データベース
目次
- 概要
- なぜDBが必要か
- データベース歴史と進化
- リレーショナルDBの基本
- 3層スキーマとデータ独立性
- リレーショナルモデル
- 関数従属と正規化
- SQL完全ガイド
- インデックス詳細
- クエリ実行計画と最適化
- トランザクションとACID
- MVCCと分離レベル
- ロックと同時実行制御
- WALと リカバリ
- NoSQLとNewSQL
- レプリケーション
- シャーディングと分散
- OLTPとOLAP
- 新時代データベース
- 運用と実務
- 実務ミニケース
- 制約とアプリケーションロジック
- スキーマ変更と運用
- クエリ改善の流れ
- 設計原則として見るDB
- 比較で理解する
- 判断の指針
- FAQ
- ミニ比較表
- 次に読むなら
- 補足
- まとめ
- 参考文献
概要
SQL・索引・トランザクション・分散まで
データベースは単なる保存箱ではありません。整合性、検索、同時実行、拡張性を支える基盤です。
この章で重視すること
なぜDBが必要か
単なるファイルだけでは、
- 検索しづらい
- 同時更新が危ない
- 一貫性を保ちにくい
という問題があります。
ファイルが悪いわけではありません。問題は、複数人・複数プロセス・長期間運用という条件が入ると、
- どこに何があるか
- 更新がぶつからないか
- 壊れていないか
- すばやく取れるか
を毎回アプリ側で背負うのが重くなることです。DBは単なる保存箱ではなく、保存・検索・整合性・並行性の責任を引き受ける仕組み です。
データベース歴史と進化
データベースは70年弱の歴史の中で、大きなパラダイム転換を何度も経ています。
階層型データベース(1960年代)
IBMのIMS(Information Management System)がパイオニア。
- 特徴:木構造でデータ関係を表現
- 親が必ずあり、子は親を通じてのみアクセス
- 利点:シンプル、高速(ポインタで直接参照)
- 課題:一度スキーマが決まると変更が困難。親子関係が複雑だと困難
使用例:
コード例は、そのまま写すためだけのものではありません。直前の本文で「何を確かめる例か」を押さえ、直後の説明で「どの性質が見えるか」を確認してください。実務では、ここに入力の境界、失敗時の挙動、依存する実行環境を足して読むと判断しやすくなります。
ネットワーク型データベース(1970年代)
CODASYL(Conference on Data Systems Languages)が標準化。dBASEなどで採用。
- 特徴:多対多の関係を表現可能
- ポインタを用いた複雑なネットワーク構造
- 利点:階層型より柔軟
- 課題:ナビゲーション的アクセス(「次へ」「前へ」)が必要。データ構造の変更は運用負荷
リレーショナルモデルの革新(1970年代後期 - 現在)
Edgar Coddが1970年に発表した「A Relational Model of Data for Large Shared Data Banks」が転換点。
-
革新点:構造とアクセス方法の分離
- ユーザーは「どの構造か」だけ指定、DBが「どう取るか」を決める(SQLの宣言的性質)
- ポインタではなく値(キー)で関係を表現
-
正規化の概念:更新異常を減らし、スキーマの柔軟性を高める
-
最適化の余地:同じSQLでも複数の実行計画の可能性があり、最適化器が選択
主要なRDBMSの系譜:
| 時期 | 製品 | 特徴 |
|---|---|---|
| 1979 | Oracle (Relational Software社) | SQL最初の商用実装。トランザクション、ロック等を実装 |
| 1986 | Ingres | PostgreSQLの前身。高度な最適化器 |
| 1989 | PostgreSQL (元Postgres) | 拡張性重視。オブジェクト指向拡張。信頼性が高い |
| 1995 | MySQL | シンプル、高速読み取り重視。Web時代の標準 |
| 2000年代初期 | SQL Server(Windows)、DB2(IBM) | エンタープライズ向け機能豊富 |
オブジェクト指向DB(1990年代)
O2、ObjectStoreなどが登場。
- 動機:オブジェクト指向プログラミングとのインピーダンスミスマッチ(ORM)を解消したい
- 特徴:オブジェクトをそのまま永続化
- 結果:SQLの使いやすさとRDBMSの最適化に勝てず。ニッチ化
NoSQLと「大規模分散」へのシフト(2000年代後期 - 2010年代)
Web規模(Google、Facebook、Amazon)のデータと並行性を扱う要求から。
- Memcached(2003):キャッシュの高速化
- BigTable(Google、2006):列指向、分散、スケーラビリティ
- MongoDB(2009):ドキュメント指向、柔軟なスキーマ
- Cassandra(Facebook):マルチレプリカ、結果整合性
- Redis(2009):メモリ内キー値ストア、複雑なデータ構造
- DynamoDB(Amazon、2012):フルマネージド、リージョナル複製
NoSQLの多様化:
NewSQLと分散RDBMS(2010年代 - 現在)
課題:NoSQLの柔軟性は得たが、SQLとACIDを捨てた。
NewSQLの登場:SQL + ACID + 分散スケーラビリティ
主要プロダクト:
| 製品 | 特徴 | 適用 |
|---|---|---|
| Google Spanner | グローバル分散、外部整合性、 Paxosベース同期複製 | グローバルスケール企業 |
| CockroachDB | Spannerの思想をオープンソース化。SERIALIZABLE分散トランザクション | フェイルオーバー、スケーラビリティ |
| TiDB | MySQL互換SQL、 Raftベース複製、行指向ストレージ | MySQLからの移行 |
| YugabyteDB | ACID分散トランザクション、PostgreSQL互換 | 高可用性+SQL |
Lakehouseと分析基盤(2020年代)
課題:OLTPとOLAPの境界が不明確に。
- Snowflake(2012):クラウドネイティブ、SQLを分析に
- Databricks(2013):Sparkベース、Delta Lake(ACID OLAP)
- Iceberg(Apache):テーブル形式。スナップショット、タイムトラベル
- Hudi(Uber):増分処理、ACID保証
- DuckDB(2023注目):エッジ / 分析用SQLウェアハウス
ベクトルデータベース(2023年〜)
生成AIとEmbeddingの普及で新ジャンル。
- pgvector(PostgreSQL):拡張機能としてCosine / L2距離検索
- Pinecone:マネージドVector DB、1億次元対応
- Weaviate:オープンソース、GraphQL API
- Milvus(LF AI):オープンソース、大規模ANN(Approximate Nearest Neighbor)
- Qdrant:Rustベース、高パフォーマンス
使用例:生成AIのプロンプトに「 RAG(Retrieval Augmented Generation)」で関連ドキュメントを検索。
リレーショナルDBの基本
関係をDB自体に守らせられるのが大きな強みです。
3層スキーマとデータ独立性
DBを「表の集まり」とだけ見ると、設計や運用の視点が抜け落ちやすくなります。実際のDBMSでは、利用者に見せる形、論理構造、物理配置を分けて考えます。
- 外部スキーマ: 利用者やアプリケーションから見える形
- 概念スキーマ: DB全体の論理構造
- 内部スキーマ: 物理配置、インデックス、圧縮などの実装
この分離があるおかげで、アプリから見える形を保ったまま、内部ではインデックス追加や格納方法の変更を進めやすくなります。
データ独立性
物理的データ独立性は、物理構造を変えても上位の論理構造に影響を出しにくい性質です。
- インデックス追加
- ストレージ変更
- 圧縮やパーティション方式の見直し
論理的データ独立性は、概念スキーマの変更が利用者側に波及しにくい性質です。
- 列追加
- ビューによる互換維持
- テーブル分割時の段階移行
実務では完全な独立性は難しいですが、「どの変更をどの層に閉じ込めるか」を意識するだけで、DB改修はかなり進めやすくなります。
なぜ「関係」をDBに持たせるのか
業務データでは、1件ずつ正しいだけでは足りません。
- 注文は存在する顧客に結びつくべき
- 明細は存在する商品を参照すべき
- 同じメールアドレスは重複禁止かもしれない
こうした約束をアプリコードだけで守ると、抜け漏れや競合で破られやすくなります。外部キーや一意制約は、データのルールをDBそのものへ埋め込む 手段です。
リレーショナルモデルの形式
Codd以来、リレーショナルモデルは数学的に形式化されています。
関係(Relation):テーブルと同義。
R = {(t1, t2, ..., tn) | t1 ∈ D1, t2 ∈ D2, ..., tn ∈ Dn}
ここでD1, D2, … はドメイン(値の集合)。
アトリビュート(属性):列。
タプル(タプル):行。
例:顧客関係R_customers = {customer_id, name, email, country}
リレーショナルモデル
関係、属性、タプル
テーブルcustomers:
| customer_id | name | country | |
|---|---|---|---|
| 1 | Alice | alice@example.com | JP |
| 2 | Bob | bob@example.com | US |
- 関係 = テーブル全体
- アトリビュート = {customer_id, name, email, country}(列の集合)
- タプル = (1, Alice, alice@example.com, JP)(各行)
- ドメイン = customer_id ∈ {正の整数}、name ∈ {可変長文字列}
スーパーキーと候補キー
スーパーキー(Super Key):タプルを一意に識別できる属性集合。
- {customer_id}
- {customer_id, name}
- {email}(メールアドレスが一意なら)
候補キー(Candidate Key):最小限のスーパーキー。冗長性がない。
- {customer_id}
- {email}
主キー(Primary Key):候補キーのうち、DBAが選んだもの。
CREATE TABLE customers (
customer_id INTEGER PRIMARY KEY,
email VARCHAR(255) UNIQUE,
name VARCHAR(100)
);
外部キーと参照整合性
外部キー(Foreign Key):別のテーブルの主キーを参照。
CREATE TABLE orders (
order_id INTEGER PRIMARY KEY,
customer_id INTEGER REFERENCES customers(customer_id),
order_date TIMESTAMP
);
参照整合性:孤立したデータが生まれないこと。
- 存在しないcustomer_idへの注文は禁止
- 顧客削除時に注文も自動削除(CASCADE)、または削除禁止(RESTRICT)
関数従属と正規化
関数従属(Functional Dependency)
定義:属性Xが決まると属性Yが一意に決まる場合、「X → Y」と書く。
例:
order_id → order_date
customer_id → customer_name
完全関数従属:Yが複合キーX全体に依存し、Xの部分集合には依存しない。
推移的関数従属:X → Y → Zのとき、X → Z(推移)。
正規化は関数従属の観点から、余分な従属を排除する 過程です。
正規化
正規化は、重複を減らし、更新異常を防ぐ考え方です。
たとえば顧客住所を注文ごとに毎回書くと、変更時に修正漏れが起きやすくなります。そこで表を分け、キーでつなぎます。
正規化はしばしば「理論の作法」と思われますが、本質は更新異常を減らすことです。
第1正規形(1NF)
定義:すべての属性が原子値(分割できない値)を持つ。
ダメな例(非正規):
| order_id | product_names |
|---|---|
| 1 | Apple, Orange |
| 2 | Banana |
productsが複数値。
改善後(1NF):
| order_id | product_name |
|---|---|
| 1 | Apple |
| 1 | Orange |
| 2 | Banana |
第2正規形(2NF)
定義:1NFであり、かつ主キーでない属性が主キー全体に完全関数従属する。
ダメな例(1NFだが2NFではない):
| order_id | product_id | product_name | price |
|---|---|---|---|
| 1 | 10 | Apple | 100 |
| 1 | 20 | Orange | 80 |
主キー = {order_id, product_id}。
しかしproduct_name, priceはproduct_idだけで決まる(主キー全体不要)。
改善後(2NF):
テーブルorder_items:
| order_id | product_id |
|---|---|
| 1 | 10 |
| 1 | 20 |
テーブルproducts:
| product_id | name | price |
|---|---|---|
| 10 | Apple | 100 |
| 20 | Orange | 80 |
第3正規形(3NF)とBCNF
第3正規形(3NF):2NFであり、かつ非主キー属性が主キーに対して推移的関数従属を持たない。
例:カテゴリを持つ商品
| product_id | category | category_manager |
|---|---|---|
| 10 | Fruits | Alice |
| 20 | Vegetables | Bob |
product_id → category → category_manager(推移的)。
改善(3NF):
テーブルproducts:
| product_id | category |
|---|---|
| 10 | Fruits |
| 20 | Vegetables |
テーブルcategories:
| category | manager |
|---|---|
| Fruits | Alice |
| Vegetables | Bob |
Boyce-Codd正規形(BCNF):すべての決定要因が候補キーである。
3NFでも異常が残る場合があり、BCNFがより厳密。ただし実務では3NFで十分なことが多い。
ただし非正規化が悪とは限らない
分析系や高負荷読み取り系では、JOINを減らすためにあえて重複を持つこともあります。大事なのは「理論どおりか」ではなく、どのコストを引き受ける設計か を自覚することです。
SQL完全ガイド
DDL(Data Definition Language)
CREATE TABLE:テーブル定義。
CREATE TABLE orders (
order_id BIGINT PRIMARY KEY GENERATED ALWAYS AS IDENTITY,
customer_id INTEGER NOT NULL REFERENCES customers(customer_id),
order_date TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
total_amount NUMERIC(10, 2),
status VARCHAR(50) DEFAULT 'pending',
CONSTRAINT check_amount CHECK (total_amount > 0)
);
ALTER TABLE:既存テーブルの変更。
-- 列追加
ALTER TABLE orders ADD COLUMN notes TEXT;
-- 制約追加
ALTER TABLE orders ADD CONSTRAINT unique_order_code UNIQUE(order_id);
-- インデックス変更は実質的にはDROP + CREATE
DROP INDEX idx_orders_customer_id;
CREATE INDEX idx_orders_customer_id ON orders(customer_id);
CREATE INDEX:索引作成。
-- 単一列
CREATE INDEX idx_customer_id ON orders(customer_id);
-- 複合索引
CREATE INDEX idx_customer_date ON orders(customer_id, order_date DESC);
-- 条件付き(Partial Index in PostgreSQL)
CREATE INDEX idx_pending_orders ON orders(order_date)
WHERE status = 'pending';
-- カバリング索引(MySQL, SQL Server, PostgreSQL 11+)
CREATE INDEX idx_customer_amount ON orders(customer_id)
INCLUDE (total_amount); -- PostgreSQLでは簡単だが、MySQLでは工夫が必要
DML(Data Manipulation Language)
SELECT:基本的な検索。
SELECT customer_id, COUNT(*) as order_count, SUM(total_amount) as total
FROM orders
WHERE order_date >= '2024-01-01'
GROUP BY customer_id
HAVING COUNT(*) > 5
ORDER BY total DESC
LIMIT 10;
INSERT:データ挿入。
-- 値を明示的に指定
INSERT INTO orders (customer_id, order_date, total_amount, status)
VALUES (1, NOW(), 150.00, 'pending');
-- SELECTで複数行
INSERT INTO orders_archive
SELECT * FROM orders WHERE order_date < '2020-01-01';
-- PostgreSQLのRETURNINGで挿入後の主キーを取得
INSERT INTO orders (customer_id, total_amount)
VALUES (1, 100.00)
RETURNING order_id;
UPDATE:データ更新。
-- 条件付き更新
UPDATE orders
SET status = 'completed', updated_at = NOW()
WHERE order_id = 123;
-- 複数テーブルのJOINで条件付け(MySQL)
UPDATE orders o
JOIN customers c ON o.customer_id = c.customer_id
SET o.discount = o.total_amount * 0.1
WHERE c.country = 'JP';
-- PostgreSQLでのWHEREで関連テーブル参照
UPDATE orders o
SET status = 'completed'
FROM customers c
WHERE o.customer_id = c.customer_id
AND c.vip = true
AND o.total_amount > 1000;
DELETE:データ削除。
-- 条件付き削除
DELETE FROM orders
WHERE order_id = 123;
-- 複合条件
DELETE FROM orders
WHERE status = 'cancelled'
AND order_date < CURRENT_DATE - INTERVAL '1 year';
JOINの詳細
INNER JOIN:両テーブルに存在する行のみ。
SELECT o.order_id, c.name, o.total_amount
FROM orders o
INNER JOIN customers c ON o.customer_id = c.customer_id;
LEFT JOIN:左テーブルのすべての行。右が存在しないとNULL。
SELECT c.name, COUNT(o.order_id) as order_count
FROM customers c
LEFT JOIN orders o ON c.customer_id = o.customer_id
GROUP BY c.customer_id, c.name;
FULL OUTER JOIN:両テーブルのすべての行。(MySQLではUNIONの工夫が必要)
SELECT c.name, o.order_id
FROM customers c
FULL OUTER JOIN orders o ON c.customer_id = o.customer_id;
クロス結合(CROSS JOIN):デカルト積。
SELECT c.name, p.product_name
FROM customers c
CROSS JOIN products p;
-- 結果:顧客数 × 商品数の行
ウィンドウ関数
行の関連性を保ったまま、集計や順位をつけられる機能。
ROW_NUMBER:順位(重複なし)。
SELECT
order_id,
total_amount,
ROW_NUMBER() OVER (ORDER BY total_amount DESC) as rank
FROM orders;
RANK / DENSE_RANK:順位(重複あり)。
SELECT
order_id,
total_amount,
RANK() OVER (ORDER BY total_amount DESC) as rank,
DENSE_RANK() OVER (ORDER BY total_amount DESC) as dense_rank
FROM orders;
-- 例:
-- order_id=1, amount=1000, RANK=1, DENSE_RANK=1
-- order_id=2, amount=1000, RANK=1, DENSE_RANK=1
-- order_id=3, amount=900, RANK=3, DENSE_RANK=2
-- order_id=4, amount=800, RANK=4, DENSE_RANK=3
LAG / LEAD:前後の行の値を参照。
SELECT
order_date,
total_amount,
LAG(total_amount) OVER (ORDER BY order_date) as prev_amount,
LEAD(total_amount) OVER (ORDER BY order_date) as next_amount,
total_amount - LAG(total_amount) OVER (ORDER BY order_date) as change
FROM orders;
PARTITION BYで分析対象をグループ化:
SELECT
customer_id,
order_id,
total_amount,
SUM(total_amount) OVER (PARTITION BY customer_id) as customer_total,
ROW_NUMBER() OVER (PARTITION BY customer_id ORDER BY order_date) as order_num
FROM orders;
-- 結果:顧客ごとに合計を計算し、顧客内での注文番号を付与
FRAME CLAUSE:ウィンドウの範囲指定。
SELECT
order_date,
total_amount,
SUM(total_amount) OVER (
ORDER BY order_date
ROWS BETWEEN 2 PRECEDING AND CURRENT ROW
) as moving_sum_3
FROM orders;
-- 当日を含む直近3日間の合計
CTE(Common Table Expression)と再帰クエリ
WITH句:一時的な「中間テーブル」を定義。
WITH monthly_sales AS (
SELECT
DATE_TRUNC('month', order_date) as month,
SUM(total_amount) as total
FROM orders
GROUP BY DATE_TRUNC('month', order_date)
)
SELECT month, total,
LAG(total) OVER (ORDER BY month) as prev_month
FROM monthly_sales
WHERE total > 10000
ORDER BY month;
再帰CTE:階層構造や経路探索に。
-- 組織図:従業員と上司の関係
WITH RECURSIVE org_tree AS (
-- ベースケース:CEO(上司がいない)
SELECT employee_id, name, manager_id, 1 as level
FROM employees
WHERE manager_id IS NULL
UNION ALL
-- 再帰ケース:各上司の部下
SELECT e.employee_id, e.name, e.manager_id, ot.level + 1
FROM employees e
INNER JOIN org_tree ot ON e.manager_id = ot.employee_id
WHERE ot.level < 10 -- 無限ループ防止
)
SELECT * FROM org_tree
ORDER BY level, name;
JSON / JSONB関数
PostgreSQLではJSONをネイティブサポート。
-- JSONカラムのサンプル
CREATE TABLE user_settings (
user_id INTEGER PRIMARY KEY,
settings JSONB
);
INSERT INTO user_settings VALUES
(1, '{"theme": "dark", "notifications": true, "language": "en"}');
-- キーで抽出
SELECT settings->>'theme' as theme
FROM user_settings
WHERE user_id = 1;
-- ネスト抽出
SELECT settings->'preferences'->>'color'
FROM user_settings;
-- JSON配列に対する処理
SELECT jsonb_array_elements(settings->'tags') as tag
FROM user_settings;
-- JSONキーが存在するか
SELECT user_id
FROM user_settings
WHERE settings ? 'theme';
-- JSONを行に展開
SELECT user_id, key, value
FROM user_settings,
jsonb_each(settings);
DCL(Data Control Language)
ロール・権限管理。
-- ロール作成
CREATE ROLE analyst;
-- 権限付与
GRANT USAGE ON SCHEMA public TO analyst;
GRANT SELECT ON orders TO analyst;
GRANT SELECT ON customers TO analyst;
-- 権限剥奪
REVOKE INSERT, UPDATE, DELETE ON orders FROM analyst;
-- 行レベルセキュリティ(Row-Level Security)
-- PostgreSQL 9.5+
ALTER TABLE orders ENABLE ROW LEVEL SECURITY;
CREATE POLICY orders_by_customer ON orders
FOR SELECT
USING (customer_id = current_user_id());
-- current_user_id() はカスタム関数
インデックス詳細
インデックスは本の巻末索引に似ています。
- 強いところ: 検索を速くする
- 弱いところ: 更新コストが増える
なぜB-treeが標準か
順序づけされた比較や範囲検索と相性がよいからです。
B-tree(B-tree)の構造:
各ノードに複数のキーと子ノード参照を持つ。バランスを取ることで検索・挿入・削除がO(log n)。
メリット:
- 範囲検索に強い(
WHERE id BETWEEN 10 AND 50) - 並び順が自然(
ORDER BY id) - 等価検索も高速
デメリット:
- 挿入・更新・削除時にリバランスが必要
- メモリ・ディスク容量を消費
インデックスは無料の高速化ではない
インデックスを貼ると検索は速くなりやすいですが、そのぶん
- 追加・更新・削除時にメンテナンスが要る
- ディスクやメモリを使う
- 最適化の選択肢が増えて計画も複雑になる
という代償があります。
PostgreSQLの代表的なインデックスタイプ
B-tree:等価検索、範囲検索、並び順に強い。まず最初に検討する標準形。
CREATE INDEX idx_orders_date ON orders(order_date);
-- WHERE order_date = '2024-01-01' に有効
-- WHERE order_date >= '2024-01-01' に有効
-- ORDER BY order_dateに有効
複合索引(Multi-column Index):複数列の組み合わせ。
CREATE INDEX idx_customer_date ON orders(customer_id, order_date DESC);
-- 有効なクエリ:
-- WHERE customer_id = 1
-- WHERE customer_id = 1 AND order_date > ...
-- WHERE customer_id = 1 ORDER BY order_date DESC
-- 無効な例:
-- WHERE order_date = ... (最初の列customer_idがないため)
Hash:等価比較向けだが、用途は限定的。ハッシュテーブルと同じく衝突の可能性。
CREATE INDEX idx_email_hash ON users USING HASH(email);
-- WHERE email = '...' のみ有効。範囲検索は不可
GIN(Generalized Inverted Index):配列、全文検索、JSONBのように「中に複数要素を持つ値」に強い。
-- タグの配列の高速検索
CREATE TABLE posts (
post_id SERIAL PRIMARY KEY,
tags TEXT[]
);
CREATE INDEX idx_tags ON posts USING GIN(tags);
-- クエリ
SELECT * FROM posts WHERE tags @> ARRAY['postgres', 'database'];
-- tagsカラムがpostgresqlとdatabase両方を含む
-- JSONBの場合
CREATE TABLE configs (
config_id SERIAL PRIMARY KEY,
settings JSONB
);
CREATE INDEX idx_settings ON configs USING GIN(settings);
SELECT * FROM configs WHERE settings @> '{"theme": "dark"}';
GiST(Generalized Search Tree):幾何、近傍検索、特殊な探索条件。
-- 地理座標の近傍検索(PostGIS)
CREATE TABLE locations (
id SERIAL PRIMARY KEY,
name VARCHAR,
coord geography(POINT, 4326)
);
CREATE INDEX idx_locations_geo ON locations USING GIST(coord);
-- 東京から10km以内のスポット
SELECT * FROM locations
WHERE ST_DWithin(coord, ST_GeomFromText('POINT(139.69 35.68)', 4326), 10000);
BRIN(Block Range Index):物理的な並びと相関がある巨大テーブルに向く。
-- タイムシリーズデータ(insert_dateが昇順)
CREATE TABLE events (
event_id BIGSERIAL PRIMARY KEY,
insert_date TIMESTAMP,
event_type VARCHAR,
data TEXT
);
-- 通常のB-treeより小さいメモリ・ディスク。スキャン速度は劣るが、容量が有利
CREATE INDEX idx_events_date_brin ON events USING BRIN(insert_date)
WITH (pages_per_range = 128);
Covering Index(付属列を持つ索引):索引だけで検索完結(Index-only Scan)。
CREATE INDEX idx_customer_amount ON orders(customer_id)
INCLUDE (total_amount);
-- このクエリはIndex Only Scanで済む(テーブルアクセス不要)
SELECT customer_id, total_amount FROM orders
WHERE customer_id = 1;
Partial Index(条件付き索引):WHEREで条件を限定。容量削減。
-- アクティブな注文だけ高速検索
CREATE INDEX idx_pending_orders ON orders(order_date)
WHERE status IN ('pending', 'processing');
-- キャンセル済みや完了した注文は索引に含めない
Functional Index(関数索引):列を変換して索引。
-- 大文字小文字を区別しないメール検索
CREATE INDEX idx_email_lower ON users(LOWER(email));
SELECT * FROM users WHERE LOWER(email) = 'alice@example.com';
インデックス選びは「速そうだから貼る」ではなく、どんな条件で引くか を先に考えるのがコツです。
クエリ実行計画と最適化
SQLは宣言的です。人は「何がほしいか」を書き、DBは「どう取るか」を決めます。
EXPLAINと実行計画
EXPLAIN で、
- 全表走査
- インデックス走査
- JOINの方法
を確認できます。
PostgreSQLのEXPLAIN:
EXPLAIN (ANALYZE, BUFFERS, FORMAT JSON)
SELECT o.order_id, c.name, SUM(oi.quantity)
FROM orders o
INNER JOIN customers c ON o.customer_id = c.customer_id
INNER JOIN order_items oi ON o.order_id = oi.order_id
WHERE o.order_date >= '2024-01-01'
GROUP BY o.order_id, c.name;
出力例(簡略):
Aggregate
-> Hash Join (cost=150.00..200.00 rows=1000)
Hash Cond: (o.customer_id = c.customer_id)
-> Hash Join (cost=50.00..100.00 rows=5000)
Hash Cond: (oi.order_id = o.order_id)
-> Index Scan on order_items oi
(cost=0.42..10.00 rows=100000)
-> Seq Scan on orders o
Filter: (order_date >= '2024-01-01')
(cost=10.00..80.00 rows=500)
-> Seq Scan on customers c
(cost=10.00..50.00 rows=100)
MySQLのEXPLAIN:
EXPLAIN
SELECT o.order_id, c.name
FROM orders o
JOIN customers c ON o.customer_id = c.customer_id
WHERE o.order_date >= '2024-01-01';
/* 出力:
id, select_type, table, type, possible_keys, key, key_len, ref, rows, Extra
1, SIMPLE, o, range, idx_date, idx_date, 4, NULL, 500, Using where
1, SIMPLE, c, eq_ref, PRIMARY, PRIMARY, 4, o.customer_id, 1, NULL
*/
コストベース最適化
DBは統計情報をもとに「どの方法が安そうか」を見積もります。
統計情報の更新:
-- PostgreSQL
ANALYZE orders;
-- MySQL
ANALYZE TABLE orders;
-- あるいは自動更新(autovacuumやInnoDB_stats_auto_recalc)
見積もりのズレを確認:
EXPLAIN ANALYZE
SELECT * FROM orders WHERE customer_id = 1;
-- Planned Rows vs. Actual Rowsを比較
-- ズレが大きい = 統計が古い、または分布が偏っている
実行計画で何を見るか
最初は次の観点だけでも十分です。
- どこで行数が急増しているか
- 全表走査になっていないか
- JOIN順序は自然か
- 見積もり行数と実行実績がずれていないか
特に見積もりと実績のズレは重要で、統計情報が現実をうまく表していない可能性があります。
JOINアルゴリズムの比較
Nested Loop Join:左テーブルの各行について、右テーブルを全スキャン。
for each row in left_table:
for each row in right_table:
if join_condition:
output row
- 時間:O(m * n)(m, nはテーブルサイズ)
- 利点:メモリ効率。小さなテーブル向け
- 欠点:大規模では遅い
Hash Join:左テーブルをハッシュテーブルに構築、右テーブルをプローブ。
hash_table = build_hash_table(left_table)
for each row in right_table:
if hash_table has matching key:
output row
- 時間:O(m + n)(ハッシュ衝突なし)
- 利点:大規模テーブル向け
- 欠点:メモリ消費。並び順は失う
Merge Join(Sort-Merge Join):両テーブルをソート後、マージ。
sort left_table by join_key
sort right_table by join_key
merge sorted tables
- 時間:O(mlog m + nlog n) + O(m + n)
- 利点:結果がsorted。複数JOINでは効率的
- 欠点:ソートコスト
実行計画で -> Hash Join や -> Merge Join を見ると、DBがどれを選んだかがわかります。
パラメータ化クエリとプリペアドステートメント
SQLインジェクションを防ぎ、実行計画をキャッシュ。
-- Node.js + pgモジュール
const result = await client.query(
'SELECT * FROM orders WHERE customer_id = $1',
[123]
);
-- プリペアドステートメント(ストアドプロシージャ方式)
PREPARE get_orders AS
SELECT * FROM orders WHERE customer_id = $1;
EXECUTE get_orders(123);
複数回実行で計画がキャッシュされ、パースと最適化のオーバーヘッドが減る。
トランザクションとACID
- Atomicity
- Consistency
- Isolation
- Durability
「途中まで成功」を避けるための考え方です。
銀行振込のような処理で特に重要です。
ACIDを言い換えると
- Atomicity:まとまりとして全部やるか全部やらないか
- Consistency:ルールを破った中間状態を外へ出さない
- Isolation:同時実行しても互いの途中結果に振り回されない
- Durability:完了と返した変更は障害後も残る
これらは宣伝文句ではなく、アプリケーションが「どこまでDBを信じられるか」の境界を決めます。
トランザクション開始から終了まで
BEGIN; -- またはSTART TRANSACTION
-- 処理1
UPDATE accounts SET balance = balance - 100 WHERE id = 1;
-- 処理2
UPDATE accounts SET balance = balance + 100 WHERE id = 2;
-- 成功ならCOMMIT、失敗ならROLLBACK
COMMIT; -- またはROLLBACK;
Atomicityの保証:
BEGIN;
UPDATE a SET x = 1;
-- ここでDBがクラッシュしたら...
UPDATE b SET y = 2;
COMMIT;
-- 結果:両方成功するか両方失敗するか。中間状態はない
Consistency(制約の維持)
BEGIN;
-- 外部キー制約違反
INSERT INTO orders (customer_id, ...) VALUES (999, ...);
-- customer_id=999が存在しない場合、ここでERROR
ROLLBACK; -- 自動的に(または手動で)
Isolation(分離レベル)
同時に複数のトランザクションが実行されても、互いに邪魔しないレベル。後述で詳細。
Durability(永続性)
COMMIT; -- "OK" を返した
-- この後、電源断やディスク故障があっても、データは復旧可能
WAL(Write-Ahead Logging)で実装。
MVCCと分離レベル
MVCCは、多版を持つことで読み手と書き手の衝突をやわらげる仕組みです。
強いほど安心とは限らず、コストや再試行も増えます。
MVCCの直感
MVCCは「今この行の唯一の姿」を奪い合う代わりに、ある時点で見えている版 を読む発想です。これにより、読み手が書き手を即座に止めなくても、ある程度一貫した見え方を保てます。
PostgreSQLのMVCC実装:
各行に xmin(作成したトランザクションID)と xmax(削除したトランザクションID)がついている。
行ID=1:
data: "Alice, alice@example.com"
xmin: 100 (トランザクション100で作成)
xmax: NULL (まだ削除されていない)
(UPDATEが実行されたら)
data: "Alice, alice@new@example.com"
xmin: 105 (トランザクション105で作成)
xmax: NULL
(前のバージョン)
data: "Alice, alice@example.com"
xmin: 100
xmax: 105 (トランザクション105で削除)
トランザクション104で読むと のバージョンが見える。 トランザクション106で読むと のバージョンが見える。
Read Uncommitted(コミット前)
PostgreSQLでは実装されていません。(実質的にRead Committed)
MySQLやSQL Serverでも、ほとんど使いません。
Dirty Readの危険:
Transaction A:
UPDATE orders SET status = 'shipped' WHERE id = 1;
-- ここでまだCOMMITしていない
Transaction B(Read Uncommitted):
SELECT status FROM orders WHERE id = 1;
-- 結果:'shipped'(コミット前)
Transaction A:
ROLLBACK; -- やはりキャンセル
Transaction B(結果):
-- 見た 'shipped' は幻。実際はロールバック
Read Committed(コミット後の値のみ読む)
PostgreSQLのデフォルト。MySQL(InnoDB)のデフォルト。
- Dirty Read:ない
- Non-repeatable Read:あり
- Phantom Read:あり
Transaction A:
SELECT balance FROM accounts WHERE id = 1;
-- 結果:1000
Transaction B:
UPDATE accounts SET balance = 500 WHERE id = 1;
COMMIT;
Transaction A:
SELECT balance FROM accounts WHERE id = 1;
-- 結果:500(同じクエリなのに変わった!)
「Non-repeatable Read」:同じクエリが異なる結果を返す。
Repeatable Read(トランザクション開始時点での版を読む)
MySQL(InnoDB)のデフォルト。PostgreSQLでは別の実装。
- Dirty Read:ない
- Non-repeatable Read:ない
- Phantom Read:あり(MySQL)、ない(PostgreSQL)
Transaction A:
SELECT COUNT(*) FROM orders WHERE customer_id = 1;
-- 結果:5件
Transaction B:
INSERT INTO orders (...) VALUES (customer_id=1, ...);
COMMIT;
Transaction A:
SELECT COUNT(*) FROM orders WHERE customer_id = 1;
-- 結果:5件(同じ)。だがUPDATEでは新行が見える(Phantom Read)
SELECT * FROM orders WHERE customer_id = 1;
-- 結果:6行(新しい行が見える!)
「Phantom Read」:集計は変わらないが、実際のデータセットは変わる。
Serializable(完全分離)
複数トランザクションが順序実行(シリアル)と同じ結果。
- Dirty Read:ない
- Non-repeatable Read:ない
- Phantom Read:ない
PostgreSQLの実装:Serializable Snapshot Isolation(SSI)
Transaction A:
SELECT COUNT(*) FROM orders WHERE customer_id = 1;
-- 結果:5件
Transaction B:
INSERT INTO orders (...) VALUES (customer_id=1, ...);
COMMIT;
Transaction A:
-- もう一度クエリを実行したら再試行が必要(依存関係を検出)
-- エラー:「serialization failure」
DBがAとBの実行順序を決定して、矛盾を防ぐ。アプリは再試行を実装する必要。
コスト:再試行ロジック、スループット低下。
分離レベルは安心の強さではなく見え方の契約
Serializable が最強だから常に正しい、という理解は少し粗いです。強い分離は再試行や性能コストを伴います。現場では、
- この処理は多少古い値でもよいか
- 同じトランザクション中で見え方が変わると困るか
- 集計の整合性がどこまで必要か
を基準に選びます。
ロックと同時実行制御
ロック種別
共有ロック(Shared Lock, S-lock):読み取り用。複数トランザクションが同時に持つことができる。
SELECT * FROM orders WHERE id = 1 FOR SHARE;
排他ロック(Exclusive Lock, X-lock):更新・削除用。1つのトランザクションのみが持つことができる。
SELECT * FROM accounts WHERE id = 1 FOR UPDATE;
テーブルロックvs行ロック
テーブルロック:テーブル全体をロック。オーバーヘッド少ないが、競合も増える。
LOCK TABLE orders IN EXCLUSIVE MODE;
行ロック:特定の行だけロック。より細かい制御が可能。
SELECT * FROM orders WHERE id = 1 FOR UPDATE;
Intent Lock(意図ロック)
階層的なロック構造。
- テーブルに意図ロックを取得してから、行にロックを取得。
- 他のトランザクションが「この行はロック予定」を事前に知れる。
Intent Shared(IS):この行を読むつもり。 Intent Exclusive(IX):この行を書くつもり。
Deadlock(デッドロック)
2つ以上のトランザクションが互いのロックを待つ循環。
Transaction A:
LOCK orders (row 1)
(waiting for accounts)
Transaction B:
LOCK accounts (row 1)
(waiting for orders)
-> Deadlock!
対策:
- 一貫した順序でロック:常にorders → accountsの順
- タイムアウト:待機時間の上限設定
- Deadlock検出:DBが検出して自動ロールバック
-- PostgreSQLでの自動検出
-- デフォルトで有効。エラー:ERROR: deadlock detected
-- タイムアウト設定
SET lock_timeout = '1000ms';
SET statement_timeout = '5000ms';
WALと リカバリ
Write-Ahead Logging(WAL)
変更を確定する前に、ログに記録。
1. メモリ内で変更
2. WAL(ログファイル)に書き込み(ディスク)
3. メモリのデータをディスク(データファイル)に書き込み
利点:
- クラッシュ時にWALからリカバリ可能
- ディスク書き込みが非効率的でも、ログ追記なら効率的
チェックポイント
定期的にメモリのダーティデータをディスクにフラッシュ。
Checkpoint:
1. メモリ内の全ダーティデータをディスク書き込み
2. チェックポイント記録
3. 古いWALログを削除可能にする
PostgreSQL:
checkpoint_timeout = 15min (15分ごと)
checkpoint_completion_target = 0.9 (目標進捗90%)
ARIESアルゴリズム
Algorithms for Recovery and Isolation Exploiting Semantics
DBリカバリの実装標準。3フェーズ。
1. Analysis Phase: WALを読み、クラッシュ直前の状態を把握
2. Redo Phase: コミットされた変更を再度実行
3. Undo Phase: コミットされなかった変更をロールバック
NoSQLとNewSQL
NoSQL
- キーバリュー
- ドキュメント
- 列指向
- グラフ
- 時系列
- 検索エンジン
それぞれ強みが違います。
NoSQLは「SQLではない」より「データモデルが違う」
NoSQLは反SQLの思想というより、問題に応じて別のデータモデルを選ぶ流れとして見るほうが正確です。
キーバリュー: 単純で高速な一点参照。
Redis:
SET user:1 '{"name": "Alice", "email": "alice@..."}'
GET user:1
メリット:O(1) の高速アクセス
デメリット:複雑な検索・JOINが困難
ドキュメント: 可変スキーマやネスト構造。
MongoDB:
{
"_id": ObjectId("..."),
"name": "Alice",
"orders": [
{ "order_id": 1, "total": 100 },
{ "order_id": 2, "total": 200 }
]
}
メリット:ネスト構造の自然な表現。柔軟なスキーマ
デメリット:JOINはない。集計が複雑。トランザクションの扱い
列指向(列族): 大規模分析や圧縮。
Cassandra/HBase:
行キー = customer_id
列族1 (profile): name, email, address
列族2 (stats): total_orders, last_purchase
メリット:大規模データの効率的な圧縮。分散書き込み
デメリット:複雑なクエリが困難
グラフ: 関係そのものが主役。
Neo4j:
(Alice) -[:KNOWS]-> (Bob) -[:WORKS_AT]-> (CompanyX)
クエリ:Aliceが知っている人が働いている会社は?
Neo4jでは効率的。RDBでは複数JOIN
メリット:関係の深掘りが高速
デメリット:分散が困難
時系列: 時間順データの書き込みと集計。
InfluxDB / Prometheus:
measurement = "temperature"
tags = {"location": "room1", "sensor": "A"}
time = 2024-01-01T10:00:00Z
value = 23.5
メリット:時間軸での効率的なクエリ。自動ダウンサンプリング
デメリット:任意の過去時点への戻しが困難
検索エンジン(Text Search): 転置索引と全文検索。
Elasticsearch:
インバートインデックス = {word -> [doc1, doc2, doc3]}
「database tutorial」の全文検索
メリット:あいまい検索、ランキング、複雑なクエリ
デメリット:同期のオーバーヘッド、容量
NewSQL
SQLと強い整合性を保ちつつ、分散も扱いたい系統です。
Google Spanner(2012):
- グローバルに分散したACIDトランザクション
- 外部整合性(外部観察者の時系列に従う)
- Paxosベースの同期複製
適用:グローバル金融、eコマース
Transaction A (Location A) writes at t1
Transaction B (Location B) reads at t2 (t2 > t1)
Spannerは、BがAの結果を確実に見る。
CockroachDB(2015):
- Spannerの思想をオープンソース化
- SERIALIZABLE分散トランザクション
- 自動フェイルオーバー
TiDB(PingCAP、2015):
- MySQL互換SQLインターフェース
- Raftベース複製
- 行指向ストレージ(TiKV)
YugabyteDB(2016):
- ACID分散トランザクション
- PostgreSQL互換SQL
- 高可用性
レプリケーション
複製して、
- 可用性
- 読み取り性能
を上げます。
ただし複製は「ただコピーすれば終わり」ではありません。
- どのくらい遅れてよいか
- 障害時に誰を正とするか
- 読み取り先をどう選ぶか
が設計に入ります。
同期複製vs非同期複製
同期複製(Synchronous Replication):
Primaryが書き込みを受け取る
-> すべてのReplicaに送信
-> ReplicaからACKを待つ
-> クライアントにOKを返す
メリット:Replicaも常に最新。可用性が高い。 デメリット:1つのReplicaが遅いと全体が遅い。スループット低下。
非同期複製(Asynchronous Replication):
Primaryが書き込みを受け取る
-> クライアントにOKを返す
-> バックグラウンドでReplicaに送信
メリット:高速。スループット有利。 デメリット:Replicaは遅れている。Primary障害時にデータ喪失の危険。
Physical Replication vs Logical Replication
Physical Replication:
ディスク上のバイト列をコピー。
- 最も高速で信頼できる
- ただしPrimaryとReplicaのバージョンが同じ必要
- マイナーバージョン違いでも不可
PostgreSQL streaming replication
MySQL binary log(row format)
Logical Replication:
SQLステートメント(INSERT, UPDATE, DELETE)をコピー。
- 異なるバージョン間で可能
- 部分的な複製も可能(特定テーブルのみなど)
- ただし関数呼び出しなどで再現不可な場合も
PostgreSQL logical replication
MySQL binary log(statement format)
MySQL Group Replication
レプリケーションラグと一貫性
時間→
Primary: 変更t1 → t2 → t3 → (クライアント読み取り)
Replica: 変更t1 (遅延 Δt) → t2 → (読み取り要求)
結果:Replicaがt3の変更を見ていない
Replication Lag:PrimaryとReplicaの時間差。
対策:
- 読み取りをPrimaryへ:確実だが、スケーラビリティ低下
- Replicaからの読み取りを受け入れ:古い可能性を許容
- Causal Consistency:同じセッション内では最新を見る
シャーディングと分散
分割して、
- 書き込み規模
- 容量
に対応します。
シャーディングは容量と負荷に効きますが、その代わり
- JOINが難しくなる
- 集計が複雑になる
- ホットスポットが生まれる
- 再配置が重い
といった新しい問題を持ち込みます。
シャーディングキー選択
Range Sharding:
Shard A: customer_id 1-1000
Shard B: customer_id 1001-2000
Shard C: customer_id 2001-3000
メリット:実装が簡単。 デメリット:ホットスポット(新規ユーザーがShard Cに集中)。
Hash Sharding:
Shard = HASH(customer_id) % 3
customer_id=1 -> HASH=0x5f3759 -> 0x5f3759 % 3 = 1 -> Shard B
customer_id=2 -> HASH=0x3c001 -> 0x3c001 % 3 = 0 -> Shard A
メリット:分散が均等。ホットスポット回避。 デメリット:再シャーディング時に全データ移動。
Geographic Sharding:
Shard JP: customer_idでcountry='JP'
Shard US: customer_idでcountry='US'
メリット:地理的レイテンシ削減。規制対応(GDPR)。 デメリット:地域間の不均衡。
Consistent Hashing
シャードが増減しても、ほとんどのキーのマッピングは変わらない。
キーとShardをハッシュリング上に配置:
[Shard A]
/ \
[Key1] [Shard B]
/ \
[Key3] [Key2]
| |
[Shard C] -----> [Shard D]
新しいShard Dが加わると、その隣のShard Cの一部だけがDに移動。全部ではなく。
OLTPとOLAP
- OLTP:On-Line Transaction Processing。日々の更新と参照
- OLAP:On-Line Analytical Processing。集計と分析
ここを混同すると、本番DBに重い分析を投げて苦しみます。
なぜ分けるのか
OLTPは少量・高速・多数同時実行が中心で、OLAPは大量読み取り・集計・列指向最適化が中心です。求める性質がかなり違うので、同じ設計で両方を完璧に満たすのは難しいです。
データウェアハウスとの境界
OLTP向けRDBMS:
- 行指向(各行をまとめてディスク保存)
- インデックス重視
- 更新最適化
- 小規模SQL(数秒以下)
- 例:PostgreSQL, MySQL, Oracle
OLAP向けウェアハウス:
- 列指向(各列をまとめてディスク保存)
- 圧縮・集計最適化
- 読み取り重視
- 大規模SQL(分単位)
- 例:Redshift, BigQuery, Snowflake
列指向が有利な理由:
行指向(10列):
[customer_id, name, email, address, phone, country, status, created_at, updated_at, notes]
[customer_id, name, email, address, phone, country, status, created_at, updated_at, notes]
...
クエリ「2024年に作成された顧客のcountry分布」
-> すべての列を読む必要はない。created_at, countryだけで十分。
列指向:
created_at: [2023-01-01, 2024-01-15, 2024-03-20, ...]
country: [JP, US, JP, ...]
クエリでは2列だけスキャン
+ countryでグループ化
新時代データベース
DuckDB(エッジ&分析用SQL)
2023-2024年で注目。
特徴:
- インプロセスSQLエンジン(C++)
- SQL (SELECT, JOIN, GROUP BY)をサポート
- Parquetファイル、CSV、Pandas DataFrameを直接クエリ
- 列指向
- 0デプロイ(単一バイナリ)
使用シーン:
import duckdb
# CSVから直接クエリ
result = duckdb.sql("""
SELECT country, COUNT(*) as count
FROM read_csv('customers.csv')
WHERE created_at > '2024-01-01'
GROUP BY country
""").fetch_all()
# Parquetへの書き込み
duckdb.sql("""
COPY (
SELECT * FROM read_csv('data.csv')
) TO 'output.parquet'
""")
メリット:エッジデバイス、データ分析、小規模BIでの活躍。
Vector DatabaseとAI
生成AIの普及で新ジャンル。
pgvector(PostgreSQL):
CREATE EXTENSION vector;
CREATE TABLE documents (
id SERIAL PRIMARY KEY,
content TEXT,
embedding vector(1536) -- OpenAI embedding
);
-- 埋め込みを挿入
INSERT INTO documents (content, embedding)
VALUES ('PostgreSQL is great', '[0.1, -0.2, 0.3, ...]'::vector);
-- 類似検索(コサイン距離)
SELECT content, embedding <-> '[0.1, -0.2, 0.3, ...]'::vector as distance
FROM documents
ORDER BY distance
LIMIT 5;
Pinecone, Weaviate, Milvus:
専用のVector DB。インデックス(HNSW, IVF)で1000万次元以上をサポート。
Lakehouse:ACID + 分析
Delta Lake(Databricks)、Iceberg(Apache)、Hudi(Uber)。
特徴:
Lakehouse = Data Lakeの信頼性をRDBMS並みに
- ACIDトランザクション
- スキーマ管理
- タイムトラベル(過去の状態へアクセス)
- 行・列レベルのセキュリティ
-- Delta Lake on Databricks
SELECT year, COUNT(*) as count
FROM events
WHERE year >= 2024
GROUP BY year;
-- 過去の状態へアクセス
SELECT * FROM events VERSION AS OF 5; -- バージョン5
-- タイムトラベル
SELECT * FROM events TIMESTAMP AS OF '2024-01-01T00:00:00Z';
運用と実務
DBAと設計フェーズ
DBの仕事はSQLを書いて終わりではありません。設計、性能、障害対応、容量計画まで含めて見ていく必要があります。
設計では、次のような段階で考えると整理しやすいです。
- 概念設計: 何を管理したいか、どのエンティティがあるかを決める
- 論理設計: テーブル、キー、制約、正規化を決める
- 物理設計: インデックス、パーティション、配置、バックアップ方針を決める
運用では、DBA的な視点が重要になります。
- バックアップと復旧手順を持つ
- 権限と監査の境界を決める
- 容量増加を見越して拡張計画を立てる
- 性能劣化を実行計画と統計の観点で追う
- 障害時に復旧優先か整合性優先かを判断する
アプリ開発者であっても、この視点を持っているだけで「後から困る設計」をかなり減らせます。
N+1問題
パターン:アプリケーション側でのJOINの誤り。
# 悪い例:N+1
customers = db.query("SELECT * FROM customers LIMIT 10")
for customer in customers:
orders = db.query(f"SELECT * FROM orders WHERE customer_id = {customer.id}")
# 1回のcustomersクエリ + 10回のordersクエリ = 11クエリ
# 改善:JOIN
result = db.query("""
SELECT c.*, o.*
FROM customers c
LEFT JOIN orders o ON c.id = o.customer_id
LIMIT 10
""")
インデックスチューニング
-- 遅いクエリを特定
SELECT query, calls, total_time, mean_time
FROM pg_stat_statements
ORDER BY mean_time DESC
LIMIT 10;
-- 実行計画を確認
EXPLAIN ANALYZE SELECT * FROM orders WHERE customer_id = 1;
-- インデックスを追加
CREATE INDEX idx_customer_id ON orders(customer_id);
-- 統計を更新
ANALYZE orders;
-- 再度確認
EXPLAIN ANALYZE SELECT * FROM orders WHERE customer_id = 1;
-- Seq ScanがIndex Scanに変わったか確認
スローログの活用
-- PostgreSQL: log_min_duration_statement
log_min_duration_statement = 1000 -- 1秒以上のクエリをログ
-- MySQL: slow_query_log
slow_query_log = 1
long_query_time = 1
log_queries_not_using_indexes = 1 -- インデックス未使用も記録
Prepared StatementとORMのピットフォール
Prepared Statement:SQLインジェクション防止、実行計画キャッシュ。
// Node.js + pg
const result = await client.query(
'SELECT * FROM orders WHERE customer_id = $1',
[123]
);
ORMでのN+1:
# Django ORMの例
orders = Order.objects.all()[:10]
for order in orders:
print(order.customer.name) # N+1! 顧客を毎回取得
# 改善:select_related
orders = Order.objects.select_related('customer').all()[:10]
バックアップと復旧
-- PostgreSQL
pg_dump -Fc -d mydb > backup.dump
-- 復旧
pg_restore -d mydb backup.dump
-- ポイントインタイムリカバリ(PITR)
-- WALアーカイブを使う。特定時刻へ復旧
監視と アラート
-- キャッシュヒット率(PostgreSQL)
SELECT
sum(heap_blks_hit) / (sum(heap_blks_hit) + sum(heap_blks_read)) as ratio
FROM pg_statio_user_tables;
-- アクティブな接続(MySQL)
SELECT count(*) FROM information_schema.processlist WHERE command != 'Sleep';
-- トランザクション未コミット(PostgreSQL)
SELECT * FROM pg_stat_activity
WHERE state != 'idle' AND xact_start < now() - INTERVAL '10 minutes';
実務ミニケース
ECサイトの商品一覧が遅い
まず疑うのは、
- WHERE条件に合う索引があるか
- ソート条件まで索引で支えられるか
- JOIN順序が不自然ではないか
- 返しすぎていないか
です。
-- 遅いクエリ例
SELECT * FROM products
WHERE category_id = 5 AND price < 10000
ORDER BY created_at DESC
LIMIT 20;
-- EXPLAINで確認
EXPLAIN ANALYZE SELECT ...;
-- 複合索引を追加
CREATE INDEX idx_category_price_date ON products(category_id, price, created_at DESC);
-- またはカバリング索引(すべての列を含む)
CREATE INDEX idx_category_price_date_covering ON products(category_id, price, created_at DESC)
INCLUDE (id, name, image_url, price); -- SELECTの列すべて
-- Index Only Scanが使われるようになる
在庫更新が競合する
単にアプリでif文を書くより、
- トランザクション
- 適切な分離レベル
- 行ロック
- 一意制約
を組み合わせて守るほうが堅いことが多いです。
BEGIN;
SELECT quantity FROM inventory WHERE product_id = 1 FOR UPDATE;
-- 行ロック。この商品の在庫を更新する
IF quantity >= requested_quantity THEN
UPDATE inventory SET quantity = quantity - requested_quantity WHERE product_id = 1;
COMMIT;
ELSE
ROLLBACK;
-- 在庫不足
END IF;
分析クエリで本番が重い
OLTPとOLAPの役割分離、レプリカ、ETL、列指向基盤の検討が必要になります。
本番OLTP DB
|
| Streaming Replication (非同期)
v
Replica DB (読み取り専用)
|
| ETL (Airflow / dbt)
v
Data Warehouse (Snowflake / Redshift)
|
v
BI / Analytics (Tableau / Metabase)
制約とアプリケーションロジック
業務ルールをどこに置くかは大きな設計論点です。
- DB制約で守るべきもの
- アプリで判断すべきもの
- 両方で二重に守るべきもの
があります。
DBで守るべきもの
- 一意性
- 参照整合性
- NULL禁止
のように、データ自体の不変条件はDBに寄せるほうが堅いことが多いです。
アプリで扱うべきもの
- 業務フロー
- 画面遷移
- 外部サービス連携
のように、文脈依存の判断はアプリ側が担うことが多いです。
スキーマ変更と運用
本番DBは「作って終わり」ではありません。列追加、型変更、索引追加、データ移行など、変更を安全に進める運用が必要です。
なぜ難しいか
- アプリとDBの互換性を保つ必要がある
- 大きな表では変更が重い
- ロックや長時間実行の影響がある
そのため実務では、段階的移行、後方互換、バックフィルのような考え方が重要になります。
クエリ改善の流れ
遅いクエリを見たとき、最初から索引追加に飛ばず、
- 本当に必要なデータだけ取っているか
- 実行計画はどうなっているか
- 統計は新しいか
- 索引設計は問いに合っているか
の順で見ると整理しやすいです。
設計原則として見るDB
DB設計では、モデルの美しさだけでなく、
- どんな問い合わせがあるか
- どんな更新競合が起こるか
- どこまで強い整合性が必要か
- 障害時にどう戻すか
を一緒に考える必要があります。
正規化と運用のバランス
理論上きれいな設計でも、実際の問い合わせや分析が極端に不便なら、補助的な非正規化や集約表が必要になることがあります。理論と運用は対立ではなく、両方を見る対象です。
比較で理解する
制約とバリデーション
- DB制約:データそのものの不変条件を守る
- アプリのバリデーション:入力や業務フローの文脈を扱う
片方だけで全部を背負わない方が自然です。
レプリカとキャッシュ
- レプリカ:DBの複製として比較的新しいデータを返す
- キャッシュ:速さ優先で、さらに古い可能性もある
読み取り最適化でも、整合性の期待値が違います。
判断の指針
DB設計やクエリ改善で迷ったときは、
- どの問い合わせが主役か
- 更新競合はどこで起こるか
- どこまで厳密な整合性が必要か
- 制約で守るべきことは何か
- 将来の変更コストはどれくらいか
を先に見ると判断しやすいです。
典型的な判断例
- 遅い一覧画面:索引と返却件数を先に見る
- 重複登録:一意制約やトランザクションを考える
- 分析クエリ:OLTP系へ直接載せない構成を考える
FAQ
インデックスを増やせば速くなるか
なりません。読み取りは速くなっても、更新コストや容量、計画の複雑さが増えます。問い合わせと更新のバランスを見る必要があります。
NoSQLはリレーショナルDBの上位互換か
違います。得意分野が違います。関係と整合性を強く持ちたいならRDBが自然な場面は多いです。
Serializableなら全部安心か
強い保証はありますが、再試行やスループットのコストも上がります。必要な整合性に対して過不足なく選ぶのが大事です。
ミニ比較表
| 概念 | 強いところ | 注意点 |
|---|---|---|
| B-tree | 等価検索、範囲検索、並び順 | 更新コストが増える |
| GIN | 配列、全文検索、JSONB | 汎用一点検索の万能薬ではない |
| MVCC | 読み書き競合の緩和 | ロック不要になるわけではない |
| レプリケーション | 可用性、読取分散 | 遅延や正系切替の設計が要る |
| シャーディング | 容量と書込スケール | 集計やJOINが難しくなる |
| OLTP | 日々の更新処理 | 重い分析とは相性が悪い |
次に読むなら
- 並行性と分散:並行性と分散システム
- ネットワーク越しのサービス設計:ネットワーク
補足
第8章 データベース
「データを永続化する」にはファイルで十分なようで、実は足りません。本章では なぜDBが必要か(同時更新・一貫性・検索性)、リレーショナルDBの中核概念(主キー・外部キー・インデックス・トランザクション)、EXPLAIN / 実行計画の読み方、NoSQLの立ち位置 を押さえます。
データベースの本質は「大量のデータを安全かつ効率よく扱うこと」です。本章ではSQLの書き方だけでなく、その裏にある索引、トランザクション、同時実行も見ます。
この章が実務で役立つ場面
- 遅いクエリの改善やインデックス設計
- 二重更新や不整合の防止
- アプリ設計時に整合性と性能を両立させる判断
8.1なぜファイルでは足りないのか
単なるファイル保存だけでは、
- 検索しづらい
- 同時更新が危ない
- 一貫性を保ちにくい
という問題があります。
8.2リレーショナルデータベース
データを表形式で整理し、SQLで扱います。
重要語:
リレーショナルデータベースで大事なのは、「表で保存すること」だけではありません。データ同士の関係を、主キー・外部キー・制約によって機械的に守れることが大きな強みです。
8.2.1正規化は何のためにあるか
正規化は、データの重複を減らし、更新時の不整合を防ぐための考え方です。
たとえば顧客住所を注文テーブルの全行に書いてしまうと、住所変更時に多くの行を直す必要が出ます。1行だけ修正漏れがあると、どれが正しい住所かわからなくなります。
そこで、
- 顧客は顧客テーブル
- 注文は注文テーブル
に分け、キーでつなぐわけです。
正規化は「JOINが増えるから悪い」とだけ見ると片手落ちで、まずは 更新異常を防ぐための設計 だと捉えるのがよいです。
8.3主キーと外部キー
主キー
行を一意に識別するためのキーです。
外部キー
別テーブルの主キーを参照して、関係を表します。
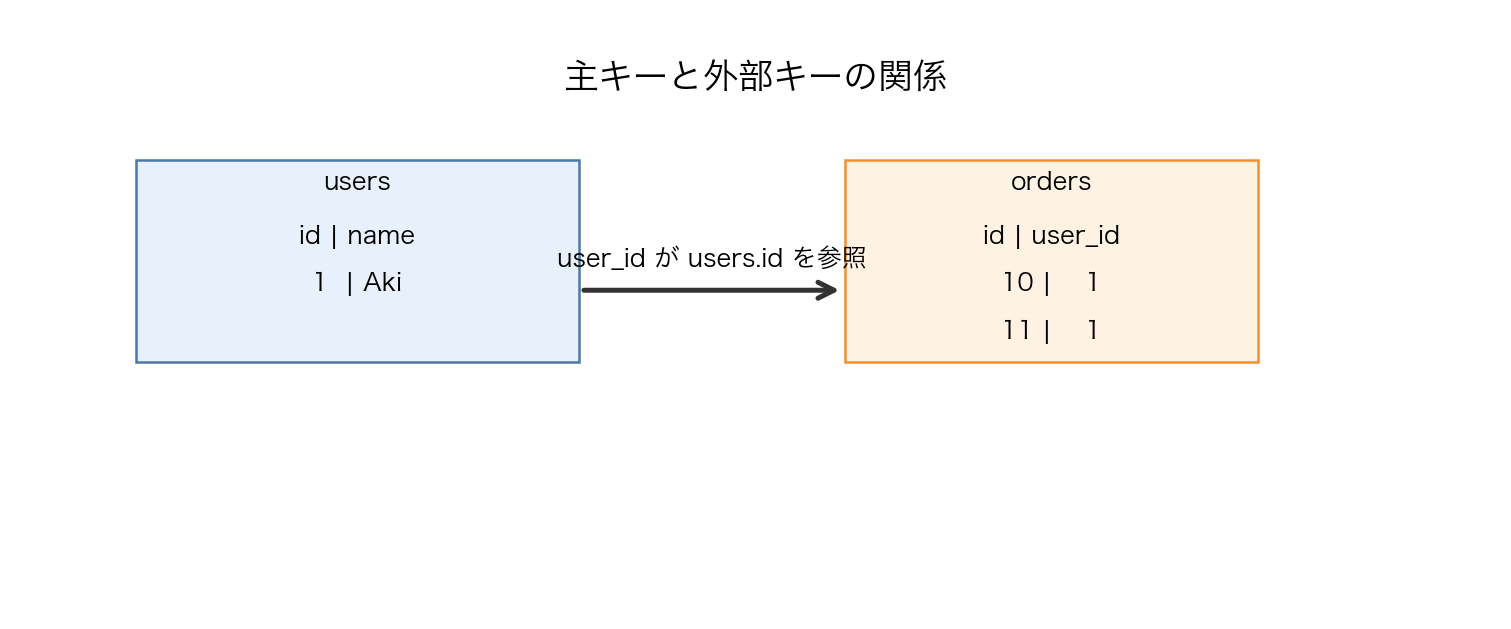
ここでいう「関係」は、アプリケーションの中だけでなんとなく守るのではなく、DB自体に守らせることが重要です。たとえば注文が存在しない商品を参照していたら困るので、外部キー制約でその不整合を防ぎます。
【図22-2】主キーと外部キーで表す関係:
8.4インデックス
インデックスは、本の索引のようなものです。検索を速くしますが、更新コストは増えます。
【図23】インデックスの効果:
DBの公式ドキュメントでも、インデックスは「特定の行をより速く見つけて取り出す」ための代表的な仕組みとして説明されています。ただし、作るほど更新負荷や管理コストも増えるので、むやみに増やせばよいわけではありません。
8.4.1 B-treeはなぜよく出てくるか
多くのDBでデフォルトなのがB-tree系インデックスです。これは
=<,<=,>=,>BETWEENIN
のような、順序づけできる比較と相性がよいからです。
また、先頭一致のパターン検索や ORDER BY にも効く場面があります。逆に、LIKE '%foo' のように先頭が曖昧な検索では効きにくいことがあります。
8.5 SQLの直感
SQLは「どのデータがほしいか」を宣言的に書きます。
例:
SELECTWHEREJOINGROUP BY
ここでのポイントは、SQLは基本的に「どう走査するか」を人が逐一書くのではなく、「何がほしいか」を書く言語だということです。実際の探索順序や索引利用、ソート方法の多くはクエリプランナが考えます。
8.5.1 EXPLAINは何を見る道具か
SQLは宣言的に書くので、「どう実行されたか」は見えにくいです。そこで使うのが EXPLAIN です。
EXPLAIN は、プランナがそのSQLを
- 全表走査で読むのか
- インデックス走査を使うのか
- どのJOINアルゴリズムを選ぶのか
を見せてくれます。
【図24】EXPLAINによる実行計画の確認:
8.5.2コストベース最適化の直感
クエリプランナは、雑に言えば「どのやり方が安そうか」を見積もって実行計画を選びます。これがコストベース最適化です。
たとえば、
- テーブル全体を読む
- インデックスで絞る
- どちらの表からJOINを始めるか
といった選択肢の中から、統計情報を使って比較します。
なのでSQL最適化は、
- 文章をきれいに書くこと
だけではなく、
- 索引を整える
- 統計情報を新しくする
- データ分布を理解する
こととも密接につながっています。
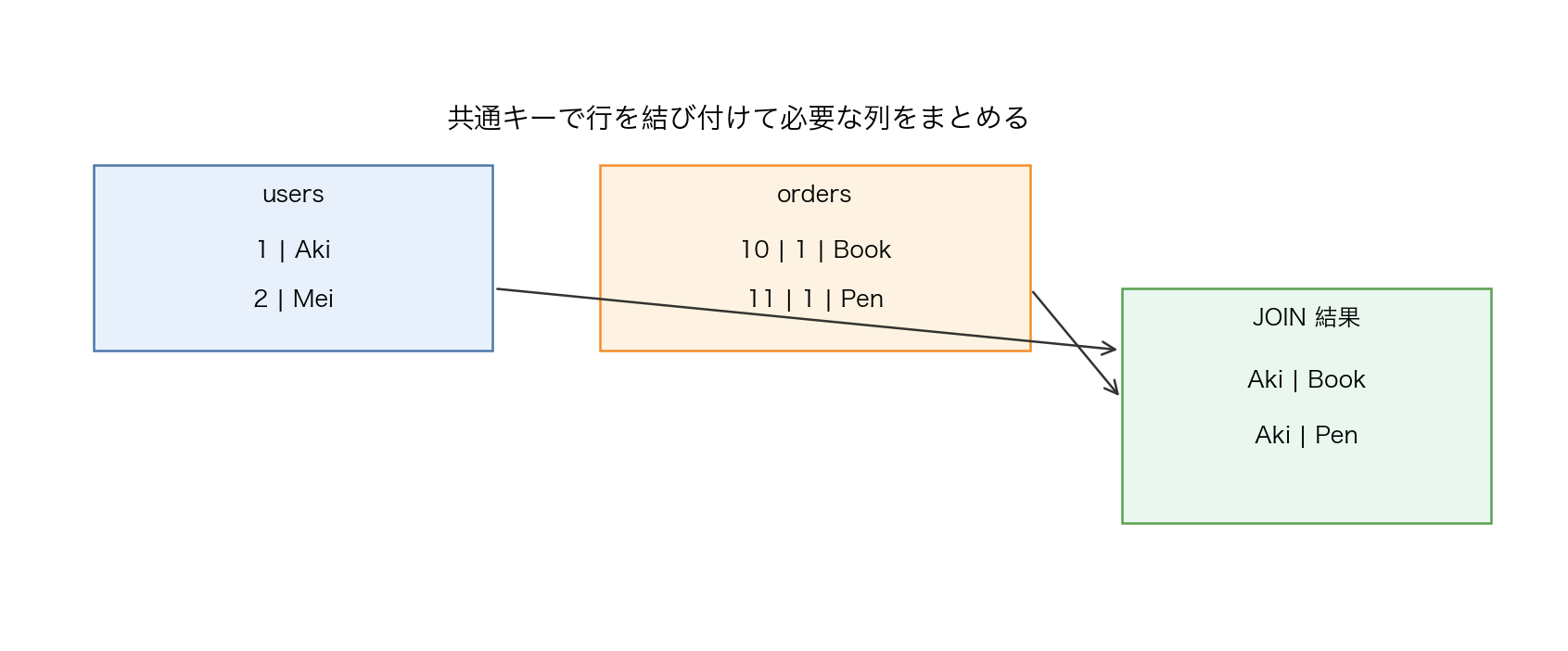
8.6 JOINの意味
JOINは、複数テーブルの関係をたどって必要な情報を組み合わせる操作です。
8.7トランザクションとACID
- Atomicity
- Consistency
- Isolation
- Durability
これは、「途中で壊れたり、同時更新で不整合になったりしても、全体として筋が通るようにする」ための性質です。
実際のDBでは、これを支える仕組みとしてログ、ロック、MVCC、回復処理などが組み合わさります。ここは「ACIDという呪文を覚える章」ではなく、「複数人が同時に触っても壊れにくくする設計思想を学ぶ章」だと思うと腹落ちしやすいです。
【図24-2】送金処理を1つのトランザクションで扱う理由:
8.8ロックと同時実行
複数ユーザーが同時に更新すると競合が起きます。そこで
- ロック
- MVCC
- 分離レベル
のような仕組みが使われます。
PostgreSQLのようなシステムではMVCCが重要です。直感的には、「いま見ているデータの写真」を各文や各トランザクションが持ちながら進むイメージです。これにより、読む人と書く人が毎回真正面からぶつからずに済みます。
8.8.1分離レベルをどう考えるか
分離レベルは、「同時実行をどこまで厳密に単独実行に近づけるか」の設定です。
- Read Committed: PostgreSQLの既定。各文が開始時点のスナップショットを見る
- Repeatable Read: 取引の途中で見え方がぶれにくい
- Serializable: 直列実行と同等の結果になるよう最も強く守る
強く守るほど気楽に考えられる場面もありますが、再試行やオーバーヘッドへの配慮が必要になります。ここは「強いほど常に正義」ではなく、「どの一貫性が必要か」を見る章です。
【図25】トランザクション分離レベルの強度:
8.9 NoSQLの立ち位置
NoSQLは「SQLの代わり」ではなく、違う強みを持つ選択肢です。
- キーバリュー
- ドキュメント
- 列指向
- グラフ
など、用途に応じた形式があります。
つまり判断軸は「新しいか古いか」ではなく、
- 厳密な整合性をどこまで強く求めるか
- JOINや複雑な問い合わせがどれくらい必要か
- 書き込み規模や分散前提がどれくらい強いか
です。
NoSQLの主要カテゴリと代表例
| 種類 | 代表製品 | 強み | 典型用途 |
|---|---|---|---|
| キーバリュー | Redis、DynamoDB、Memcached | 超高速、シンプル | セッション、キャッシュ |
| ドキュメント | MongoDB、Couchbase、Firestore | 柔軟なスキーマ | CMS、コンテンツ、設定 |
| 列指向 | Cassandra、HBase、ScyllaDB | 大規模書き込み、時系列 | IoT、ログ、メトリクス |
| グラフ | Neo4j、Amazon Neptune、ArangoDB | 関係性の探索 | SNS、推薦、不正検知 |
| 時系列DB | InfluxDB、TimescaleDB、Prometheus | 時間軸の圧縮・集約 | 監視、IoT |
| 検索エンジン | Elasticsearch、OpenSearch、Meilisearch | 全文検索、分析 | ログ検索、サイト検索 |
| 新世代RDB(NewSQL) | Google Spanner、CockroachDB、TiDB、YugabyteDB | SQL + 水平分散 | グローバルサービス |
各カテゴリをもう少し丁寧に見る
キーバリュー
もっとも単純で、「キーを指定して値を取る」ことに特化しています。
- 強いところ: とにかく速い
- 弱いところ: 複雑な検索や結合は苦手
キャッシュやセッション管理に強いのは、「IDを指定したらすぐ返す」で十分な場面が多いからです。
ドキュメント
JSONのような、入れ子を持つ柔軟な構造をそのまま持ちやすいのが特徴です。
- 強いところ: スキーマ変更に比較的強い
- 弱いところ: 複雑な整合性や横断的な結合は設計に工夫がいる
「データごとに少し形が違う」コンテンツ系や設定管理で使いやすいです。
列指向
名前が少し紛らわしいですが、ここでいう列指向は「同じ列の値をまとめて持ちやすい」ことで、大量書き込みや時系列の扱いと相性がよいです。
- 強いところ: 大規模データ、圧縮、集約
- 弱いところ: 小さく細かいトランザクション更新には向かないことがある
監視やログ基盤でよく見るのはこの性質によります。
グラフ
人や物の「つながり」そのものを中心に扱うDBです。
- 強いところ: 何段か先の関係をたどる問い合わせ
- 弱いところ: 単純なキー検索だけならオーバースペックになりやすい
SNSの友人関係、推薦、不正検知で強いのは、「関係を何度もたどる」処理が得意だからです。
時系列DB
時間とともに増えるデータを扱うのに特化しています。
- 強いところ: 時間窓集計、圧縮、ダウンサンプリング
- 弱いところ: 一般的な業務データの複雑な結合
メトリクス、監視、IoTでよく使われます。
検索エンジン
全文検索やランキングが得意です。
- 強いところ: 単語検索、あいまい検索、集計
- 弱いところ: 厳密なトランザクション整合性
「DBの代わり」というより、「検索のための別の武器」と考えると整理しやすいです。
SQLや強い整合性の気持ちよさを保ちながら、水平分散まで視野に入れた系統です。
- 強いところ: SQLの使いやすさと分散性の両立
- 弱いところ: システムが複雑で、運用や理解の難易度が上がりやすい
グローバルサービスや分散トランザクションで注目されます。
8.10レプリケーションとシャーディング
レプリケーション:同じデータを複数ノードにコピー。可用性と読み取りスケーラビリティ向上。
- 同期レプリケーション:全レプリカ書き込み完了まで待つ(整合性強、書き込み遅)
- 非同期レプリケーション:プライマリ書き込み完了したら返す(速いが一部データ損失の可能性)
- 準同期:多数決レプリカだけ同期(例:Raft)
シャーディング(Partitioning):データを複数ノードに分散。書き込みスケーラビリティ向上。
- Range sharding:範囲で分割(キー1-1000はnode1、1001-2000はnode2)
- Hash sharding:ハッシュで分割(均等だが範囲クエリが非効率)
- Directory sharding:ルックアップテーブル経由(柔軟だがSPOF)
8.10.1 OLTPとOLAP
DBの使い方は大きく2系統あります。
- OLTP: 日々の登録・更新・参照をさばく
- OLAP: 集計・分析・レポート作成を行う
OLTPは少数行をすばやく安全に更新するのが得意で、OLAPは大量データをまとめて読んで傾向を見るのが得意です。
ここを混同すると、
- 本番DBに重い集計を投げて遅くする
- 分析基盤に細かい更新を大量投入して苦しむ
という事故が起きやすくなります。
8.10.2スキーマは契約でもある
スキーマは単なる「列の一覧」ではありません。アプリケーション、分析基盤、運用ツールのあいだで交わされる契約でもあります。
つまりスキーマ変更は、
- アプリの動作
- バックフィル
- レポート
- 外部連携
にも影響します。
この見方があると、マイグレーションを「DDLを流せば終わり」と見なくなります。後方互換性、段階的移行、データ変換コストを意識できるようになります。
8.11ミニ比較表
| 概念 | 何をするか | 混同しやすいもの | 違い |
|---|---|---|---|
| 主キー | 行を一意に識別 | インデックス | 論理的な識別の中心 |
| インデックス | 検索を速くする | 主キー | 主キー以外にも作れる |
| JOIN | テーブル結合 | GROUP BY | GROUP BYは集約 |
| トランザクション | 一貫した更新単位 | 単発のSQL | 複数操作をまとめる |
| ACID | 性質 | 実装方式 | 振る舞いを表す言葉 |
8.12よくある誤解
インデックスを増やせば何でも速くなるわけではありません。検索は速くなりやすい一方で、更新や書き込みのコストは上がります。
8.13例題
【図26】SQLクエリ設計の思考プロセス:
例題1: 本のタイトルを著者名つきで出したい。books と authors が別テーブルなら何が必要か。
解説: 両者を結びつけるJOINが必要です。
例題2: ユーザーIDで頻繁に検索する列には何を検討すべきか。
解説: インデックスです。
例題3: 銀行振込のように「片方だけ成功」が困る処理では何が重要か。
解説: トランザクションです。
8.16ユースケース
ECサイト
- 商品テーブル
- 注文テーブル
- ユーザーテーブル
が関係を持ち、JOINとインデックスが重要です。
【図24-3】JOINで情報を組み合わせるイメージ:
分析基盤
- OLTPと違い、集計やスキャンが多い
- 列指向やデータウェアハウスが向くこともある
まとめ
データベースは、保存だけでなく、整合性、検索、同時実行、拡張性を支える基盤です。SQL、索引、実行計画、トランザクション、分散までを通して、設計と運用の両面で考える視点が身につきます。
参考文献
公式・標準
- MySQL Reference Manual
- PostgreSQL: Transaction Isolation
- PostgreSQL Documentation
- PostgreSQL: Concurrency Control
- PostgreSQL: EXPLAIN
- PostgreSQL: Indexes
- PostgreSQL: MVCC Introduction
- SQLite Documentation
- SQLite Query Planner
- SQLite Write-Ahead Logging
講義・記事
書籍
トランザクション分離レベルの詳細 (PostgreSQL 18.3)
PostgreSQLのトランザクション分離レベルは、SQL標準に基づく3つのレベルをサポートしています。
Read Committed(デフォルト):コミット済みデータのみを参照。クエリ開始時点のスナップショットを見る。
SET TRANSACTION ISOLATION LEVEL READ COMMITTED;
SELECT * FROM accounts WHERE balance < 0;
Repeatable Read:トランザクション開始時点のスナップショットを保持。結果整合性の異常を防止。
SET TRANSACTION ISOLATION LEVEL REPEATABLE READ;
BEGIN;
SELECT COUNT(*) FROM orders WHERE status = 'pending';
-- 他のトランザクションの変更も見えない
Serializable:最も厳密。並行実行を直列化と見なす。ダーティリード、ファントムリード、シリアライゼーション異常をすべて防止。
参考: PostgreSQL 18.3 Documentation - 13.2. Transaction Isolation では、各レベルのセマンティクスと実装詳細を解説しています。
PostgreSQLのロック機構
PostgreSQLは複数層のロック機構を提供します。
テーブルレベルロック (13.3.1 Table-Level Locks):
- ACCESS SHARE: SELECT操作で自動獲得
- ROW SHARE: FOR SHAREで獲得
- ROW EXCLUSIVE: UPDATE/DELETE時に獲得
- EXCLUSIVE: DROP TABLE等で獲得
LOCK TABLE customers IN EXCLUSIVE MODE;
-- テーブル全体の排他ロック
ALTER TABLE customers ADD COLUMN last_purchase DATE;
UNLOCK TABLE customers;
行レベルロック (13.3.2 Row-Level Locks):
- FOR UPDATE: 独占ロック
- FOR NO KEY UPDATE: 参照整合性を損なわないロック
- FOR SHARE: 共有ロック
BEGIN;
SELECT * FROM accounts WHERE id = 100 FOR UPDATE;
-- 他のトランザクションは同じ行を更新できない
UPDATE accounts SET balance = balance - 50 WHERE id = 100;
COMMIT;
アドバイザリロック (13.3.5 Advisory Locks):
- アプリケーション定義のロック機構
pg_advisory_lock()/pg_advisory_unlock()でペシミスティックロッキングをエミュレート- テーブル肥大化を避けられる
Write-Ahead Logging (WAL) と復旧
PostgreSQL 18.3では、WALが標準的なデータ整合性確保メカニズムとして機能します。
WALの基本原則:
-- WAL設定例(postgresql.conf)
wal_level = 'replica' -- レプリケーション対応WAL
max_wal_size = 4GB -- WALディレクトリサイズ制限
wal_buffers = 16MB -- WALバッファサイズ
fsync = on -- ディスクへの同期書き込み強制
参考: PostgreSQL 18.3 Documentation - 28.3. Write-Ahead Logging では、WALの仕組みと復旧手順の詳細を記載しています。
CREATEテーブル構文と制約
PostgreSQL 18.3のCREATE TABLE構文は、SQL標準に準拠しつつPostgreSQL固有の拡張機能を提供します。
基本構文:
CREATE TABLE employees (
id SERIAL PRIMARY KEY,
name VARCHAR(100) NOT NULL,
department_id INTEGER REFERENCES departments(id),
salary DECIMAL(10, 2),
hire_date DATE DEFAULT CURRENT_DATE,
CHECK (salary > 0)
);
ストレージパラメータ:
- STORAGE PLAIN: インライン保存
- STORAGE EXTENDED: TOAST圧縮対応
- COMPRESSION: LZ4/PGLZ圧縮
CREATE TABLE large_documents (
id BIGSERIAL PRIMARY KEY,
content TEXT COMPRESSION pglz,
created_at TIMESTAMP DEFAULT NOW()
);
一時テーブル:
CREATE TEMPORARY TABLE session_data (
key TEXT PRIMARY KEY,
value JSONB
);
-- セッション終了時に自動削除
参考: PostgreSQL 18.3 Documentation - CREATE TABLE では、すべてのオプションと制約タイプを解説しています。
SELECTステートメントと高度なクエリ構文
PostgreSQL 18.3のSELECT文は、WITH句(CTE)、ウィンドウ関数、FETCH句などの高度な機能をサポートしています。
Common Table Expressions (CTE):
WITH RECURSIVE employee_hierarchy AS (
SELECT id, name, manager_id, 1 AS level
FROM employees
WHERE manager_id IS NULL
UNION ALL
SELECT e.id, e.name, e.manager_id, eh.level + 1
FROM employees e
INNER JOIN employee_hierarchy eh ON e.manager_id = eh.id
)
SELECT * FROM employee_hierarchy ORDER BY level, name;
SELECT
employee_id,
salary,
AVG(salary) OVER (PARTITION BY department_id) AS dept_avg,
RANK() OVER (PARTITION BY department_id ORDER BY salary DESC) AS salary_rank
FROM employees;
FETCHとLIMIT:
SELECT * FROM orders
ORDER BY created_at DESC
FETCH FIRST 10 ROWS ONLY; -- SQL標準準拠
-- あるいは
OFFSET 20 ROWS FETCH NEXT 10 ROWS ONLY;
参考: PostgreSQL 18.3 Documentation - SELECT では、各句の詳細な仕様と使用例を記載しています。
インデックス戦略と最適化
PostgreSQL 18.3は複数のインデックス型をサポートします。
Bツリーインデックス (Chapter 11. Indexes):
CREATE INDEX idx_customers_email ON customers(email);
CREATE INDEX idx_orders_date ON orders(created_at DESC NULLS LAST);
複合インデックス:
CREATE INDEX idx_orders_status_date
ON orders(status, created_at DESC);
-- WHERE status = 'completed' ORDER BY created_at DESC に効果的
部分インデックス:
CREATE INDEX idx_active_orders
ON orders(customer_id)
WHERE status = 'active';
-- アクティブな注文のみをインデックス化
GiSTインデックス(幾何データ、全文検索):
CREATE INDEX idx_documents_fulltext
ON documents USING GiST(content);
インデックスの効果測定:
EXPLAIN ANALYZE
SELECT * FROM orders WHERE customer_id = 42 AND created_at > '2026-01-01';
データ型の詳細 (Chapter 8)
PostgreSQL 18.3は豊富なデータ型をサポートしています。
数値型:
- smallint (16-bit): -32,768 to 32,767
- integer (32-bit): -2,147,483,648 to 2,147,483,647
- bigint (64-bit): -9,223,372,036,854,775,808 to 9,223,372,036,854,775,807
- numeric/decimal: 任意精度
- real (32-bit浮動小数点)
- double precision (64-bit浮動小数点)
文字列型:
- char(n): 固定長
- varchar(n): 可変長(制限あり)
- text: 可変長(制限なし)
日時型:
- date: 日付のみ
- time: 時刻のみ(タイムゾーンなし)
- timetz: タイムゾーン付き時刻
- timestamp: タイムスタンプ(タイムゾーンなし)
- timestamptz: タイムゾーン対応
- interval: 時間間隔
CREATE TABLE events (
event_id SERIAL PRIMARY KEY,
name VARCHAR(255) NOT NULL,
scheduled_at TIMESTAMP WITH TIME ZONE,
duration INTERVAL,
location POINT, -- (x, y)
attendee_ids INTEGER[] -- 配列型
);
バックアップとリカバリ戦略
PostgreSQL 18.3のバックアップ・リカバリはWALベースで実装されています。 (Chapter 25)
pg_dumpによる論理バックアップ:
pg_dump -U postgres --format=custom --file=backup.dump mydb
pg_restore --dbname=mydb_restored backup.dump
連続アーカイビングによるポイントイン タイムリカバリ (PITR):
# postgresql.conf
wal_level = replica
archive_mode = on
archive_command = 'cp %p /backup/wal_archive/%f'
復旧手順:
- ベースバックアップの復元
- WALアーカイブからのログリプレイ
- recovery.signalで復旧開始
CMU 15-445/645による基礎知識
Carnegie Mellon Universityの「Introduction to Database Systems」では、データベース設計と実装の原理を体系的に学べます。カバー範囲:
- データモデル(リレーショナル、ドキュメント、キー値)
- ストレージモデル(N-ary、Decomposition)
- クエリ最適化とSQLコンパイル
- トランザクション制御と同時実行制御
これらは実務のPostgresSQL運用に直結する知識です。