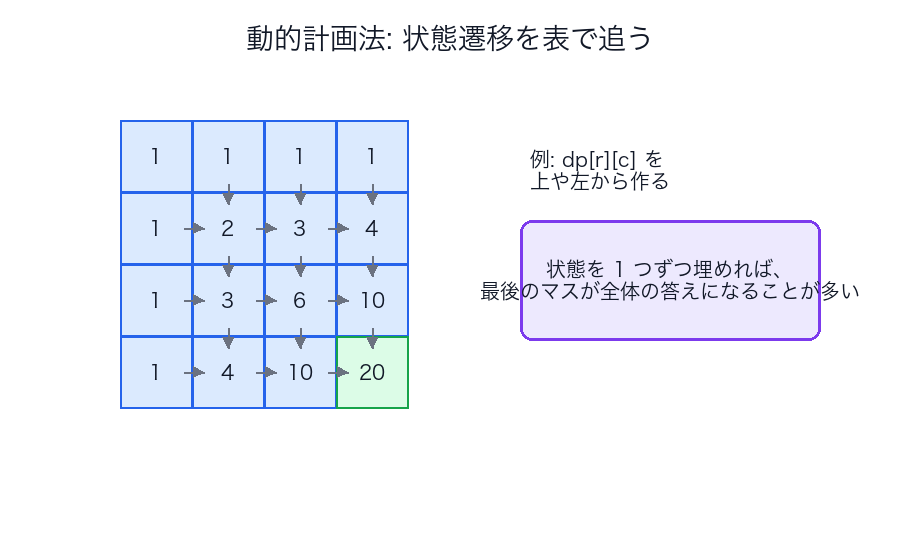
典型的な手順
- 状態を決める
- 遷移式を決める
- 初期条件を決める
- 依存順に表を埋める
典型問題
- ナップサック
- LCS
- 編集距離
- 区間 DP
- グリッド経路
どう設計するか
DP を学び始めたときに難しいのは、計算そのものではなく 状態設計 です。
良い状態とは、
- 必要な情報だけ持つ
- 次の状態を計算できる
- 重複部分問題が再利用できる
ものです。
たとえば LCS なら、
dp[i][j]
を「文字列 A の先頭 i 文字と、文字列 B の先頭 j 文字の LCS 長」と置くのが自然です。
ここでは「いまどこまで見たか」が状態になっています。
図で見る
| 状態 | そこに何を入れるか | どこから遷移するか |
|---|---|---|
dp[i][j] |
その位置まで見たときの最良値 | 上、左、左上など |
| 初期行 / 初期列 | 境界条件 | 直接決まる |
| 最終セル | 問題全体の答え | 全遷移の集約 |
貪欲法
発想
各ステップで局所的に最善と思える選択をします。
代表例
- Dijkstra
- Kruskal
- Huffman 符号
注意
貪欲法はいつでも正しいわけではありません。
「局所最適が全体最適につながる」構造が必要です。
典型問題
- 活動選択問題
- Huffman 符号
- 最小全域木
- 一部のスケジューリング問題
図で見る
ざっくり選び分け
| 観点 | 向きやすい手法 |
|---|---|
| 半分に割ってまた同じ形 | 分割統治 |
| 同じ部分問題が何度も出る | 動的計画法 |
| 毎回の最善選択で正しそう | 貪欲法 |
擬似コードで見る差
動的計画法の型
for state in dependency order:
dp[state] = best value from previous states
貪欲法の型
while choices remain:
take locally best choice
つまずきやすい点
| つまずき | 説明 |
|---|---|
| DP は表を作ればよいと思う | 状態設計が本体 |
| 貪欲法は速いから正しいと思う | 正しさ証明が別に必要 |
| 分割統治と DP を混同する | 重複部分問題の有無が大きな違い |
典型的な設計ミス
| ミス | 何が足りないか |
|---|---|
| DP の状態が大きすぎる | 不要な情報まで持っている |
| 貪欲法で局所最適を選んで失敗 | 交換法則や matroid 的構造の確認不足 |
| 分割統治なのに統合が高すぎる | 分割後の最後の処理が重すぎる |
図だけで復習
| 図で思い出すこと | 意味 |
|---|---|
| 分割統治の再帰木 | 問題を小さくして最後に統合する |
| DP の表 | 過去の状態を再利用して埋める |
| 貪欲法のフロー | いま最善に見える選択を前へ進める |
文字列アルゴリズム
文字列処理は検索、補完、辞書、ログ解析、バイオインフォマティクスなどで重要です。
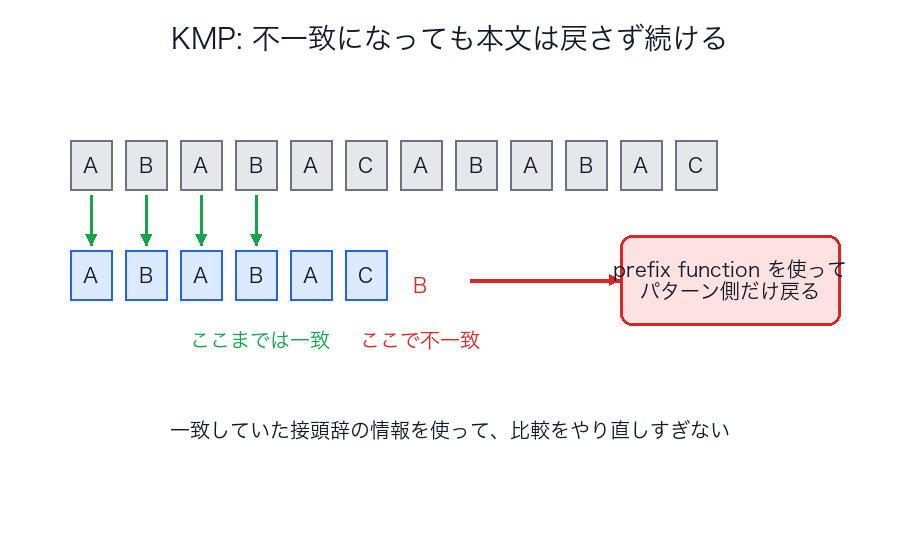
KMP
何をするか
パターンマッチで、失敗したときに「どこまで一致していたか」を再利用して、無駄な戻りを減らします。
強み
- 単純検索より速く安定
- 最悪でも線形時間
計算量
ここで n は本文長、m はパターン長です。
なぜ速いか
単純検索では、不一致が起きるたびに本文側やパターン側を大きく戻すことがあります。
KMP は prefix function により、
- すでに一致していた情報
を捨てずに次へ進めるため、全体で線形時間に収まります。
図で見る
Trie
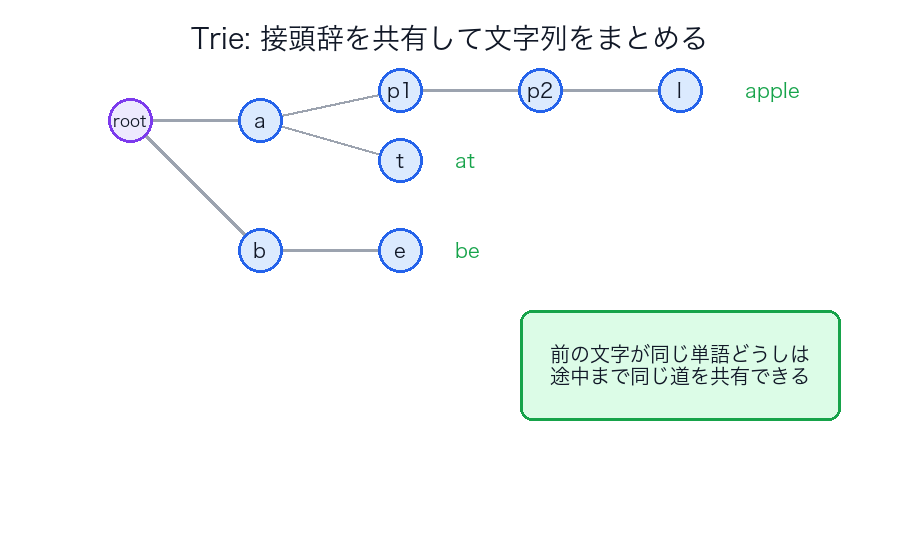
何をするか
文字列を1文字ずつ分岐する木に入れます。
何に使うか
- 前方一致検索
- オートコンプリート
- 辞書圧縮
たとえるなら
文字列全体を1個の鍵として持つのではなく、道順そのものを木にした感じです。
図で見る
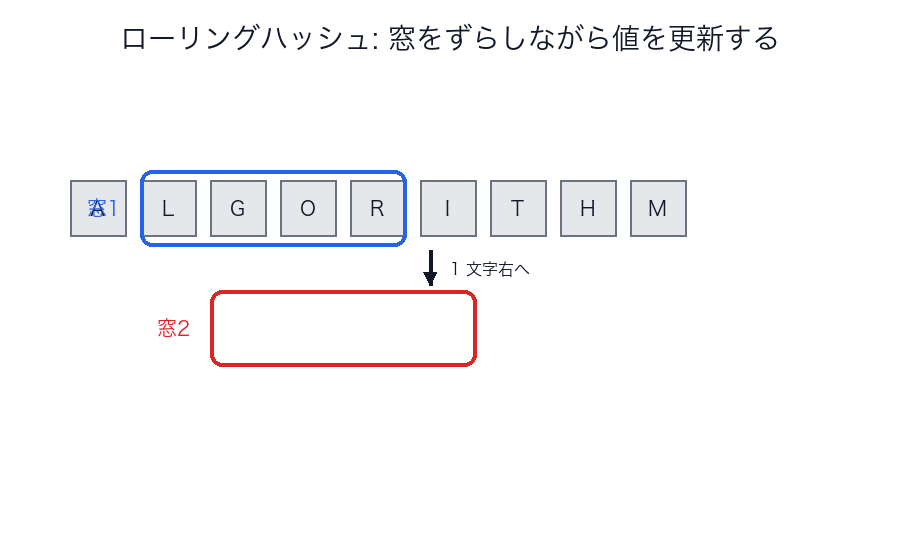
ローリングハッシュ
何をするか
文字列の区間ごとのハッシュを高速に更新しながら比較します。
何に使うか
- 文字列検索
- 重複部分列の発見
- 文字列集合の近似比較
図で見る
擬似コード
KMP のイメージ
build prefix table pi for pattern
i = 0, j = 0
while i < text length:
while j > 0 and text[i] != pattern[j]:
j = pi[j-1]
if text[i] == pattern[j]:
j += 1
if j == pattern length:
report match
j = pi[j-1]
i += 1
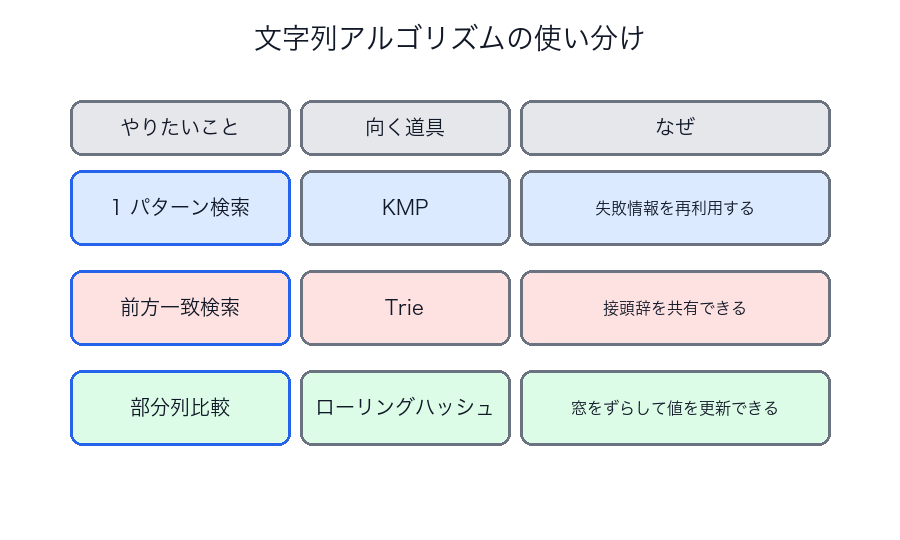
文字列アルゴリズムの使い分け
| やりたいこと | 候補 |
|---|---|
| 一つのパターンを高速検索 | KMP |
| 前方一致を大量に扱う | Trie |
| 部分列比較を高速化 | ローリングハッシュ |
つまずきやすい点
| つまずき | 説明 |
|---|---|
| KMP は魔法の表だと思う | 失敗時にどこまで再利用するかを表している |
| Trie は常に省メモリと思う | 分岐が多いとメモリ消費は大きい |
| ハッシュ一致なら文字列一致と思う | 衝突可能性がある |
文字列アルゴリズムでよく出る発想
- 失敗情報を再利用する: KMP
- 接頭辞を共有して持つ: Trie
- 値を要約して比較を速くする: ローリングハッシュ
つまり文字列アルゴリズムは、
- 文字そのものを比べる
- 構造を木にする
- ハッシュで要約する
という3つの見方を持っているとも言えます。
図だけで復習
| 図で思い出すこと | 意味 |
|---|---|
| KMP の戻り先図 | 本文は戻さず、パターン側の知識を再利用する |
| Trie の木 | 接頭辞を共有して前方一致に強くする |
| ローリングハッシュの窓 | 1 文字ずつずらしながら比較を速くする |
データ構造と強く結びつくアルゴリズム
アルゴリズムはしばしば、特定のデータ構造とセットで本領を発揮します。
ヒープ
最小値や最大値をすぐ取り出したいときに使います。
何に使うか
- 優先度付きキュー
- Dijkstra
- A*
- タスクスケジューラ
なぜ役立つか
ヒープは「全体を完全に整列したい」のではなく、次に一番小さいもの(または大きいもの)だけを素早く取りたい ときに効きます。
この違いが、優先度付きキューや Dijkstra と相性が良い理由です。
図で見る
Union-Find
集合が「つながっているか」を効率よく扱います。
何に使うか
- Kruskal
- 連結判定
- ネットワーク接続性
代表操作
- : 代表元を調べる
- : 2つの集合を併合する
擬似コード
make_set(x):
parent[x] = x
find(x):
if parent[x] == x:
return x
parent[x] = find(parent[x])
return parent[x]
union(x, y):
rx = find(x)
ry = find(y)
if rx != ry:
attach smaller tree under larger tree
図で見る
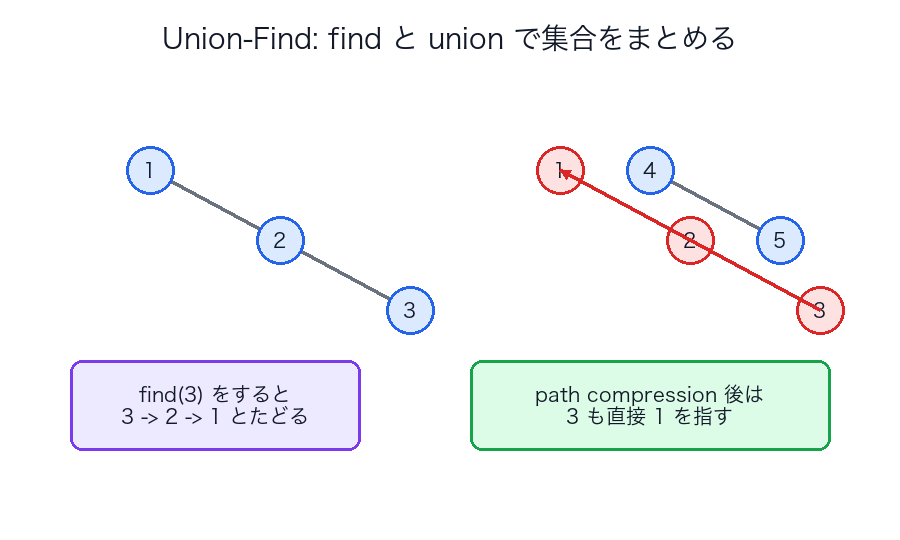
ハッシュテーブル
キーから値を平均 で引けることが多い構造です。
何に使うか
- キャッシュ
- 辞書
- 出現回数カウント
- メモ化
注意
平均 には、
- ハッシュ関数がよく散る
- 負荷率が高すぎない
といった前提があります。
実務での感覚
ハッシュテーブルは「かなり速い辞書」として使えますが、
- 順序を保たない
- 範囲検索に弱い
- 最悪ケースは理論上重くなりうる
といった性質も持ちます。
そのため、順序や範囲が重要なら平衡木のような別構造が向いていることもあります。
図で見る
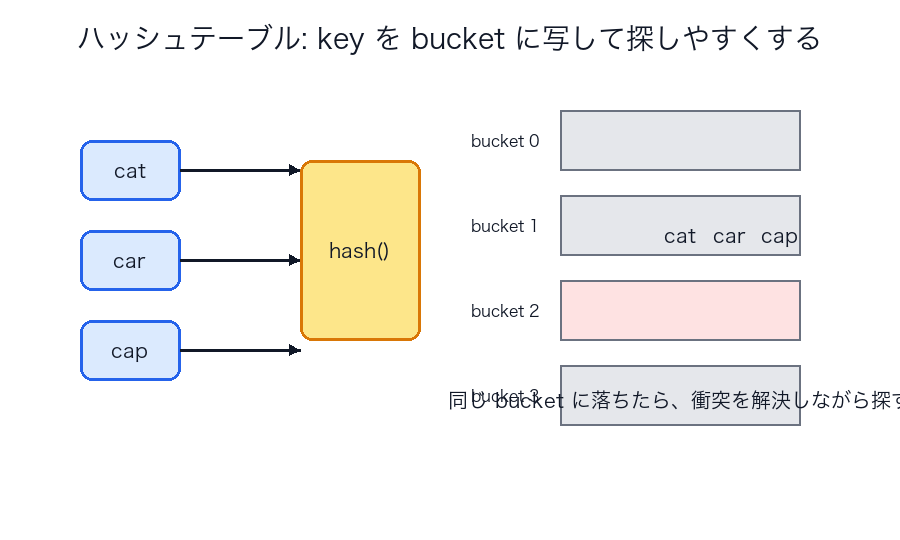
どの構造がどのアルゴリズムを支えるか
| データ構造 | よく結びつくアルゴリズム |
|---|---|
| キュー | BFS |
| スタック / 再帰 | DFS |
| ヒープ | Dijkstra, A*, ヒープソート |
| Union-Find | Kruskal, 連結判定 |
| ハッシュテーブル | メモ化, 出現回数, 探索高速化 |
つまずきやすい点
| つまずき | 説明 |
|---|---|
| アルゴリズムとデータ構造を別物として覚える | 実際にはセットで効くことが多い |
| Union-Find はただの木と思う | path compression と union by size が本体 |
| ハッシュテーブルは常に と思う | 平均であって前提がある |
図だけで復習
| 図で思い出すこと | 意味 |
|---|---|
| ヒープの木 | 一番小さい / 大きい要素を先に取りたい |
| Union-Find の圧縮図 | find のたびに木を平らにして速くする |
| ハッシュの bucket 図 | key を直接探すのでなく、まず箱へ写す |
どのアルゴリズムを選ぶか
代表的な選び分け表
| やりたいこと | 候補 | 判断の軸 |
|---|---|---|
| 値を探したい | 線形探索 / 二分探索 | ソート済みか |
| 並べ替えたい | マージ / クイック / ヒープ | 安定性、最悪時計算量、メモリ |
| 最短経路を求めたい | BFS / Dijkstra / Bellman-Ford / A* | 重み、負辺、ゴールの有無 |
| 全体を安くつなぎたい | Kruskal / Prim | 辺中心か木中心か |
| 部分問題を再利用したい | DP | 重複部分問題があるか |
| 文字列の前方一致 | Trie | プレフィックス検索が重要か |
よくある見分け方
- ソート済み なら二分探索を疑う
- 最短手数 なら BFS を疑う
- 重み付き最短経路 なら Dijkstra を疑う
- 負辺あり なら Bellman-Ford を疑う
- 毎回最小のものを取りたい ならヒープを疑う
- 状態が再利用できる なら DP を疑う
問題文から拾うキーワード
| 問題文の言い方 | 疑うアルゴリズム |
|---|---|
| 最短手数 | BFS |
| 最短距離、ただし重み付き | Dijkstra |
| 負のコスト | Bellman-Ford |
| 全組の距離 | Floyd-Warshall |
| 全体を安くつなぐ | Kruskal / Prim |
| 最初に条件を満たす位置 | 二分探索 |
| 部分問題が何度も出る | DP |
| 毎回その場で最善 | 貪欲法 |
アルゴリズム選択の小さな指針
- まず 入力構造 を見る
- 配列か、木か、グラフか、文字列か
- 次に 求めるもの を見る
- 検索か、整列か、最短経路か、数え上げか
- 最後に 制約 を見る
- ソート済みか、負辺があるか、頂点数が小さいか
選択を間違えやすい典型場面
| 場面 | ありがちな誤選択 | 本当の候補 |
|---|---|---|
| 重み付き最短経路 | BFS | Dijkstra / Bellman-Ford |
| 同じ部分問題が何度も出る | 単純再帰 | DP |
| 順序付きデータの高速検索 | ハッシュだけで考える | 平衡木 / 二分探索 |
| 1件ずつ最小値を取りたい | 毎回ソート | ヒープ |
図だけで復習
| 図で思い出すこと | 意味 |
|---|---|
| 選び分け表 | 入力構造と欲しい答えから候補を絞る |
| 最短経路比較図 | 重みと負辺の有無で候補が変わる |
| 文字列選択表 | 比べ方そのものを変える道具がある |
乱択・近似・ヒューリスティクス
ここまでは、比較的「正確に最適解を出す」アルゴリズムを中心に見てきました。
しかし現実には、
- 入力が巨大すぎる
- 問題が難しすぎる
- だいたい良ければ十分
という場面も多いです。そこで出てくるのが、乱択・近似・ヒューリスティクスです。
なぜこの方向が必要になるのかという理論的背景は、計算可能性と計算量 の NP 完全、NP 困難、近似・乱択・実用上の解き方 とつながります。
乱択アルゴリズム
乱数を使って平均性能や実装の簡潔さを得ます。
代表例
- ランダム pivot のクイックソート
- Miller-Rabin 素数判定
- ランダム化 Union-Find の一部変種
強み
- 最悪ケースを避けやすい
- 実装が簡潔になることがある
注意
- 毎回同じ動きをするとは限らない
- 再現性のために seed 管理が必要になることもある
図で見る
| 乱択の使い方 | ねらい |
|---|---|
| pivot をランダムに選ぶ | 偏った入力での最悪を避けやすくする |
| 試し打ちを複数回する | 高確率で正しい判定を得る |
| ランダム初期解を作る | 局所解へのはまり方を変える |
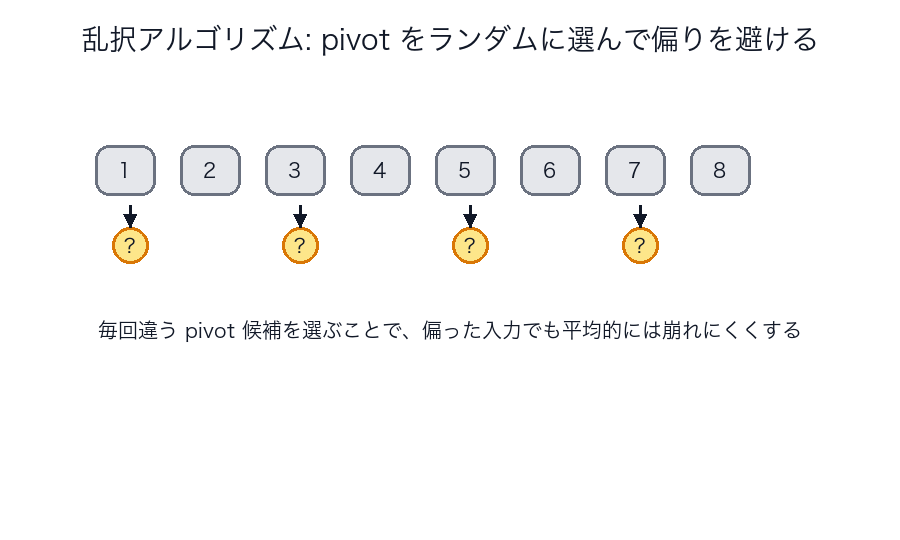
乱択アルゴリズムの気持ちよさは、「毎回完璧に賢い選択をする」のではなく、
偏った最悪ケースを引きにくくする ところにあります。
たとえばクイックソートでは、いつも端の値を pivot にすると壊れやすい入力があります。
そこで pivot をランダムにすると、特定の悪い入力だけがずっと不利になる状況をかなり避けやすくなります。
近似アルゴリズム
最適解を厳密には出さず、ある程度よい保証付きの解 を返します。
向く場面
- NP 困難問題
- 入力が大きすぎて厳密解が重い問題
例
- 近似頂点被覆
- 巡回セールスマン問題の一部近似
- ビンパッキングの近似
図で見る
| 問題 | 厳密解 | 近似の狙い |
|---|---|---|
| 頂点被覆 | 最小集合を厳密に探す | 十分小さい集合を速く出す |
| TSP | 最短巡回路を探す | かなり短い巡回路を現実時間で出す |
| ビンパッキング | 最少箱数を厳密に探す | 箱数を抑えつつ速く詰める |
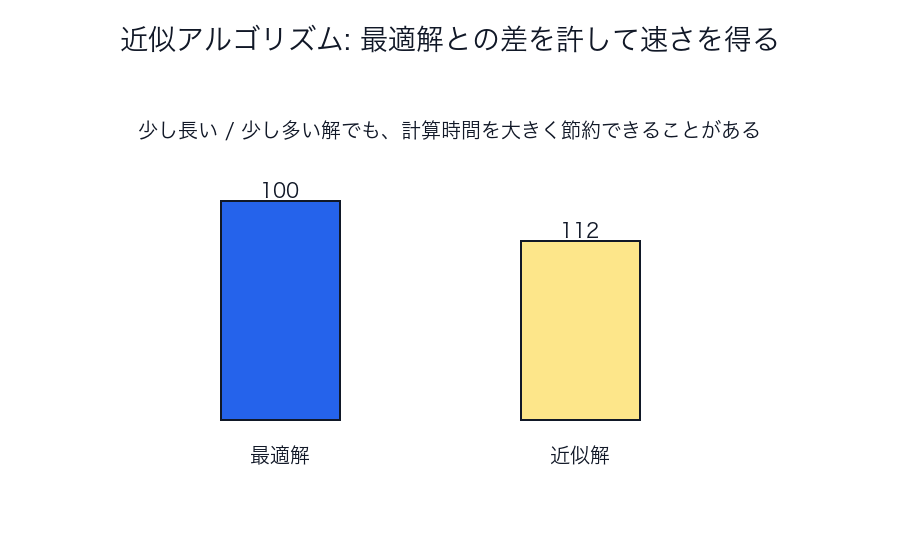
近似アルゴリズムで大切なのは、「最適ではない」こと自体より、
どのくらい悪くて、代わりにどれだけ速いのか が読めることです。
現実の大規模問題では、
- 厳密最適は数時間かかる
- でも数秒で 95% くらい良い解が出れば十分
ということがよくあります。
この発想が、近似アルゴリズムの実務的な価値です。
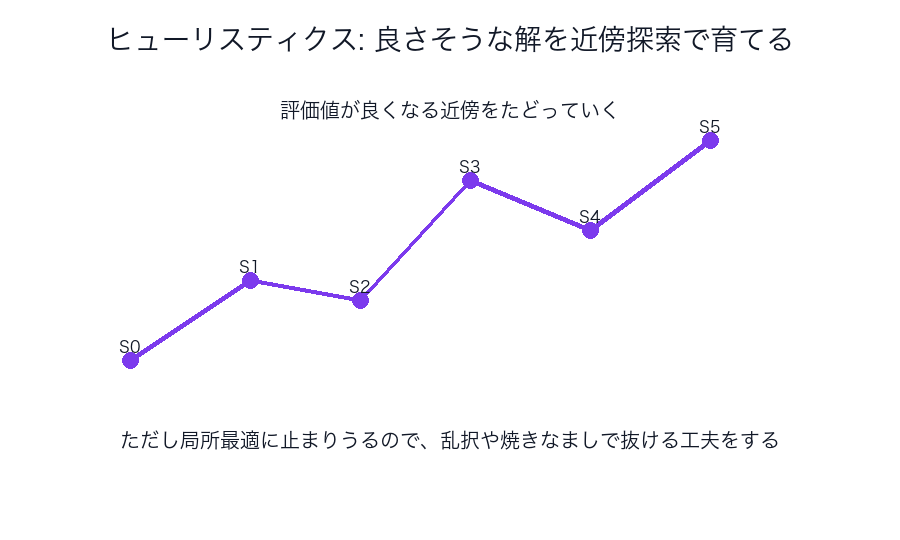
ヒューリスティクス
理論保証より、現実の性能や実用性を重視する考え方です。
代表例
- A* の評価関数
- 局所探索
- 焼きなまし
- 遺伝的アルゴリズム
たとえるなら
「必ず最短の道を証明付きで探す」というより、
「地図と経験を頼りに、かなり良さそうな道を素早く見つける」感じです。
図で見る
ヒューリスティクスは、数学的にきれいな保証より、
現実の制約時間の中で、どれだけマシな答えを出せるか を重視します。
局所探索の図は、「今の解の近くを少しずつ改善する」考え方を表しています。
ただし、山登りの途中で低い谷に閉じ込められるように、局所最適で止まることがあります。
そこで乱択、焼きなまし、複数初期値などの工夫が出てきます。
厳密解との違い
| 観点 | 厳密アルゴリズム | 近似 / ヒューリスティクス |
|---|---|---|
| 正しさ | 最適解を返す | 良い解を返すことを狙う |
| 保証 | 強い | 弱い / 場合による |
| 速度 | 重くなることがある | 実用で有利なことが多い |
図だけで復習
| 図で思い出すこと | 意味 |
|---|---|
| ランダム pivot の図 | 偏った最悪ケースを引きにくくする |
| 近似ギャップの棒図 | 少し悪い解と速さを交換する |
| 局所探索の軌跡 | 近くの良い解へ少しずつ登る |
数値・数論・変換アルゴリズム
アルゴリズムというと探索やグラフが有名ですが、数値計算や数学的処理にも重要なものが多くあります。
二分法とニュートン法
二分法
連続関数 に対して、符号が変わる区間を半分ずつ絞って根を探します。
ニュートン法
接線を使って根へ近づきます。
使い分け
| 手法 | 強み | 注意 |
|---|---|---|
| 二分法 | 安定しやすい | 遅め |
| ニュートン法 | 速く収束することが多い | 初期値や導関数依存 |
図で見る
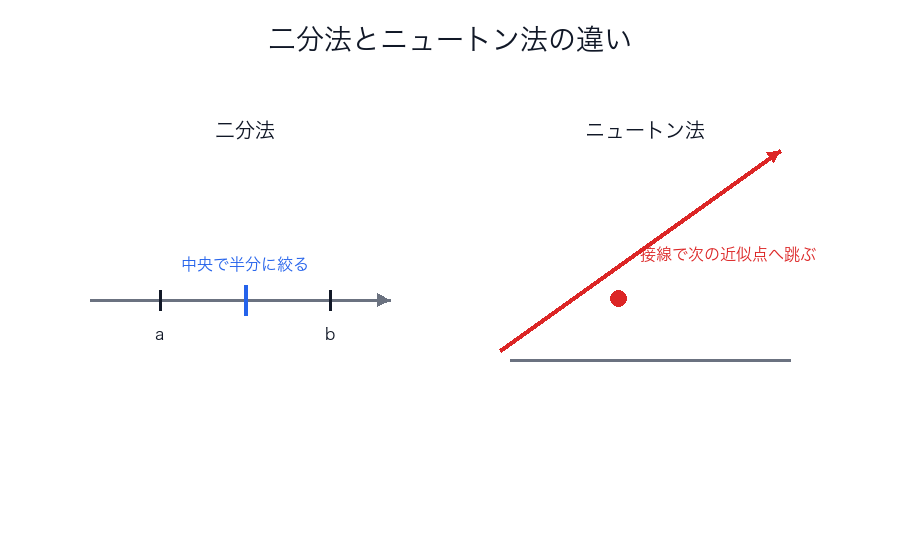
この 2 つの違いは、安定性と速さのトレードオフとして見るとわかりやすいです。
- 二分法は「解をはさむ区間」を壊さないので堅い
- ニュートン法は接線を使うので速いが、飛びすぎることがある
つまり二分法は慎重派、ニュートン法は攻める派です。
最初の近似が怪しいときは二分法、よい初期値や滑らかな関数があるならニュートン法、という見方が役に立ちます。
ユークリッドの互除法
最大公約数を高速に求める古典的アルゴリズムです。
何に使うか
- 既約分数化
- 数論
- RSA のような暗号の土台計算
図で見る
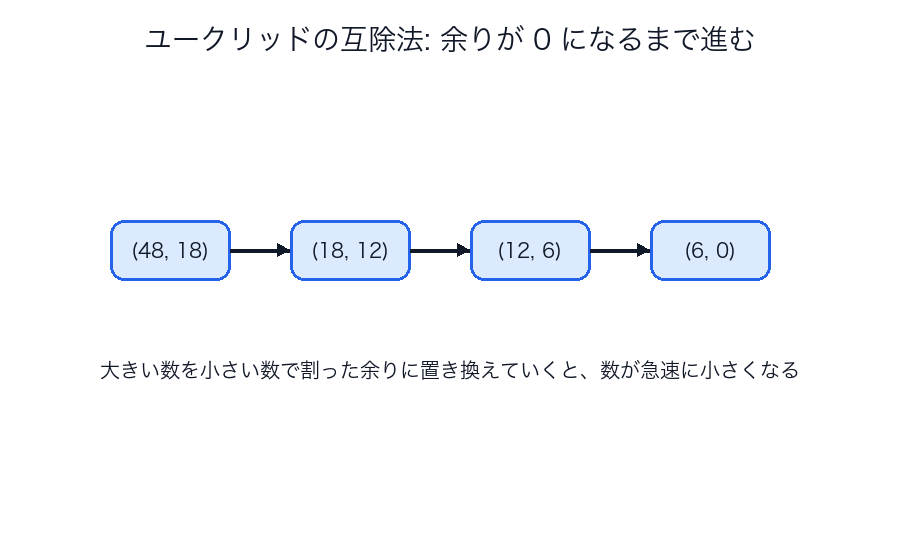
互除法が美しいのは、「最大公約数そのものは変えずに、問題だけを小さくできる」ことです。
大きい数どうしの話を、余りの計算へ落とすことで、数字が急速に縮んでいきます。
この発想は、数学でよくある
- 本質は保つ
- 見た目だけ小さくする
の好例です。だから古典的なのに、今でも現役で強いアルゴリズムです。
高速べき乗
a^n を愚直に n 回掛けるのではなく、二乗しながら進みます。
計算量
何に使うか
- 巨大指数計算
- mod 付きべき乗
- 行列累乗
図で見る
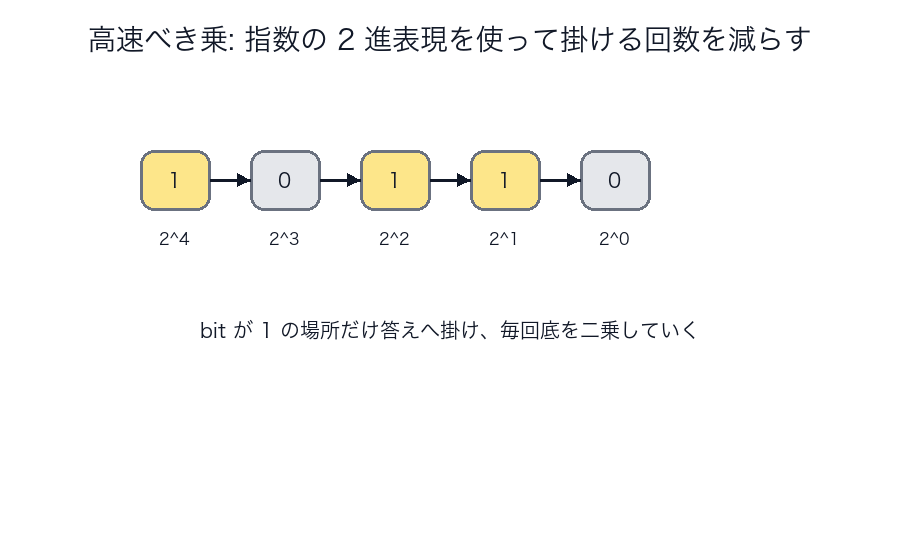
高速べき乗のコツは、「指数を何回掛けるか」ではなく、
指数を 2 進数でどう分解できるか を見ることです。
たとえば 13 なら 1101_2 なので、
- 必要な二乗を作っておき
- bit が 1 の場所だけ掛け合わせる
と考えます。
これで線形回数の掛け算が、対数回数まで一気に減ります。
FFT
高速フーリエ変換は、畳み込みや多項式計算を高速化する有名なアルゴリズムです。
向く場面
- 信号処理
- 画像処理
- 多項式乗算
- 大きな整数乗算の発想
なぜ有名か
愚直な畳み込みが なのに対し、FFT を使うと 級へ落とせるからです。
図で見る
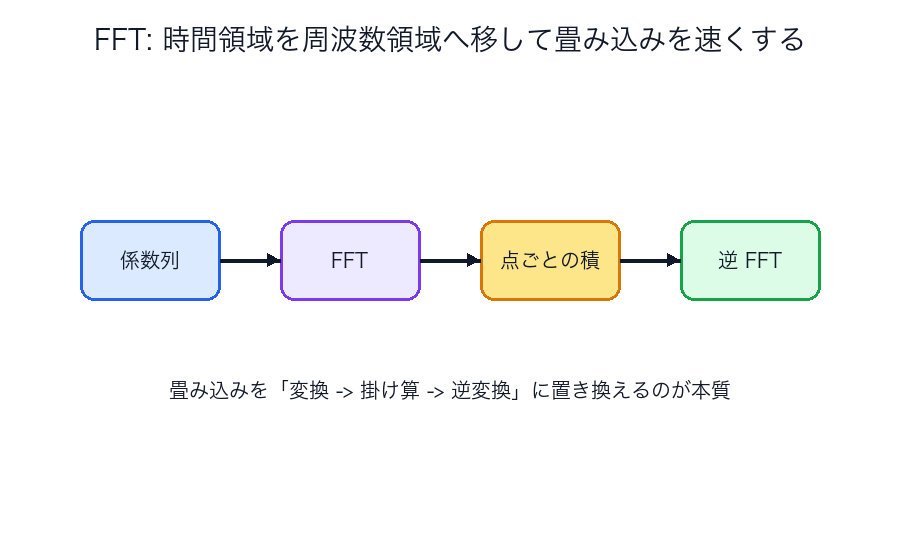
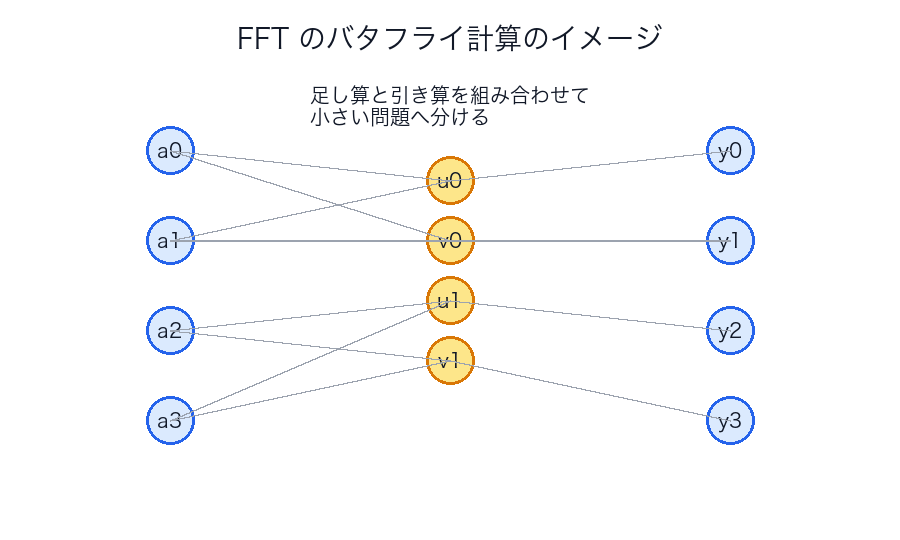
FFT は最初かなり抽象的に見えますが、見方を固定すると楽になります。
- 元の列をそのまま掛け合わせるのは重い
- いったん「掛け算しやすい世界」へ移す
- その世界では点ごとの積で済む
- 最後に元の世界へ戻す
という 4 段階で考えると、だいぶ自然です。
バタフライ図は、その「変換しやすい形へ小問題に分ける」途中経過です。
FFT は単なる数式テクニックではなく、分割統治で計算の形そのものを変えるアルゴリズム だと見ると、急に親しみやすくなります。
図だけで復習
| 図で思い出すこと | 意味 |
|---|---|
| 二分法とニュートン法の比較図 | 安定に絞るか、接線で速く跳ぶか |
| 互除法の列 | 本質を保ったまま問題を小さくする |
| 高速べき乗の bit 図 | 指数を 2 進数で分解して掛け算を減らす |
| FFT の流れ図 | 変換して掛けて戻す |
模擬問題
ここでは、実際に問題文を読んで「何を選ぶか」を練習します。
答えを当てることより、なぜその候補になるのか を言葉にできることが大事です。
模擬問題
- 整列済みの社員 ID 一覧から、ある ID が最初に現れる位置を探したい。どのアルゴリズムをまず疑うべきか。
- 重みがすべて 1 の迷路で、スタートからゴールまでの最短手数を求めたい。どのアルゴリズムが第一候補か。
- 重み付き道路網で、負のコストはなく、1 つの始点から全頂点までの最短距離を求めたい。どのアルゴリズムが自然か。
- 負辺を含む有向グラフで、最短経路だけでなく負閉路の有無も知りたい。何を使うべきか。
- 文字列辞書に対して、前方一致補完を高速にしたい。どのデータ構造が向くか。
- 文字列中で 1 つのパターンを何度も探したい。不一致が起きても本文を戻りすぎたくない。どのアルゴリズムを使うか。
- 辺を軽い順に見ながら、閉路を作らずにグラフ全体を安くつなぎたい。どのアルゴリズムが第一候補か。
- 同じ部分問題が何度も出てきて、表を埋めていくと答えが作れそうだ。どの設計パラダイムを疑うべきか。
- 指数がとても大きい
a^nを高速に計算したい。どの発想が効くか。 - 最適解は重すぎるが、かなり良い解を短時間で出したい。どの方向のアルゴリズムを考えるべきか。
模範解答と考え方
| 問題 | 第一候補 | 考え方 |
|---|---|---|
| 1 | 二分探索 | 整列済みで、しかも「最初の位置」という境界探索だから |
| 2 | BFS | 重みが一律なので、層ごとに広がれば最短手数になるから |
| 3 | Dijkstra | 非負重みの単一始点最短経路だから |
| 4 | Bellman-Ford | 負辺と負閉路を扱いたいから |
| 5 | Trie | 接頭辞を共有でき、前方一致検索と相性が良いから |
| 6 | KMP | 不一致時に prefix 情報を再利用できるから |
| 7 | Kruskal | 辺を軽い順に選ぶ、という記述と一致するから |
| 8 | 動的計画法 | 重複部分問題と表埋めというヒントがあるから |
| 9 | 高速べき乗 | 指数を 2 進分解して掛け算回数を減らせるから |
| 10 | 近似アルゴリズム / ヒューリスティクス | 厳密最適より、短時間で十分良い解が欲しいから |
選び方のミニ指針
整列済みが見えたら、まず二分探索を疑う最短手数なら BFS、重み付き最短なら Dijkstra 系を疑う負辺が見えたら Dijkstra の前提を疑う前方一致は Trie、1 パターン検索は KMP を疑う表を埋める、同じ部分問題は DP の匂い厳密最適は重いと書いてあれば、近似やヒューリスティクスを考える
図だけで復習
| 図で思い出すこと | そこから疑う候補 |
|---|---|
| 範囲が半分に縮む図 | 二分探索 |
| 層ごとに広がる図 | BFS |
| 重み付きで距離が確定する図 | Dijkstra |
| 全辺を何度も緩和する図 | Bellman-Ford |
| 接頭辞を共有する木 | Trie |
| bit を見ながら掛ける図 | 高速べき乗 |
学習の順番
初学者には次の順序がおすすめです。
- 線形探索、二分探索
- バブルソート、挿入ソート、マージソート
- スタック、キュー、ヒープ
- BFS、DFS
- Dijkstra、Kruskal、Union-Find
- 分割統治、DP、貪欲法
- KMP、Trie など文字列アルゴリズム
なぜこの順番か
- まず「探す・並べる」で計算量感覚をつける
- 次にキューやヒープで道具を増やす
- そのうえでグラフへ行く
- 最後に抽象度の高い設計パラダイムへ進む
超短縮まとめ
- 探索: 線形探索は単純、二分探索は速いが整列前提
- ソート: マージソートは安定、クイックソートは速いことが多い
- グラフ: BFS は層、DFS は深さ、Dijkstra は重み付き最短経路
- 設計法: 分割統治、DP、貪欲法は発想の型
- 文字列: KMP は効率的検索、Trie は前方一致
- 補助構造: ヒープ、Union-Find、ハッシュテーブルは頻出
アルゴリズム学習のコツは、「名前を覚える」より
どんな問題に出会ったら、その道具を思い出すか を覚えることです。
実務ケーススタディ
キャッシュキーの高速検索
問題: キー一意で、順序より高速参照が重要。
選択: ハッシュテーブル
cache = {}
cache['user:123'] = user_data # O(1) 平均
value = cache.get('user:123') # O(1) 平均
順序つきランキング
問題: 「上位 100 件」や「この値以上」を頻繁に扱う。
選択: 平衡木(ソート済み構造)
from sortedcontainers import SortedList
ranking = SortedList()
ranking.add((score, user_id))
top_100 = ranking[-100:] # 上位 100 件
ジョブスケジューラ
問題: 「次に期限が近い仕事を取り出したい」を繰り返す。
選択: ヒープ
import heapq
job_queue = []
heapq.heappush(job_queue, (deadline, job_id))
next_job = heapq.heappop(job_queue)
オートコンプリート
問題: 候補の接頭辞共有。
選択: Trie
# Trie の例で既に示した
# "apple", "app", "apply" を統一プレフィックスで管理
地図経路検索
問題: スタートからゴールまでの最短路。
選択: Dijkstra + 隣接リスト
# Dijkstra の例で既に示した
依存関係解析
問題: 循環参照の検出、トポロジカルソート。
選択: 有向グラフ + DFS / Tarjan
# 依存関係グラフで SCC を計算
sccs = kosaraju(dependency_graph)
if len(sccs[0]) > 1:
print("循環依存あり")
実装とデータ配置
同じ計算量でも、実装や配置でかなり差が出ます。
- 配列は局所性が高く、実時間で強いことが多い
- ポインタを多用する構造は理論上よくても実メモリで不利なことがある
- 再帰はきれいだが、スタックや定数倍の都合がある
だから「Big-O が同じだから同じ」ではありません。理論の形と、実際に CPU とメモリの上でどう動くかの両方を見る必要があります。
キャッシュ局所性の重要性
# 例 1: 行優先(局所性が良い)
def row_major_access(matrix):
total = 0
for i in range(len(matrix)):
for j in range(len(matrix[0])):
total += matrix[i][j]
return total
# 例 2: 列優先(局所性が悪い)
def col_major_access(matrix):
total = 0
for j in range(len(matrix[0])):
for i in range(len(matrix)):
total += matrix[i][j]
return total
# row_major_access の方が実時間では高速
比較で理解する
配列と連結リスト
- 配列: 添字アクセスと局所性に強い
- 連結リスト: 途中の挿入削除の発想はわかりやすいが、実メモリ効率では不利になりやすい
教科書上の性質と、現代 CPU 上の実際の強さは少しずれることがあります。
ハッシュテーブルと平衡木
- ハッシュテーブル: 平均的一点検索に強い
- 平衡木: 順序と範囲検索、最悪保証に強い
どちらが速いかではなく、何を速くしたいかで選ぶのが自然です。
BFS と DFS
- BFS: 重みなし最短路、層構造の把握
- DFS: トポロジカルソート、SCC、回文検出
判断の指針
アルゴリズムやデータ構造で迷ったときは、
- 何の操作が支配的か
- 入力規模はどれくらいか
- 順序や範囲が必要か
- 更新が多いか読み取りが多いか
- 実装の複雑さに見合うか
を先に見ると整理しやすいです。
典型的な判断例
- 小規模データ: 単純な配列やソートで十分なことが多い
- 順序つき検索: 木やソート済み構造を考える
- 一点検索中心: ハッシュが自然になりやすい
- 最短路: 重みの有無で BFS と Dijkstra 系を分ける
よくある誤解
- Big-O は実際の秒数だと思う → 計算量は相対的な増え方であり、定数倍や環境に依存
- は絶対一定時間だと思う → ハッシュの 平均も、ブロードキャストや I/O は含まない
- 最速アルゴリズムはいつでも同じだと思う → 入力サイズや分布、メモリ環境で変わる
- 万能なデータ構造があると思う → 各構造は特定の操作に最適化されている
発展ルート
アルゴリズムの学習を進める方向。
アルゴリズム設計パターンの深掘り
- 分割統治の定式化(マスター定理)
- DP の状態設計(多次元化、確率的最適化)
- 貪欲法の証明(交換論法、マトロイド理論)
- 近似アルゴリズム(TSP 近似、PTAS)
グラフの高度なアルゴリズム
- 最大フロー・最小カット(Ford-Fulkerson、Dinic)
- 二部マッチング(Hungarian アルゴリズム)
- フロー応用(最小コスト流、循環流)
データ構造の応用
- 平衡木の詳細(回転、再バランス)
- Skip List(確率的バランス木)
- Fenwick Tree(Binary Indexed Tree)
- Bloom Filter(確率的データ構造)
計算量の先端
- PRAM(並列ランダムアクセスマシン)
- 外部メモリモデル
- キャッシュ意識アルゴリズム
- 並列アルゴリズム(prefix sum、parallel sort)
確率的・ラスベガス・モンテカルロ
- Randomized QuickSort(期待値 O(n log n))
- HyperLogLog(近似カウント)
- Count-Min Sketch(周度数推定)
NP 困難への対処
- 決定不能性(停止問題)
- NP 完全問題
- 近似と勾配法
ここで出てくる NP 困難 の意味そのものは、計算可能性と計算量 側で整理しています。
FAQ
まず配列でいいのはどんなときか
件数が小さい、実装を単純にしたい、局所性を活かしたい、といった場面では配列はとても強いです。理論上もっとよい構造があっても、配列で十分なことは多いです。
ハッシュと木はどちらが速いのか
平均的な一点検索ならハッシュが強いことが多いですが、順序、範囲検索、最悪保証まで含めると木が有利です。何を速くしたいかで答えが変わります。
グラフアルゴリズムは全部覚えるべきか
丸暗記より、「どんな問いに答える道具か」で整理するほうが強いです。最短路、全体接続、構造分解、到達可能性、という軸で分けると混乱しにくくなります。
DP の状態遷移が分からない
「何が変わるか」を問いから逆算する。最小値・最大値・個数を求めるなら、部分問題を「i まで見た」「i を選んだ/選ばない」といった軸で切る。
ミニ比較表
| 概念 | 強い場面 | 苦手な場面 | 時間計算量 |
|---|---|---|---|
| 線形探索 | ソート不要、小規模 | 大規模な探索 | O(n) |
| 二分探索 | ソート済み、大規模 | ソートのコスト | O(log n) |
| ハッシュテーブル | 一点検索 | 順序や範囲検索 | O(1) 平均 |
| 平衡木 | 順序つき検索、範囲検索 | 定数倍を気にする一点検索 | O(log n) |
| ヒープ | 最小値・最大値の反復取り出し | 任意要素の検索 | O(log n) |
| BFS | 重みなし最短路 | 重み付き最短路 | O(V+E) |
| DFS | トポロジカル、SCC | 最短路 | O(V+E) |
| Dijkstra | 非負重み最短路 | 負辺を含む最短路 | O((V+E)log V) |
| Bellman-Ford | 負辺あり最短路 | 大規模で高速性が最優先 | O(V·E) |
| Kruskal | 最小全域木 | 密なグラフ | O(E log E) |
実務チェックリスト
- 問いは「一点検索」「順序」「範囲」「最短路」のどれか
- 入力サイズが増えたときの増え方を見ているか
- データ構造は操作の中心に合っているか
- 理論だけでなく局所性や定数倍も見ているか
- 全件処理が本当に必要かを疑ったか
模範解答例
例: なぜ BFS が自然か
辺重みがすべて同じなら、距離は「何本の辺を通るか」で決まります。BFS は層ごとに 1 本先、2 本先、3 本先と広がるので、そのまま最短路探索になります。重み付き最短路の一般解を持ち出すより、問題の性質に合っています。
例: 平衡木を選ぶ場面
一点検索だけならハッシュテーブルが強いことが多いですが、順序、範囲検索、最悪時の保証が必要なら平衡木が自然です。たとえば「この値以上を列挙する」「常に整列順で保ちたい」といった要求では木の強みが出ます。
章末まとめ
- アルゴリズムは手順、データ構造は置き方
- Big-O は増え方を見る道具で、実時間そのものではない
- 問題の問い方によって最適な構造は変わる
- BFS, DFS, Dijkstra などは「何に答えるか」で整理すると覚えやすい
- 理論だけでなく局所性や定数倍も現実には大きい
次に読むなら
- CPU とメモリの実行面: CPU メモリ
- 分散や非同期へ進む: 並行性と分散システム
関連資料
補足
第3章 アルゴリズムと計算量
この章が実務で役立つ場面
- API やバッチが遅いときの原因切り分け
- 探索、ソート、最短経路のような基本処理の選択
- コードレビューで「大きくなったらどう悪化するか」を見られる
3.1 アルゴリズムとは
アルゴリズムは、問題を解くための明確な手順です。
たとえば「配列の中から最大値を探す」なら、
- 先頭を仮の最大値とする
- 残りを順に見る
- より大きければ更新する
という流れになります。
3.2 何に似ているか
アルゴリズムは「答えに至るレシピ」に似ています。ただし、料理と違って曖昧さが許されず、すべての入力に対して手順が明確である必要があります。
3.3 どう見るべきか
アルゴリズムを読むときは、次の観点で見ると理解しやすいです。
- 入力は何か
- 出力は何か
- 正しさはなぜ言えるか
- 何回くらい処理するか
- 追加メモリはどれくらい使うか
3.4 計算量
アルゴリズムは、正しく動くだけでなく、どれくらい速く動くかも重要です。
ここで使うのが 時間計算量 と 空間計算量 です。
- 時間計算量: 実行時間が入力サイズに対してどう増えるか
- 空間計算量: 追加メモリが入力サイズに対してどう増えるか
3.5 Big-O 記法
Big-O 記法は、入力サイズ n が大きくなったときに、実行時間やメモリ使用量が どのくらいの勢いで増えるか を表す記法です。ここで見たいのは「今この PC で何ミリ秒か」ではなく、「データが 10 倍、100 倍になったときに、どれくらい苦しくなるか」です。
まず直感で見る
- : 入力が増えても、ほぼ増えない
- : ゆっくり増える
- : 入力に比例して増える
- : 実用でよく出る、比較的よい増え方
- : 入力が大きくなると急につらくなる
- , : 少し大きくなるだけで現実的でなくなりやすい
【図5-1】代表的な Big-O の増え方( までを見やすく比較 ):

この図でとくに大事なのは、 が「入力が大きくなってもかなり増えにくい」ことです。これは、二分探索のように 毎回問題サイズを半分へ減らす 処理でよく出ます。
たとえば、要素数が
- なら、半分にできる回数はだいたい
3回 - なら、だいたい
4回 - なら、だいたい
5回
です。つまり、入力を 2 倍にしても回数は 1 しか増えません。これが がかなり強い理由です。
【図5-2】 と の比較:

が直感的に大きく見えにくいのは、! の意味に慣れていないからです。 なので、
なので、2^n よりかなり急激に増えます。たとえば
- に対して
4! = 24 - に対して
8! = 40320
です。入力サイズが少し増えただけで、差が一気に開きます。
何をしている記法なのか
Big-O は、細かい定数や低次の項を捨てて、最終的にいちばん支配的な増え方だけを残します。
たとえば、手順数が だったとします。n が十分大きくなると、 の項が他を圧倒するので、 と書きます。
つまり Big-O では、
3のような定数倍+10nのような低次項+5のような定数項
を捨てて、大きくしたときにいちばん効く形 だけを見ます。
数学的には何を意味しているか
とは、ざっくりいうと「十分大きい n に対して、 は定数倍した 以下に抑えられる」という意味です。より厳密には、
です。
この式を最初から暗記する必要はありませんが、「上からの大づかみな抑え」だという感覚は大切です。
よく出るオーダー
| 記法 | 典型例 | 直感 |
|---|---|---|
| 配列先頭アクセス、スタック push/pop | 入力サイズに依らない | |
| 二分探索、平衡木検索 | 半分ずつ減る | |
| 線形探索、全件走査 | 1 個ずつ見る | |
| マージソート、ヒープソート | 分割しつつ全体も見る | |
| 二重ループ、単純比較ソート | 全組み合わせに近い | |
| 部分集合全探索 | 少し大きくても厳しい | |
| 順列全探索 | すぐ現実的でなくなる |
成長の順番
これは「必ずこの順に実行時間が短い」という意味ではなく、入力を十分大きくしたときの増え方 として左の方が有利だという意味です。
時間計算量と空間計算量
Big-O は、時間だけでなくメモリにも使います。
- 時間計算量: 入力サイズに対して処理時間がどう増えるか
- 空間計算量: 入力サイズに対して追加メモリがどう増えるか
たとえば、長さ n の新しい配列を 1 本追加で作るなら、追加メモリは です。
例1: 配列の最大値を探す
def max_value(arr):
m = arr[0]
for x in arr:
if x > m:
m = x
return m
配列を先頭から最後まで 1 回見るので、要素数を n とすると時間計算量は です。
例2: 配列の先頭要素を読む
x = arr[0]
要素数が 10 個でも 100 万個でも、読む回数は変わらないので です。
例3: 二重ループ
for i in range(n):
for j in range(n):
do_something()
外側が n 回、内側も毎回 n 回なので、 です。
なぜ定数を無視してよいのか
たとえば 100n と を比べると、小さい n では 100n の方が大きく見えることもあります。しかし n が十分大きくなると、 の方が急激に増えていきます。Big-O は、その「最終的にどちらが支配的か」を見るため、定数倍を無視します。
Big-O は実測時間と同じではない
これは非常に重要です。同じ でも、
- 定数倍
- キャッシュ効率
- 分岐予測
- 言語処理系
- I/O の有無
で実際の速度は大きく変わります。
Big-O は「大づかみな増え方」を比較する道具であって、「このコードは 23ms です」と言う道具ではありません。
よくある誤解
-
は遅く、 は速いとだけ覚える
実際は入力サイズや定数倍次第で逆転もあります。 -
Big-O は最悪時間だけを見ると思う
典型的には最悪時間で語ることが多いですが、平均計算量やならし計算量も重要です。 -
Big-O が同じなら性能も同じと思う
実装、メモリアクセス、ライブラリ最適化で大きく差が出ます。
Big-O、Big-Theta、Big-Omega
- : 上からの抑え
- : 下からの抑え
- : だいたい同じオーダー
たとえば なら、その関数は と同じくらいの勢いで増える、という意味です。実務ではまず を読めれば十分ですが、理論ではこの 3 つを使い分けます。
Big-O を読むための手順
- 何が入力サイズ
nなのか決める - いちばん外側のループが何回回るか見る
- 入れ子なら掛け算する
- 問題サイズが半分になるなら を疑う
- 再帰なら「分割数」と「統合コスト」を見る
- 最後に支配項だけ残して Big-O に直す
【図5】Big-O 記法の役割:
3.6 線形探索と二分探索
線形探索
先頭から順に見るので単純ですが、最悪 です。
二分探索
ソート済み配列なら、真ん中を見て範囲を半分ずつ減らせるので です。
【図6】二分探索の手順:
【図6-2】二分探索で探索範囲が縮むイメージ:

3.7 ソートの直感
- バブルソート: 単純だが遅い
- マージソート: 分割してからマージする
- クイックソート: ピボットで分けて整理する
ここで大切なのは、「速いアルゴリズムは、無駄な比較や移動を減らす工夫をしている」という視点です。
【図6-3】マージソートとクイックソートの考え方:
ソートの比較表
| アルゴリズム | 平均計算量 | 最悪計算量 | 空間 | 安定 | 特徴 |
|---|---|---|---|---|---|
| バブル | 安定 | 教育用、実用には遅い | |||
| 選択 | 不安定 | 比較少、交換多 | |||
| 挿入 | 安定 | ほぼ整列済みなら | |||
| マージ | 安定 | 常に高速、メモリ要 | |||
| クイック | 不安定 | 平均最速、最悪に注意 | |||
| ヒープ | 不安定 | 最悪保証、メモリ少 | |||
| Timsort | 安定 | Python 標準、Java の一部 |
安定ソート(stable sort):同じキーを持つ要素の相対順序が保持される。複数フィールドでのソートでは安定性が重要。
3.7.1 Timsort — Python と Java の標準
Python の sorted() と list.sort() は Timsort(2002 年 Tim Peters 開発)を使います。Java はオブジェクト配列では Timsort 系ですが、プリミティブ配列は別系統の実装です。
- 実データに多い「部分的に整列済み」な配列で高速
- マージソートと挿入ソートのハイブリッド
- 最小実行(minrun)を検出し、小さい部分は挿入ソート、長くなったらマージ
- 実データでしばしば に近い性能を発揮
3.8 分割統治・動的計画法・貪欲法
分割統治(Divide and Conquer)
問題を小さな部分問題に分割 → 再帰的に解く → 統合。マージソート、クイックソート、高速フーリエ変換(FFT)、Karatsuba 整数乗算。
動的計画法(Dynamic Programming, DP)
部分問題の解を記憶(メモ化)して再利用。フィボナッチ、ナップサック問題、最長共通部分列(LCS)、編集距離(Levenshtein)、Bellman-Ford。
# フィボナッチ(ナイーブ:$O(2^n)$)
def fib_naive(n):
return n if n < 2 else fib_naive(n-1) + fib_naive(n-2)
# メモ化 DP($O(n)$)
def fib_dp(n, memo=None):
if memo is None:
memo = {}
if n < 2:
return n
if n in memo:
return memo[n]
memo[n] = fib_dp(n-1, memo) + fib_dp(n-2, memo)
return memo[n]
貪欲法(Greedy)
各ステップで局所的に最良を選び続ける。全体最適が保証される問題(Dijkstra、Kruskal、Huffman 符号)と、しない問題(一般のナップサック)がある。
【図6-4】問題に応じた解法パターンの選び方:
3.9 グラフアルゴリズム
- BFS(幅優先探索):最短経路(エッジ重みが一律)、
- DFS(深さ優先探索):連結成分、トポロジカルソート、サイクル検出
- Dijkstra:非負重み付きグラフの最短経路、
- Bellman-Ford:負重みを許すが
- Floyd-Warshall:全点対最短経路、
- A*:ヒューリスティクス付き探索、ゲームAI・カーナビで有名
- Kruskal/Prim:最小全域木
- Tarjan/Kosaraju:強連結成分
ここでの V は頂点数、E は辺数です。BFS や DFS が になるのは、隣接リスト表現を前提にすると、各頂点を高々 1 回ずつ取り出し、各辺も高々 1 回ずつたどるからです。
3.9.1 それぞれ何をしているのか
ここも木の一覧と同じで、名前だけ並ぶと一気に抽象度が上がります。まずは「どんな問いに答えるアルゴリズムなのか」で見ると整理しやすいです。
最初に大づかみすると、グラフアルゴリズムは主に次の 4 系統へ分かれます。
- 探索系: どこまで行けるか、どんな構造かを見る
- 最短経路系: ある点からある点へ最も安く行く方法を探す
- 全体構造系: グラフ全体を安くつなぐ、あるいは全点対距離を求める
- 強連結成分系: 有向グラフの中で相互到達できる塊を見つける
【図6-5】グラフアルゴリズムの役割の全体像:
さらに、入力と出力で並べると違いが見えやすくなります。
| アルゴリズム | 主な入力 | 主な出力 | 何を一番知りたいときに使うか |
|---|---|---|---|
| BFS | グラフ、始点 | 到達可否、最短手数、親配列 | 重みなしの最短手数 |
| DFS | グラフ、始点 | 到達可否、訪問順、帰りがけ順 | 構造把握、閉路、順序 |
| Dijkstra | 非負重みグラフ、始点 | 最短距離、最短経路木 | 負辺なしの最短距離 |
| Bellman-Ford | 重み付きグラフ、始点 | 最短距離、負閉路検出 | 負辺ありの最短距離 |
| Floyd-Warshall | 重み付きグラフ全体 | 全点対距離行列 | 全頂点どうしの距離 |
| A* | グラフ、始点、終点、ヒューリスティクス | ゴールまでの経路 | 目的地が明確な探索 |
| Kruskal / Prim | 連結無向重み付きグラフ | 最小全域木 | 全体を安くつなぎたい |
| Tarjan / Kosaraju | 有向グラフ | 強連結成分の分割 | 相互依存の塊を知りたい |
BFS(幅優先探索)
BFS は、始点から近い順に層を広げる探索です。
-
入力: グラフと始点
-
出力: 各頂点への最短手数、到達可否、親子関係
-
コアの考え方: 「近い層から先に確定する」
-
何が得意か: 辺の重みが全部同じときの最短経路
-
どう動くか: キューを使って、距離 1、距離 2、距離 3… と波のように広がる
たとえるなら、水面に石を落としたときの波紋です。近いところから順に届くので、「最初に見つけた到達」が最短になりやすいわけです。
迷路、最短手数、SNS の「何人先の友達か」のような問題でよく使います。
BFS(G, s):
queue <- [s]
dist[s] <- 0
visited[s] <- true
while queue is not empty:
u <- pop_front(queue)
for each v in adj[u]:
if not visited[v]:
visited[v] <- true
dist[v] <- dist[u] + 1
parent[v] <- u
push_back(queue, v)
DFS(深さ優先探索)
DFS は、行けるところまで深く潜ってから戻る探索です。
-
入力: グラフと始点
-
出力: 到達可否、訪問順、帰りがけ順、木辺や後退辺の情報
-
コアの考え方: 「1 本の道を最後まで掘ってから戻る」
-
何が得意か: 連結性、サイクル検出、トポロジカルソートの土台
-
どう動くか: スタックや再帰で「潜る → 行き止まりで戻る」を繰り返す
たとえるなら、洞窟探索です。まず一本の道を奥まで進み、行き止まりになったら戻って別の道へ行きます。
「最短距離」そのものより、構造を調べるのが得意だと思うとよいです。
DFS(u):
visited[u] <- true
for each v in adj[u]:
if not visited[v]:
parent[v] <- u
DFS(v)
finish_order.append(u)
Dijkstra
Dijkstra は、重みが負でない グラフでの最短経路アルゴリズムです。
-
入力: 非負重み付きグラフと始点
-
出力: 始点から各頂点への最短距離、必要なら親配列
-
コアの考え方: 「いま最短だと確定できる頂点から順に広げる」
-
何が得意か: 道の長さやコストが違う最短経路
-
どう動くか: いま一番近いと確定した頂点から順に広げる
BFS が「全部同じ長さの道」だとすると、Dijkstra は「道ごとに長さが違う地図」を扱う感じです。
優先度付きキューと相性がよいのは、「次に一番近い候補」をすばやく取り出したいからです。
Dijkstra(G, s):
dist[*] <- inf
dist[s] <- 0
pq <- {(0, s)}
while pq is not empty:
(d, u) <- extract_min(pq)
if d > dist[u]: continue
for each edge (u, v, w):
if dist[v] > dist[u] + w:
dist[v] <- dist[u] + w
parent[v] <- u
push(pq, (dist[v], v))
Bellman-Ford
Bellman-Ford は、負の重み を含んでも扱える最短経路アルゴリズムです。
-
入力: 重み付きグラフと始点
-
出力: 最短距離、負閉路の有無
-
コアの考え方: 「全辺を何度も見直して距離を改善する」
-
何が得意か: 負辺を含むグラフ
-
代償: Dijkstra より遅い
何度も辺を緩和して、「もっと短い道がないか」を全体に行き渡らせるイメージです。
さらに重要なのは、負閉路 の検出もできることです。つまり「回れば回るほど得してしまうような異常なコスト構造」に気づけます。
BellmanFord(G, s):
dist[*] <- inf
dist[s] <- 0
repeat |V|-1 times:
for each edge (u, v, w):
if dist[u] != inf and dist[v] > dist[u] + w:
dist[v] <- dist[u] + w
parent[v] <- u
for each edge (u, v, w):
if dist[u] != inf and dist[v] > dist[u] + w:
report negative cycle
Floyd-Warshall
Floyd-Warshall は、全頂点対の最短経路 を一気に求めるアルゴリズムです。
-
入力: 重み付きグラフ全体
-
出力: すべての頂点どうしの距離行列
-
コアの考え方: 「中継点を 1 つずつ許して距離表を更新する」
-
何が得意か: すべての点どうしの距離を知りたい
-
代償: なので頂点数が大きいと重い
直感的には、「中継点として k 番を使ってよいなら距離は縮むか?」を順に試していく動的計画法です。
少数ノード間の全体距離表、経路表、到達性の閉包などに向きます。
| 更新前 | 中継点 k を使う | 更新後 |
|---|---|---|
dist[i][j] |
dist[i][k] + dist[k][j] と比較 |
小さい方を採る |
FloydWarshall(G):
dist <- initial distance matrix
for k in V:
for i in V:
for j in V:
dist[i][j] <- min(
dist[i][j],
dist[i][k] + dist[k][j]
)
A*
A* は、ゴールへ近そうな方向をうまく優先する探索です。
-
入力: グラフ、始点、終点、ヒューリスティクス
-
出力: ゴールまでの経路
-
コアの考え方: 「これまでの良さ + これからの見込み」で候補を選ぶ
-
何が得意か: 目的地がはっきりしている経路探索
-
どう動くか: これまでの距離 + ゴールまでの見込み距離で候補を選ぶ
ここで使う「見込み距離」がヒューリスティクスです。カーナビやゲーム AI で有名なのは、ゴールが決まっていて「全体を隅から隅まで探したくない」からです。
AStar(G, start, goal, h):
g[start] <- 0
open <- {(h(start), start)}
while open is not empty:
(_, u) <- extract_min(open)
if u == goal: return reconstruct_path(parent)
for each edge (u, v, w):
cand <- g[u] + w
if cand < g[v]:
g[v] <- cand
parent[v] <- u
f[v] <- g[v] + h(v)
push(open, (f[v], v))
Kruskal / Prim
この 2 つは最小全域木を求めます。最小全域木は、「全部をつなぎたいが、余計な輪は作らず、総コストを最小にしたい」という問題です。
-
入力: 連結な無向重み付きグラフ
-
出力: 最小全域木を構成する辺の集合
-
コアの考え方: 「全体をつなぐが、閉路は作りすぎない」
-
Kruskal: 辺を軽い順に見て、閉路を作らないものを採る
-
Prim: いまの木から一番安く外へ伸びる辺を足す
どちらも同じ問題を解きますが、考え方が少し違います。
ネットワーク設計や配線コスト最小化のたとえで考えるとイメージしやすいです。
| 観点 | Kruskal | Prim |
|---|---|---|
| 見る単位 | 辺を全体から選ぶ | 木を 1 本育てる |
| 相性がよい道具 | Union-Find | 優先度付きキュー |
| 直感 | 森をあとでつなぐ | 1 本の木を外へ伸ばす |
Kruskal(G):
sort edges by weight
uf <- UnionFind(V)
for each edge (u, v, w):
if uf.find(u) != uf.find(v):
add edge to MST
uf.union(u, v)
Prim(G, s):
mark s as inside tree
push edges from s into pq
while pq is not empty:
edge (u, v, w) <- extract_min(pq)
if v is already inside tree: continue
add edge to MST
mark v as inside tree
push edges from v into pq
Tarjan / Kosaraju
この 2 つは強連結成分を求めます。強連結成分とは、「その集合の中では、どこからどこへも行って戻ってこられる」まとまりです。
-
入力: 有向グラフ
-
出力: 強連結成分ごとの頂点集合
-
コアの考え方: 「相互到達できる塊へ分解する」
-
Tarjan: DFS の1回の流れの中でうまく見つける
-
Kosaraju: 逆向きグラフも使って整理する
依存関係解析、コンパイラ、到達可能性のまとまりの抽出などで役立ちます。
Kosaraju(G):
run DFS on G and record finish_order
reverse all edges to build G^R
for u in reverse(finish_order):
if not visited[u] in G^R:
collect one SCC by DFS from u
3.9.2 どう使い分けるか
ざっくり言うと、次のように見ると迷いにくいです。
| アルゴリズム | 何を知りたいか | 向く条件 |
|---|---|---|
| BFS | 最短手数 | 辺の重みが一律 |
| DFS | 構造把握 | 到達性、閉路、順序 |
| Dijkstra | 最短距離 | 負辺なし |
| Bellman-Ford | 最短距離 | 負辺あり |
| Floyd-Warshall | 全点対距離 | 頂点数が比較的小さい |
| A* | ゴールまでの経路 | よいヒューリスティクスがある |
| Kruskal / Prim | 全体を安くつなぐ | 最小全域木 |
| Tarjan / Kosaraju | 強連結成分 | 有向グラフのまとまり |
3.9.3 最初に何を見分けるべきか
グラフ問題で大事なのは、いきなりアルゴリズム名を当てにいくことではありません。先に「この問題は何を聞いているのか」を分解すると、かなり選びやすくなります。
見るべき問いは主に次の 5 つです。
- グラフは 有向 か 無向 か
- 辺に 重み があるか
- その重みに 負の値 がありうるか
- 欲しいのは 1つの始点からの距離 か、全点対距離 か
- 欲しいのは 経路 か、構造 か、全体をつなぐ最小コスト か
たとえば、
- 「迷路を最短手数で抜けたい」なら BFS
- 「道路ごとの距離が違う地図で最短経路を知りたい」なら Dijkstra
- 「負のコストもある経路問題」なら Bellman-Ford
- 「街どうし全部の距離表を作りたい」なら Floyd-Warshall
- 「ネットワーク全体を最小コストでつなぎたい」なら Kruskal / Prim
というふうに、問いの形からかなり自然に分かれます。
【図6-6】グラフアルゴリズムのざっくり選び方:
3.9.4 最短経路で繰り返し出る「緩和」とは何か
最短経路アルゴリズムを理解するときの中心概念が 緩和(relaxation) です。
緩和とは、ある辺 u -> v を見たときに、
- いま知っている
vまでの距離 uまで来てからその辺を使った距離
を比べて、後者の方が短ければ更新することです。
式で書くと、
なら
です。
直感的には、「もっと近い行き方を見つけたら、暫定メモを書き換える」作業です。Dijkstra も Bellman-Ford も本質的にはこれを繰り返しています。違いは、
- Dijkstra: いま最も近い頂点から順に、賢く緩和する
- Bellman-Ford: 全辺を何度も見直して、愚直に緩和する
という戦略の差です。
3.9.5 BFS をもう少し丁寧に見る
BFS の肝は、「始点からの距離が 0, 1, 2, 3… の順に頂点が確定していく」ことです。
たとえば、
- 始点
S Sの隣にA,BAの先にC
があるなら、BFS は
- まず
S - 次に距離 1 の
A,B - そのあと距離 2 の
C
という順で見ていきます。
この順番になるので、最初に到達した時点の距離が最短手数 になります。
キューを使う理由もここにあります。先に入れた「近い層」を先に処理したいからです。
実務では、
- 最短クリック数
- 最短手数
- 未重みグラフ上の到達範囲
- SNS のホップ数
のような「1歩ずつ進む世界」でかなり素直に使えます。
3.9.6 Dijkstra と Bellman-Ford と A* の違い
この 3 つは全部「経路」を扱いますが、得意な状況が違います。
| アルゴリズム | 何が強いか | 弱いところ | 典型例 |
|---|---|---|---|
| Dijkstra | 負辺のない最短経路を効率よく解ける | 負辺があると壊れる | 地図、通信コスト、配送料 |
| Bellman-Ford | 負辺や負閉路検出まで扱える | 遅い | 差額、異常コスト、理論寄り検査 |
| A* | ゴールが決まっている探索を速くしやすい | ヒューリスティクス依存 | ゲーム AI、経路検索、カーナビ |
Dijkstra がうまくいく理由
Dijkstra が成立するのは、辺重みが負でないからです。いったん「この頂点が最も近い」と確定したら、あとからもっと短い経路がひっくり返って現れません。
負辺があると、この前提が壊れます。あとから「遠回りしたのに負の辺で一気に安くなる」ことが起きるからです。
A* が速くなりやすい理由
A* は、
で候補を選びます。
- : これまでに実際にかかった距離
- : ゴールまでの見込み距離
です。
つまり A* は、「今までどれだけ良いか」だけでなく、「この先どれだけ有望か」も見て進みます。地図で言えば、目的地の方角が分かっているなら、そちらを優先した方が全探索より無駄が減るわけです。
3.9.7 最小全域木は「最短経路」と何が違うか
最小全域木は、しばしば最短経路と混同されますが、目的が違います。
- 最短経路: ある点からある点へ最も安く行きたい
- 最小全域木: 全頂点をつなぎたいが、全体の合計コストを最小にしたい
たとえば拠点 A から各拠点への最短移動時間を知りたいなら最短経路です。一方で、町どうしを全部ケーブルで結びたいが、敷設費用の合計を最小にしたいなら最小全域木です。
Kruskal の直感
Kruskal は、軽い辺から順に「採っても閉路にならないなら採る」を繰り返します。ここで効くのが Union-Find です。2 頂点がすでに同じ連結成分に属しているなら、その辺を足すと輪ができると分かります。
Prim の直感
Prim は、いま育てている木から外へ出る辺のうち、一番安いものを少しずつ足します。Dijkstra と見た目が少し似ていますが、最短距離を確定しているのではなく、「木を安く伸ばす」ことが目的です。
同じグラフでも答えは変わる
ここはかなり大事です。同じグラフを見ても、何を聞くかで答えは変わります。
次の無向重み付きグラフを考えます。
この図に対して、
- 「A から D へ行く最短手数は?」
- 「A から D へ行く最短距離は?」
- 「A, B, C, D を全部つなぐ最小総コストは?」
は、別の問いです。
BFS で見ると何が起きるか
BFS は重みを見ません。見るのは「何本の辺を通るか」だけです。
A から D へ行く経路候補はたとえば、
- A -> B -> D
- A -> C -> D
- A -> B -> C -> D
があります。
このうち、辺の本数だけで見ると
- A -> B -> D は 2 手
- A -> C -> D も 2 手
- A -> B -> C -> D は 3 手
です。
なので BFS の答えは「2 手で到達できる」です。ここでは重み 1, 4, 2, 5, 1 の差は無視されます。
Dijkstra で見ると何が起きるか
Dijkstra は辺の重みを足し合わせた総距離を見ます。
同じ 3 経路でも、コストは
- A -> B -> D :
- A -> C -> D :
- A -> B -> C -> D :
です。
つまり Dijkstra の答えは、A -> B -> C -> D が最短距離 です。BFS では 3 手なので不利に見えた経路が、重みを考えると最良になります。
ここが、
- BFS: 最短手数
- Dijkstra: 最短距離
の違いです。
最小全域木で見ると何が起きるか
今度は「A から D に行きたい」ではなく、「4 頂点全部をつなぐ総コストを最小化したい」と考えます。
このとき採りたくなる軽い辺は、
- A - B : 1
- C - D : 1
- B - C : 2
です。この 3 本で A, B, C, D が全部つながり、総コストは
になります。
これは最小全域木の 1 つです。
重要なのは、この答えが A から D の最短経路そのもの ではないことです。最小全域木は「全体を安くつなぐ」ための構造であって、「特定の 2 点の移動を最短にする」ための構造ではありません。
3 つを並べるとどう違うか
| 問い | 見ているもの | このグラフでの答え |
|---|---|---|
| BFS | 通る辺の本数 | A から D は 2 手 |
| Dijkstra | 辺重みの合計 | A -> B -> C -> D でコスト 4 |
| 最小全域木 | グラフ全体の総接続コスト | 辺 AB, BC, CD で総コスト 4 |
つまり、
- BFS は「近さ」の定義が手数
- Dijkstra は「近さ」の定義が距離
- 最小全域木はそもそも「経路」ではなく「全体構造」
です。
ここを混同しないだけで、グラフ問題の見通しはかなり良くなります。
3.9.8 強連結成分とトポロジカルソート
有向グラフでは、「行ける」と「戻ってこられる」が別問題になります。ここで強連結成分が効きます。
- 強連結成分(SCC): どの頂点からどの頂点へも互いに到達できる最大のまとまり
たとえばサービス A -> B -> C -> A の依存があるなら、この 3 つは 1 つの強連結成分です。こういう塊を縮約すると、グラフ全体の大まかな構造が見やすくなります。
一方、依存関係を順序づけたいときは トポロジカルソート が出ます。これは DAG(有向非巡回グラフ)に対して、
- 依存先が先
- 依存元が後
になるように並べる操作です。
典型例は、
- ビルド順序
- 授業の履修順序
- ジョブの依存解決
です。ここでサイクルが見つかったら、「依存が循環していて順番を付けられない」という意味になります。
有向グラフで何が見えるか
ここも、実際に小さな図で見るとかなり分かりやすくなります。次の有向グラフを考えます。
このグラフでは、
A -> B -> C -> Aで 1 つの循環がある- そこから
D -> Eへ流れていく
という構造になっています。
DFS で見ると何が分かるか
たとえば A から DFS を始めると、
- A へ行く
- B へ潜る
- C へ潜る
- C から A へ戻れることに気づく
- さらに D, E へ進む
というように、「行けるところまで潜る」流れになります。
DFS がここで強いのは、
- 到達できる頂点を全部集められる
- 後退辺や再訪を見てサイクルを見つけやすい
- 帰りがけ順を使って順序づけの土台を作れる
ことです。
つまり DFS は、「距離」を測るというより、「構造」をあぶり出す探索です。
強連結成分で見ると何が分かるか
この図では、
A, B, Cは互いに行って戻れるDとEは戻ってこられない
ので、強連結成分は
{A, B, C}{D}{E}
に分かれます。
このように SCC ごとに縮約すると、複雑な有向グラフも「循環する塊どうしのつながり」として見やすくなります。
実務では、
- マイクロサービス依存
- モジュール依存
- ジョブ依存
- コンパイラの制御フロー解析
のような場面で、「循環して切り離せないまとまり」を見つけるのに効きます。
トポロジカルソートはなぜできないのか
このグラフ全体には A -> B -> C -> A の循環があるので、トポロジカルソートはできません。
なぜなら、
- A は B より先に置きたい
- B は C より先に置きたい
- C は A より先に置きたい
が同時に要求されて、矛盾するからです。
ここで大事なのは、トポロジカルソートができないこと自体が重要な情報 だという点です。依存解決やビルドでこれが起きたら、「順番の問題」ではなく「設計に循環依存がある」という警告になります。
DAG にすると何が変わるか
もし循環を消して、たとえば次のような DAG にするとします。
このときは、Parser -> AST -> Type Check -> Codegen のように自然なトポロジカル順序を作れます。
これは、
- 依存先を先に処理する
- 下流は上流の結果に依存する
という世界で非常に便利です。
どう使い分けるか
この 3 つを並べると、役割は次のように違います。
| 観点 | 何を知りたいか | この図で見えること |
|---|---|---|
| DFS | どこまで行けるか、どんな構造か | A から B, C, D, E へ到達できる |
| SCC | 相互到達できる塊はどこか | {A, B, C} が 1 つの塊 |
| トポロジカルソート | 依存順に並べられるか | 循環があるので全体では不可 |
つまり、
- DFS は探索の土台
- SCC は循環する塊の抽出
- トポロジカルソートは循環のない依存順序づけ
です。
3.9.9 アルゴリズムの正しさをどう考えるか
アルゴリズムは、速いだけでは足りません。本当に正しい答えを返すか を考える必要があります。
そのときによく使う観点が次です。
- 不変条件(invariant): ループの途中でも常に成り立つ性質
- 帰納法: 小さい問題で正しければ、大きい問題でも正しいと示す
- 反例: 1つでも間違う入力があれば、そのアルゴリズムは一般には正しくない
たとえば二分探索では、「探している値があるなら、常に現在の探索区間の中にある」という不変条件が大事です。これを壊すと、コードは速そうでも正しく動きません。
3.9.10 ならし計算量という見方
1 回だけ高いコストがかかっても、長い目で見ると平均的には安いことがあります。これが ならし計算量 です。
典型例は動的配列です。配列がいっぱいになったときだけ大きな再配置が起きますが、毎回それが起きるわけではないので、append はならして見ると高速です。
この見方は、
- 動的配列
- ハッシュテーブルの再ハッシュ
- ガベージコレクション
のような「たまに重い処理」を理解するときに効きます。
3.10 よくある誤解
3.11 ミニ比較表
| アルゴリズム | 前提 | 計算量 | コメント |
|---|---|---|---|
| 線形探索 | なし | 単純で強い | |
| 二分探索 | ソート済み | 前提が必要 | |
| バブルソート | なし | 教材向き | |
| マージソート | なし | 安定で速い |
3.12 例題
【図7】計算量を求める手順:
例題1: 長さ n の配列を先頭から1回ずつ見る処理の計算量を答えよ。
解説: 要素数に比例して処理回数が増えるので です。
例題2: 二重ループで n × n 回処理するコードの計算量を答えよ。
解説: 回の処理になるので です。
例題3: 二分探索が速い理由を一文で述べよ。
解説: 毎回探索範囲を半分に減らせるからです。
例題4: 辺の重みがすべて同じ迷路で、スタートからゴールまでの最短手数を求めたい。まず考えるべきアルゴリズムは何か。
解説: BFS です。重みが一律なら、「何本の辺を通るか」がそのまま手数になるので、距離 1、距離 2、距離 3… と層ごとに広がる BFS が自然です。
例題5: ビルド依存関係を順に並べたいが、もし循環依存があれば検出したい。どの考え方が向いているか。
解説: トポロジカルソートです。依存グラフが DAG なら順序づけでき、循環があるなら「順番を付けられない」という形で問題が見つかります。
3.13 練習問題
- 配列末尾への push が平均 と言いやすいのはなぜか。
n個の要素を1回ずつ比較する処理の計算量を答えよ。- ソート済みという前提を必要とする探索法は何か。
- と は、入力が大きいときどちらが伸びにくいか。
- 辺の重みがすべて同じ迷路で、最短手数を求めたい。まず考えるべきアルゴリズムは何か。
- 道路ごとに距離が違う地図で、負の重みはない。ある街から別の街への最短距離を求めたい。まず考えるべきアルゴリズムは何か。
- サービス依存関係に循環があるかを調べ、相互依存の塊を見つけたい。どの考え方が向いているか。
- タスクの依存順序を並べたいが、順序付けできない場合は循環依存として検出したい。どの考え方が向いているか。
- 拠点どうしを全部ケーブルでつなぎたいが、総工事費は最小にしたい。最短経路ではなく何の問題として見るべきか。
3.14 練習問題の答え
- 通常は末尾へすぐ追加できるから
- 二分探索
- BFS
- Dijkstra
- 強連結成分(SCC)。DFS を土台に Tarjan / Kosaraju などで見る
- トポロジカルソート。循環があれば順序付けできない
- 最小全域木(Kruskal / Prim)
第4章 データ構造
この章が実務で役立つ場面
- キャッシュ、辞書、キュー、ジョブ管理の設計
- メモリ使用量と処理速度のトレードオフ判断
- ライブラリ選定時に内部構造を想像する力
4.1 データ構造とは
データ構造は、データを効率よく扱うための整理方法です。
アルゴリズムが「どう処理するか」なら、データ構造は「どう置いておくか」に当たります。
4.2 基本的なデータ構造
配列
- 連続した領域に並ぶ
- 添字アクセスが速い
- 中間への挿入削除は重い
連結リスト
- ノード同士をポインタでつなぐ
- 挿入削除はしやすい
- ランダムアクセスは遅い
【図8-2】配列と連結リストの違い:
スタック
- Last In, First Out
- 関数呼び出し、式評価、Undo など
キュー
- First In, First Out
- タスク待ち行列、バッファ、BFS など
木
- 階層構造を表しやすい
- ファイルシステム、構文木、探索木
ハッシュテーブル
- キーから値を高速に探す
- 平均的に高速だが、ハッシュ衝突の考慮が必要
ヒープ(優先度付きキュー)
- 最大値/最小値を常に で取り出せる
- ヒープソート、Dijkstra、A*、タスクスケジューラで使われる
- 実装はしばしば配列の上の二分木(0-indexed で親は
(i-1)/2、子は2i+1/2i+2)
Trie(トライ木、プレフィックス木)
- 文字列検索に強い
- 辞書、オートコンプリート、IP ルーティング(Patricia trie)
- 長さ
mの文字列の検索が
Union-Find(素集合データ構造)
- 「同じグループか?」をほぼ で判定
- Kruskal の最小全域木、ネットワーク接続性、画像セグメンテーション
- 経路圧縮 + ランクで (実質定数)
4.3 データ構造の選び方
【図8】データ構造の選び方フローチャート:
4.4 配列と連結リストの直感
配列は、本棚の本に番号が振ってあって、すぐ取り出せるイメージです。連結リストは、次の人の肩を持って列を作っているようなもので、途中へ挿し込みやすい代わりに、先頭から順にたどる必要があります。
4.5 木とグラフ
木
- 親子関係がある
- サイクルがない
- ルートからたどる
代表的な木:
- 二分探索木(BST):左の子 < 親 < 右の子。平均
- 平衡二分探索木:AVL、Red-Black。最悪も 保証
- B 木 / B+ 木:ディスク向け(ノードに多数のキー)。DBMS、ファイルシステム
- ヒープ:親が子以上/以下(優先度キュー)
- セグメント木:区間クエリ
- Trie:プレフィックス木
4.5.1 それぞれの木をもう少し丁寧に見る
ここは名前が多くて一度に飲み込みにくいところです。大事なのは、「全部を覚える」より 何を速くしたくて生まれた木か をつかむことです。
二分探索木(BST)
BST は、各ノードについて
- 左部分木の値は自分より小さい
- 右部分木の値は自分より大きい
という規則を持つ木です。
この規則のおかげで、探すたびに
- 左に行くか
- 右に行くか
を決められるので、候補をかなり減らせます。
ただし BST は、挿入順が偏ると片側に長く伸びてしまい、ただの連結リストに近い形になることがあります。そうなると速さのうまみが薄れます。
平衡二分探索木(AVL, Red-Black)
そこで「偏りすぎないように木の形を保つ」仕組みを入れたのが平衡二分探索木です。
- AVL 木: 高さ差をかなり厳密に保つ
- Red-Black 木: 少しゆるく平衡を保つが、更新コストとのバランスがよい
どちらも、
- 探索
- 挿入
- 削除
を最悪でも に保ちやすいのが強みです。
直感的には、BST が「自然に伸びる木」だとすると、平衡木は「形が崩れすぎたら剪定して整える木」です。
B 木 / B+ 木
B 木系は、メモリ上というより ディスクや SSD のような外部記憶 と相性がよい木です。
二分木のように 1 ノード 1 キーではなく、
- 1 ノードにたくさんのキー
- 1 ノードにたくさんの子ポインタ
を持たせます。
こうすると、1 回のディスク読み出しで多くの候補を一気に絞れます。DB やファイルシステムでよく使われるのは、この「I/O 回数を減らしたい」という事情が大きいです。
特に B+ 木では、実データは葉に集め、内部ノードは索引に近い役割を持たせることが多く、範囲検索や順序走査とも相性がよいです。
ヒープ
ヒープは「探索木」というより、最小値や最大値をすぐ取りたい木 です。
たとえば最小ヒープなら、
- 親 <= 子
という規則だけを守ります。
BST のように「左は小さい、右は大きい」まで細かくは決めません。その代わり、
- いちばん小さい値は根にある
ことが保証されます。
なのでヒープは、
- 優先度付きキュー
- スケジューラ
- Dijkstra
のように「次に一番よい候補をすぐ出したい」場面に向いています。
セグメント木
セグメント木は、区間に関する質問に強い木 です。
たとえば配列に対して、
- 区間和
- 区間最小値
- 区間最大値
を何度も求めたいときに強いです。
素朴に毎回区間を全部なめると遅いですが、区間を半分ずつまとめて木に持たせておくと、問い合わせと更新の両方を で行いやすくなります。
競技プログラミングでよく見る一方、実務では監視メトリクスや区間集計の考え方に通じます。
Trie
Trie は、数値より 文字列や接頭辞 を扱うのが得意な木です。
たとえば cat, car, care のような単語があるとき、先頭の ca を共有して持てます。
そのため、
- 辞書検索
- オートコンプリート
- 接頭辞検索
- IP ルーティング
といった「先頭から見ていく」処理に向いています。
BST やハッシュテーブルが「値全体をキーとして見る」のに対し、Trie は「文字列の途中経過そのものを道として持つ」と考えるとイメージしやすいです。
4.5.2 どう使い分けるか
ざっくり言うと、次のように見ると整理しやすいです。
| 構造 | 何が得意か | 向く場面 |
|---|---|---|
| BST / 平衡木 | 順序を保った探索 | 範囲検索、順序つき集合 |
| B 木 / B+ 木 | 外部記憶上の索引 | DB、ファイルシステム |
| ヒープ | 最小 / 最大の取り出し | スケジューラ、優先度付きキュー |
| セグメント木 | 区間問い合わせ | 区間和、区間最小値 |
| Trie | 接頭辞検索 | 辞書、補完、ルーティング |
グラフ
- ノードと辺の一般形
- ネットワーク、依存関係、経路問題
表現方法:
- 隣接行列: メモリ、辺の有無の判定
- 隣接リスト: メモリ、疎なグラフで有利
- エッジリスト:最もシンプル、Kruskal に向く
4.5.3 グラフの表現をどう選ぶか
同じグラフでも、どう表すかで扱いやすさが変わります。
隣接行列
頂点どうしのつながりを表にしたものです。
- 強いところ: 「i と j はつながっているか」をすぐ見られる
- 弱いところ: 辺が少なくても表全体を持つので重い
密なグラフでは自然ですが、疎なグラフだと無駄が多くなります。
隣接リスト
各頂点ごとに、「どこへつながっているか」の一覧を持ちます。
- 強いところ: 実際にある辺だけ持てばよい
- 弱いところ: 「この2頂点が直結か」を一発で見るには工夫がいる
BFS や DFS が で説明されるとき、たいてい頭の中には隣接リスト表現があります。
エッジリスト
辺をただ並べたものです。
- 強いところ: 実装が単純
- 弱いところ: 特定頂点の近傍をたどるには不向き
Kruskal のように「辺を軽い順に並べて見たい」アルゴリズムとは相性がよいです。
4.5.4 木はなぜ速いのか
木がよく出てくる理由は、「全部を順番に見なくても候補をどんどん絞れる」からです。
たとえば二分探索木なら、
- 左には小さいもの
- 右には大きいもの
という規則があるので、毎回かなりの候補を捨てられます。
これは本棚を全部順番に見るのではなく、
- どのあたりにありそうかを見る
- 左か右かを決める
- 範囲をさらに絞る
という探し方に似ています。
4.5.5 ハッシュテーブルの平均 の意味
ハッシュテーブルは「ほぼ一瞬で見つかる」と説明されがちですが、ここにも前提があります。
- ハッシュ関数がうまく散らす
- 衝突が極端に偏らない
- 適切にリサイズされる
という条件がそろって、はじめて平均的に速くなります。
つまり は「どんな場合でも絶対一定時間」という意味ではありません。平均的な条件のもとで強い、という理解が現実に近いです。
4.6 ミニ比較表
| 構造 | 強い操作 | 弱い操作 | 典型用途 |
|---|---|---|---|
| 配列 | ランダムアクセス | 中間挿入削除 | テーブル、固定長データ |
| 連結リスト | 挿入削除 | 添字アクセス | キュー内部実装など |
| スタック | push/pop | 中間参照 | 再帰、Undo |
| キュー | enqueue/dequeue | 中間参照 | ジョブ管理 |
| 木 | 階層管理 | 単純添字 | 構文木、ディレクトリ |
| ハッシュテーブル | キー検索 | 順序性 | 辞書、キャッシュ |
4.7 よくある誤解
4.8 例題
【図9】データ構造選定の思考プロセス:
例題1: キーから値をできるだけ高速に引きたい。何が候補になるか。
解説: ハッシュテーブルが有力です。
例題2: 関数呼び出し履歴のように、最後に入れたものから取り出す構造は何か。
解説: スタックです。
4.9 練習問題
- FIFO の性質を持つ構造は何か。
- 添字アクセスに強いのは配列と連結リストのどちらか。
- 階層構造を扱う代表例を1つ挙げよ。
- 順序より検索速度を重視するとき有力なのは何か。
4.10 練習問題の答え
- キュー
- 配列
- 例: ディレクトリ、構文木
- ハッシュテーブル
まとめ
アルゴリズムとデータ構造は、どう解くかとどう置くかを一緒に考えると理解しやすくなります。計算量、代表アルゴリズム、データ構造の性質を往復しながら、問題に合う選び方を身につけるのが大切です。